StatefulSet的工作原理,和处理拓补状态和存储状态的方法,然后我们深入解读一下部署一个StatefulSet的完整流程
我们部署一个MySQL集群,是Kubernetes官方文档中的一个经典案例
但是难度并不低,因为相比较于Etcd等原生考虑了分布式需求的项目,MySQL在分布式上的搭建并不友好
所以我们看下如何将其集群搭建进行容器化
我们来看一下想要搭建的有状态的应用
首先是一个主从复制的MySql集群
然后有一个主节点
多个从节点
从节点支持水平扩展
所有的写操作,只在主节点上执行
我们,将上面的有状态应用的需求,通过一张图来表示
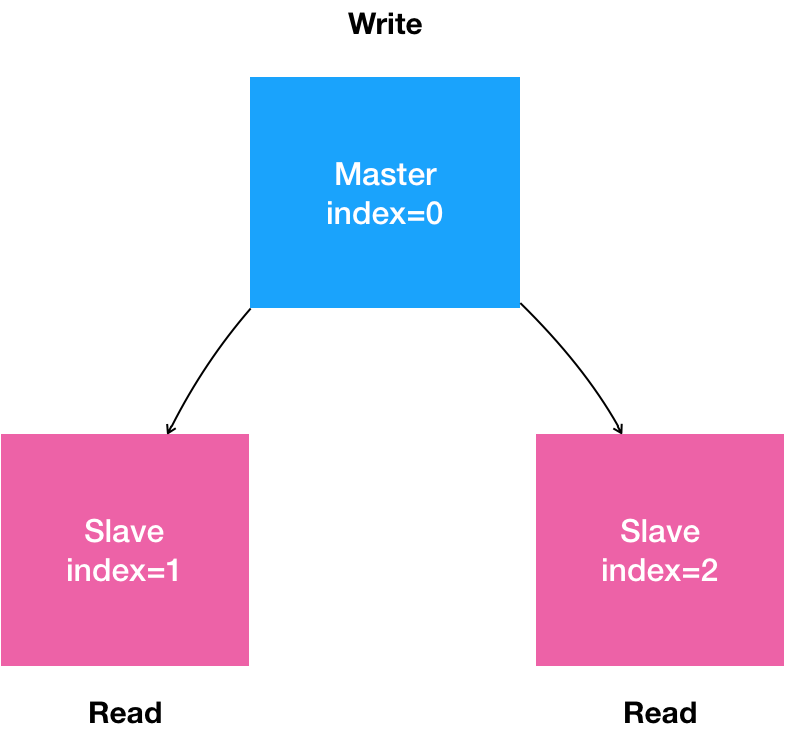
常规的环境中,布置这套环境,只需要思考配置好主从节点的复制和同步
在安装好MySql的Master节点之后,需要利用XtraBackup将Master节点的数据备份到指定目录
这会在目标目录中生成一个备份信息文件,名为xtrabackup_binlog_info,这个文件汇包含两个信息
$ cat xtrabackup_binlog_info
TheMaster-bin.000001 481
然后配置Slave节点,Slave节点在第一次启动之前,需要先将Master节点的备份数据,连同备份信息,一同拷贝到自己的数据目录下,然后执行一句SQL
TheSlave|mysql> CHANGE MASTER TO
MASTER_HOST=’$masterip’,
MASTER_USER=’xxx’,
MASTER_PASSWORD=’xxx’,
MASTER_LOG_FILE=’TheMaster-bin.000001′,
MASTER_LOG_POS=481;
然后启动Slave节点
TheSlave|mysql> START SLAVE;
接下来,可以往这个集群中添加更多的Slave节点
接下来,我们将Slave节点的数据备份指定在一个目录,生成额外的备份信息,名为
xtrabackup_slave_info,这两个文件也包含了MASTER_LOG_FILE和MASTER_LOG_POS
两个字段
然后就可以执行如前面的两个SQL
开始启动和初始化新的SLAVE节点了
这样,部署过程中,会存在着一些难点
1.Master节点和Slave节点需要由不同的配置文件,来区分对应的节点信息
2.Master节点和Slave需要进行备份文件的交换
3.在Slave第一次启动之前,需要执行一些初始化的SQL操作
因为MySQL具有拓补的状态,所以需要通过StatefulSet来解决这三座大山的问题
第一座大山,Master节点和Slave节点需要有不同的配置文件,很容易处理,需要给主从节点准备不同的MySql配置文件,根据Pod的编号进行挂载即可
我们可以使用ConfigMap来进行相关的配置
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# 主节点MySQL的配置文件
[mysqld]
log-bin
slave.cnf: |
# 从节点MySQL的配置文件
[mysqld]
super-read-only
我们分别定义了master.cnf和slave.cnf两个MySQL的配置文件
master.cnf开启了log-bin,使用二进制日志文件的方式进行主从复制,这是一个标准的设置
slave.cnf开启了super-read-only,从节点会拒绝除了主节点数据同步之外的所有写操作,对用户是只读的
这是ConfigMap的data部分,是key-value的,master.cnf就是这个配置文件的key,而|后面二代内容,就这个配置文件的Vlaue,这个数据将来挂载进Master节点对应的Pod后,就会在Volume目录里生成一个master.cnf的文件
