从0开始搭建一个完整的Kubernetes集群
我们利用Kubernetes来搭建一个完整的Kubernetes集群
这里的完整,指的是这个集群具备一个完整的Kubernetes项目的所有功能,模拟生产环境所有需求,但是并不代表这个集群是生成级别可用的,类似高可用,授权,多租户,灾难备份等生产级别集群的功能暂时不说
首先准备需要的机器
1.满足安装Docker项目所需的要求,是64位的Linux操作系统
2.x86或者ARM架构
3.网络互通
4.主机有外网权限
5.单机2核4G以上
5.30G的可用磁盘
我们的实践目标是
所有的节点安装Docker和kubeadm
部署Kubernetes Master
部署网络插件
部署Kubernetes Worker
部署Dashboard可视化插件
部署容器存储插件
首先关闭swap分区
sudo swapoff -a
我们需要添加kubeadm的源,可以使用apt-get安装
| $ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add –
$ cat <<EOF > /etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF $ apt-get update $ apt-get install -y docker.io kubeadm |
如果apt.kubernetes.io网络不行,可以考虑Ubuntu镜像源deb
http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main
或者使用kubernetes yum源进行安装
首先添加对应的repo文件
[kubernetes]
name=kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgcheck=0
enable=1
添加到/etc/yum.repos.d目录下
然后进行
yum clean all
yum repolist
分别安装kubeadm
yum install docker-ce
yum install kubelet-1.11.1
yum install kubeadm-1.11.1
yum install kubectl-1.11.1
yum install kubernetes-cni
确保都是1.11.1版本的
systemctl enable docker
systemctl enable kubectl.service
systemctl start docker
systemctl start kubectl.service
在利用systemctl status kubectl.service的时候,会发现其启动失败了
journalctl查看错误信息
原因是因为没有kubeadm init
这样我们进行init 操作
我们利用kubeadm来进行一键部署Master节点
我们就给kubeadm编写了一个对应的init的YAML
| apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration controllerManagerExtraArgs: horizontal-pod-autoscaler-use-rest-clients: “true” horizontal-pod-autoscaler-sync-period: “10s” node-monitor-grace-period: “10s” apiServerExtraArgs: runtime-config: “api/all=true” kubernetesVersion: “stable-1.11” |
最后我们指定了kubernetesVersion为1.11,不过我写为了kubernetesVersion:v1.11.1
而且由于我们无法在国内连入谷歌的镜像仓库
我们可以借助国内的镜像仓库,来进行相关的镜像拉取
借助一个shell脚本,来进行拉取
vim pullimages.sh
#!/bin/bash
images=(kube-proxy-amd64:v1.11.1 kube-scheduler-amd64:v1.11.1 kube-controller-manager-amd64:v1.11.1
kube-apiserver-amd64:v1.11.1 etcd-amd64:3.2.18 coredns:1.1.3 pause:3.1 )
for imageName in ${images[@]} ; do
docker pull anjia0532/google-containers.$imageName
docker tag anjia0532/google-containers.$imageName k8s.gcr.io/$imageName
docker rmi anjia0532/google-containers.$imageName
done
bash pullimages.sh
拉取完成后,就可以进行master节点的init操作了
kubeadm init –config kubeadm.yaml
这就是Master节点的部署流程,整体的部署流程完成后,就会生成一个行指令
kubeadm join 10.152.240.112:6443 –token f0m0tr.qto4au6bp15l5l47 –discovery-token-ca-cert-hash sha256:75686062786ad9e7b83fa0a93850a4458e271005e2bd823a2d877a234df1e4d2
这样我们就配好了Master节点
然后,kubeadm还会提醒我们进行集群相关的配置命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
这些配置的命令,是Kubernetes集群默认需要加密访问,我们将加密相关的配置文件,保存在目录的.kube目录下,然后kubectl会默认使用这个目录下的授权信息去访问Kubernetes集群
如果不这么做,每次都需要export KUBECONFIG,来告诉kubectl的安全配置文件位置
然后利用kubectl get来查看唯一的一个节点
![]()
Master节点的状态是NotReady,这是为何?
在调试Kubernetes集群的时候,最重要的就是kubectl describe来查看这个节点的详细信息,状态和事件,我们看一下
| kubectl describe node dev-code2
Name: dev-code2 Roles: master Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/hostname=dev-code2 node-role.kubernetes.io/master= Annotations: kubeadm.alpha.kubernetes.io/cri-socket=/var/run/dockershim.sock node.alpha.kubernetes.io/ttl=0 volumes.kubernetes.io/controller-managed-attach-detach=true CreationTimestamp: Wed, 02 Sep 2020 15:25:00 +0800 Taints: node-role.kubernetes.io/master:NoSchedule Unschedulable: false