然后我们创建两个Service来供StatefulSet使用
分别定义如下
| apiVersion: v1
kind: Service metadata: name: mysql labels: app: mysql spec: ports: – name: mysql port: 3306 clusterIP: None selector: app: mysql — apiVersion: v1 kind: Service metadata: name: mysql-read labels: app: mysql spec: ports: – name: mysql port: 3306 selector: app: mysql |
这两个Service都带了app=mysql标签的Pod,就是所有的mysql pod,端口映射都是对应的por的3306端口
不过第一个mysql的service是一个Headless Service,作用是,通过Pod分配DNS来固定拓补装填,比如mysql-0.mysql和mysql-1.mysql,这样的DNS名字,其中编号0就是主节点
然后mysql-read就是一个普通的Service,会将访问这个DNS的请求转发到任何一个Mysql的主从节点上
所有用户的写请求,通过第一个DNS来寻找mysql-0的DNS记录
然后看第二个问题
Master和Slave节点的传输问题
我们需要定义一个标准的Mysql主从节点的StatuefulSet框架
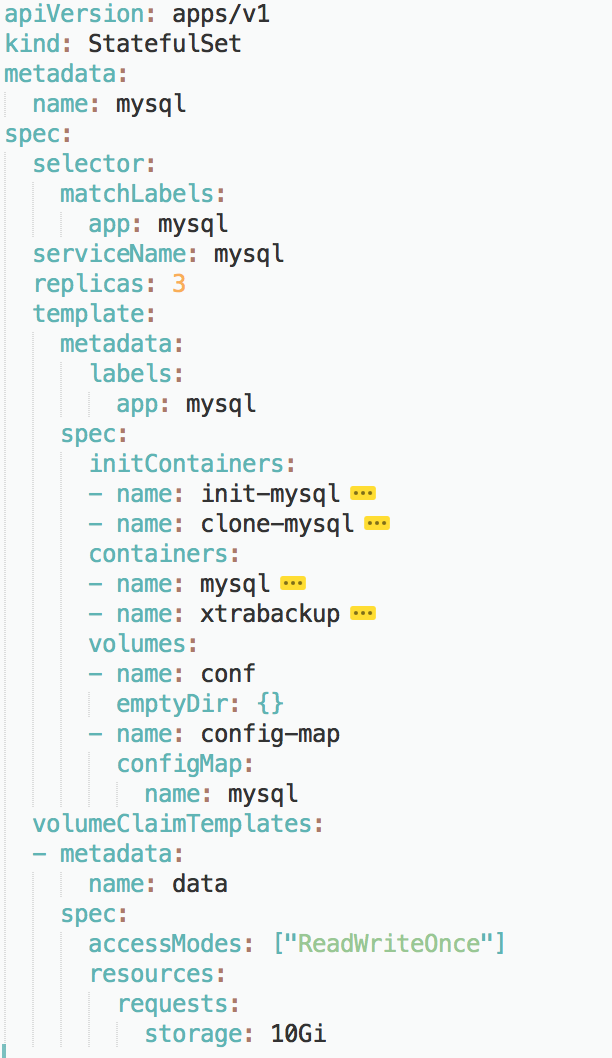
如上所示
我们先定义了一些通用的字段,比如selector表示,这个StatefulSet表示Pod必须要带着app=mysql的标签,使用的Headless Service的名字是mysql
StatefulSet的replicas的值是3,表示mysql集群有三个节点,一个Master节点,两个Slave节点
StatefulSet管理的有状态应用是利用了同一份Pod模板创建出来的,使用的是同一个镜像,如果需要不同节点不同的镜像,先别考虑StatefulSet了
除了这些基本的字段外,作为一个由存储状态的MySql集群,还需要考虑存储状态,我们需要定义PVC模板,来给每一个Pod分配指定的硬盘空间,比如PVC的resources.request.strorage指定存储的大小为10GB,并且声明了ReadWriteOnce
然后是对应的Pod模板 template字段
由于StatefulSet管理的Pod需要来自同一个镜像,于是我们编写Pod的时候,需要分别思考不同的情况
Pod是Master节点该怎么办
Pod是Slave节点,该怎么办
首先说,由于StatefulSet的Pod模板中声明了Service,保证了启动的顺序
所以我们编写一个initContainer来利用容器的启动序号来进行不同节点的启动
| …
# template.spec initContainers: – name: init-mysql image: mysql:5.7 command: – bash – “-c” – | set -ex # 从Pod的序号,生成server-id [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} echo [mysqld] > /mnt/conf.d/server-id.cnf # 由于server-id=0有特殊含义,我们给ID加一个100来避开它 echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf # 如果Pod序号是0,说明它是Master节点,从ConfigMap里把Master的配置文件拷贝到/mnt/conf.d/目录; # 否则,拷贝Slave的配置文件 if [[ $ordinal -eq 0 ]]; then cp /mnt/config-map/master.cnf /mnt/conf.d/ else cp /mnt/config-map/slave.cnf /mnt/conf.d/ fi volumeMounts: – name: conf mountPath: /mnt/conf.d – name: config-map mountPath: /mnt/config-map |
通过这个名为init-mysql的initContainer容器,从Pod的hostname里面,读取到了Pod的序号,并以此作为MySQL的Server-id
然后init通过这个序号,判定是否是Master节点,并且,生成了对应的server-id.cnf
然后根据序号,拷贝不同的conf.d
文件拷贝的源目录/mnt/config-map
正是挂载了Config-map的的Volume
conf则是自己自动生成的空目录
然后,在Slave Pod启动前,从Master或者Slave Pod中拷贝数据库数据在自己的目录下
为了实现这个操作,需要定义第二个initContainer
| …
# template.spec.initContainers – name: clone-mysql image: gcr.io/google-samples/xtrabackup:1.0 command: – bash – “-c” – | set -ex # 拷贝操作只需要在第一次启动时进行,所以如果数据已经存在,跳过 [[ -d /var/lib/mysql/mysql ]] && exit 0 # Master节点(序号为0)不需要做这个操作 [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} [[ $ordinal -eq 0 ]] && exit 0 # 使用ncat指令,远程地从前一个节点拷贝数据到本地 ncat –recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql # 执行–prepare,这样拷贝来的数据就可以用作恢复了 xtrabackup –prepare –target-dir=/var/lib/mysql volumeMounts: – name: data mountPath: /var/lib/mysql subPath: mysql – name: conf mountPath: /etc/mysql/conf.d |
在这个镜像中,我们使用xtrabackup的镜像,安装了xtrabackup镜像
在其中,我们进行了一个判断,当初始化的数据已经存在的时候,或者自己是Mater节点,就不需要进行拷贝操作
接下来拉取对应的备份数据
然后我们进行拷贝到本地的/mysql节点,这个节点实际上一个名为data的PVC,也是我们声明的持久化存储
利用这里面的数据进行恢复操作
不过clone-mysql容器还要对/var/lib/mysql目录进行一个xtrabackup –prepare操作,来让拷贝来的数据进入一致性状态
这样,就通过InitContainer完成了对主 从 节点备份文件传输的操作处理过程
然后我们要启动这个MySQL
只不过在启动Slave节点之前,我们需要利用拷贝来的数据进行初始化
如何进行初始化呢?
这就是第三座大山,在第一次启动之前,执行初始化SQL
我们可以额外定义一个sidecar容器,完成这个操作
| …
# template.spec.containers – name: xtrabackup image: gcr.io/google-samples/xtrabackup:1.0 ports: – name: xtrabackup containerPort: 3307 command: – bash – “-c” – | set -ex cd /var/lib/mysql # 从备份信息文件里读取MASTER_LOG_FILEM和MASTER_LOG_POS这两个字段的值,用来拼装集群初始化SQL if [[ -f xtrabackup_slave_info ]]; then # 如果xtrabackup_slave_info文件存在,说明这个备份数据来自于另一个Slave节点。这种情况下,XtraBackup工具在备份的时候,就已经在这个文件里自动生成了”CHANGE MASTER TO” SQL语句。所以,我们只需要把这个文件重命名为change_master_to.sql.in,后面直接使用即可 mv xtrabackup_slave_info change_master_to.sql.in # 所以,也就用不着xtrabackup_binlog_info了 rm -f xtrabackup_binlog_info elif [[ -f xtrabackup_binlog_info ]]; then # 如果只存在xtrabackup_binlog_inf文件,那说明备份来自于Master节点,我们就需要解析这个备份信息文件,读取所需的两个字段的值 [[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1 rm xtrabackup_binlog_info # 把两个字段的值拼装成SQL,写入change_master_to.sql.in文件 echo “CHANGE MASTER TO MASTER_LOG_FILE=’${BASH_REMATCH[1]}’,\ MASTER_LOG_POS=${BASH_REMATCH[2]}” > change_master_to.sql.in fi # 如果change_master_to.sql.in,就意味着需要做集群初始化工作 if [[ -f change_master_to.sql.in ]]; then # 但一定要先等MySQL容器启动之后才能进行下一步连接MySQL的操作 echo “Waiting for mysqld to be ready (accepting connections)” until mysql -h 127.0.0.1 -e “SELECT 1”; do sleep 1; done echo “Initializing replication from clone position” # 将文件change_master_to.sql.in改个名字,防止这个Container重启的时候,因为又找到了change_master_to.sql.in,从而重复执行一遍这个初始化流程 mv change_master_to.sql.in change_master_to.sql.orig # 使用change_master_to.sql.orig的内容,也是就是前面拼装的SQL,组成一个完整的初始化和启动Slave的SQL语句 mysql -h 127.0.0.1 <<EOF $(<change_master_to.sql.orig), MASTER_HOST=’mysql-0.mysql’, MASTER_USER=’root’, MASTER_PASSWORD=”, MASTER_CONNECT_RETRY=10; START SLAVE; EOF fi # 使用ncat监听3307端口。它的作用是,在收到传输请求的时候,直接执行”xtrabackup –backup”命令,备份MySQL的数据并发送给请求者 exec ncat –listen –keep-open –send-only –max-conns=1 3307 -c \ “xtrabackup –backup –slave-info –stream=xbstream –host=127.0.0.1 –user=root” volumeMounts: – name: data mountPath: /var/lib/mysql subPath: mysql – name: conf mountPath: /etc/mysql/conf.d |
第一部分,mysql的初始化工作,需要将sql保存在一个名为change_master_to.sql.in文件里面
sidecar在保存之前,看自己的/var/lib/mysql目录下,是否有xtrabackup_slave_info这个备份信息
如果有,说明是一个Slave节点上的备份信息,这时候XtraBackup已经在这个文件中自动生成了CHANGE MASTER TO SQL语句,我们只需要重命名一下即可
如果没有xtrabackup_slave_info文件,但是存在xtrabackup_binlong_info文件,说明备份数据来自于Master节点,这时候,sidecar容器需要解析这个备份信息文件,读取MASTER_LOG_FILE和MASTER_LOG_POS这两个字段的值,拼出初始化SQL语句,写入到change_master_to.sql.in文件中
然后只要有这个change_master_to_sql.in的文件的存在,就需要进行集群初始化的操作
这时候sidecar容器需要读取并执行change_master_to.sql.in里面的CHANGE MASTER TO 指令
在执行一句START SLAVE命令,一个SLAVE节点就被启动成功了
Pod中的容器并没有先后顺序,在执行初始化SQL之前,需要执行下select 1来检查MySQL服务是否可用
然后我们需要删除掉之前的备份信息文件,包括我们拼出来的change_master_to.sql.in,避免下次容器重启后,发现文件存在,重新执行一次数据恢复和集群初始化的操作
然后sidecar容器执行了开启了一个数据传输服务
sidecar容器会启动ncat命令启动一个工作在3307端口上的网络传输服务,方便传递xtrabackup –backup指令备份当前MySQL数据,然后给请求者
这样就解决了第三个大山
完成了Slave节点第一次启动前的初始化工作
最后,我们定义一下Pod中的MySQL容器,MySQL半身的定义不难
| …
# template.spec containers: – name: mysql image: mysql:5.7 env: – name: MYSQL_ALLOW_EMPTY_PASSWORD value: “1” ports: – name: mysql containerPort: 3306 volumeMounts: – name: data mountPath: /var/lib/mysql subPath: mysql – name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 500m memory: 1Gi livenessProbe: exec: command: [“mysqladmin”, “ping”] initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 readinessProbe: exec: # 通过TCP连接的方式进行健康检查 command: [“mysql”, “-h”, “127.0.0.1”, “-e”, “SELECT 1”] initialDelaySeconds: 5 periodSeconds: 2 timeoutSeconds: 1 |
我们使用了一个标准的MySQL5.7的镜像,数据目录为默认的/var/lib/mysql
配置文件目录则是/etc/mysql/conf.d
基本的volumes已经给其定义好了
然后,还定义了一个livenessProbe,通过mysqladmin ping命令检查是否健康
然后利用一个readinessProbe来查询SQL select 1检查MySQL服务是否可用,凡事readiness Probe检查失败的MySQL Pod,都会被摘除掉
一个完整的主从复制模式mysql集群基本定义完了
我们使用kubectl 运行一下这个StatefulSet
只需要在Kubernetes集群中创建对应的PV,方便去获取存储空间
比如使用Rook
| $ kubectl create -f rook-storage.yaml
$ cat rook-storage.yaml apiVersion: ceph.rook.io/v1beta1 kind: Pool metadata: name: replicapool namespace: rook-ceph spec: replicated: size: 3 — apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-ceph-block provisioner: ceph.rook.io/block parameters: pool: replicapool clusterNamespace: rook-ceph |
storageClass会自动为每一个PVC创建对应的PV
配合的,要使用这个storageClass,需要在mysql-statefulset.yaml中声明
storageClassName=rook-ceph-block
才能使用这个Rook提供的持久化存储
这样,我们就可以创建这个StatefulSet了
kubectl create -f mysql-statefulSet,yaml
kubectl get pod -l app=mysql
这样,StatefulSet启动后,会有三个Pod运行
然后可以尝试着向这个MySql集群发起请求,执行一些SQL操作来检测是否正常
kubectl run mysql-client –image=mysql:1.5.7 -i –rm –restart=Never –\
mysql -h mysql-0.mysql <<EOF
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.message VALUES(‘hello’)
EOF
这样,我们连接上0节点的mysql,然后执行了创建数据库表的操作,并插入了一条数据
这样,我们连接上从节点,从从节点上进行读取操作
$ kubectl run mysql-client –image=mysql:5.7 -i -t –rm –restart=Never –\
mysql -h mysql-read -e “SELECT * FROM test.messages”
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+———+
| message |
+———+
| hello |
+———+
pod “mysql-client” deleted
而且,我们还能再次基础上,扩展我们的Mysql
kubectl scale statefulset mysql –replicas=5
这样,新的Slave Pod mysql-3和mysql-4就出现了
而且,直接连接mysql-3,能看到我之前的操作
$ kubectl run mysql-client –image=mysql:5.7 -i -t –rm –restart=Never –\
mysql -h mysql-3.mysql -e “SELECT * FROM test.messages”
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+———+
| message |
+———+
| hello |
+———+
pod “mysql-client” deleted
这样,新创建的mysql-3,也能读取到之前的插入记录,数据备份和恢复,都是有效的
今天的文章中,我们以MySQL集群为例,分享了一个实际的StatefulSet的编写过程,对应的完整的YAML文件
| apiVersion: apps/v1beta2
kind: StatefulSet metadata: name: mysql spec: selector: matchLabels: app: mysql serviceName: mysql replicas: 3 template: metadata: labels: app: mysql spec: initContainers: – name: init-mysql image: mysql:5.7 command: – bash – “-c” – | set -ex # Generate mysql server-id from pod ordinal index. [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} echo [mysqld] > /mnt/conf.d/server-id.cnf # Add an offset to avoid reserved server-id=0 value. echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf # Copy appropriate conf.d files from config-map to emptyDir. if [[ $ordinal -eq 0 ]]; then cp /mnt/config-map/master.cnf /mnt/conf.d/ else cp /mnt/config-map/slave.cnf /mnt/conf.d/ fi volumeMounts: – name: conf mountPath: /mnt/conf.d – name: config-map mountPath: /mnt/config-map – name: clone-mysql image: gcr.io/google-samples/xtrabackup:1.0 command: – bash – “-c” – | set -ex # Skip the clone if data already exists. [[ -d /var/lib/mysql/mysql ]] && exit 0 # Skip the clone on master (ordinal index 0). [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} [[ $ordinal -eq 0 ]] && exit 0 # Clone data from previous peer. ncat –recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql # Prepare the backup. xtrabackup –prepare –target-dir=/var/lib/mysql volumeMounts: – name: data mountPath: /var/lib/mysql subPath: mysql – name: conf mountPath: /etc/mysql/conf.d containers: – name: mysql image: mysql:5.7 env: – name: MYSQL_ALLOW_EMPTY_PASSWORD value: “1” ports: – name: mysql containerPort: 3306 volumeMounts: – name: data mountPath: /var/lib/mysql subPath: mysql – name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 500m memory: 1Gi livenessProbe: exec: command: [“mysqladmin”, “ping”] initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 readinessProbe: exec: # Check we can execute queries over TCP (skip-networking is off). command: [“mysql”, “-h”, “127.0.0.1”, “-e”, “SELECT 1”] initialDelaySeconds: 5 periodSeconds: 2 timeoutSeconds: 1 – name: xtrabackup image: gcr.io/google-samples/xtrabackup:1.0 ports: – name: xtrabackup containerPort: 3307 command: – bash – “-c” – | set -ex cd /var/lib/mysql # Determine binlog position of cloned data, if any. if [[ -f xtrabackup_slave_info ]]; then # XtraBackup already generated a partial “CHANGE MASTER TO” query # because we’re cloning from an existing slave. mv xtrabackup_slave_info change_master_to.sql.in # Ignore xtrabackup_binlog_info in this case (it’s useless). rm -f xtrabackup_binlog_info elif [[ -f xtrabackup_binlog_info ]]; then # We’re cloning directly from master. Parse binlog position. [[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1 rm xtrabackup_binlog_info echo “CHANGE MASTER TO MASTER_LOG_FILE=’${BASH_REMATCH[1]}’,\ MASTER_LOG_POS=${BASH_REMATCH[2]}” > change_master_to.sql.in fi # Check if we need to complete a clone by starting replication. if [[ -f change_master_to.sql.in ]]; then echo “Waiting for mysqld to be ready (accepting connections)” until mysql -h 127.0.0.1 -e “SELECT 1”; do sleep 1; done echo “Initializing replication from clone position” # In case of container restart, attempt this at-most-once. mv change_master_to.sql.in change_master_to.sql.orig mysql -h 127.0.0.1 <<EOF $(<change_master_to.sql.orig), MASTER_HOST=’mysql-0.mysql’, MASTER_USER=’root’, MASTER_PASSWORD=”, MASTER_CONNECT_RETRY=10; START SLAVE; EOF fi # Start a server to send backups when requested by peers. exec ncat –listen –keep-open –send-only –max-conns=1 3307 -c \ “xtrabackup –backup –slave-info –stream=xbstream –host=127.0.0.1 –user=root” volumeMounts: – name: data mountPath: /var/lib/mysql subPath: mysql – name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 100m memory: 100Mi volumes: – name: conf emptyDir: {} – name: config-map configMap: name: mysql volumeClaimTemplates: – metadata: name: data spec: accessModes: [“ReadWriteOnce”] resources: requests: storage: 10Gi |
在编写这个YAML中,有几个关键的点
首先在编写的时候,需要针对Pod在整个集群中的不同角色来书写不同的配置和操作
然后需要区分容器重启和容器启动两个不同操作带来的后果
对于需要启动之前的操作,使用initContainer,对于启动后的额外操作,使用sidecar容器
StatefulSet在Deploement的基础上,固定了Pod的拓补关系,固定了Pod的访问方式,保证了PV和Pod对应关系,在Pod删除重建的时候,这些状态都保持不变
但是只能使用相同的镜像去在StatefulSet中使用,如果想要管理不同的应用,可能需要的是Operator
对于上面的StatefulSet来说,其实做成两个statefulSet来处理,会简单一些
所有的读请求,只由 Slave 节点处理;所有的写请求,只由 Master 节点处理。那么,你需要在今天这篇文章的基础上再做哪些改动呢?
对于课后问题来说,我们可以利用重新划分Service的方式来实现
给主节点划分一个mysql-master的service来保证绑定每次访问指访问主节点
将mysql-read改为绑定所有的从节点,就是不知道这样能不能走得通,不行的话,就将主节点和从节点划分为两个StatefulSet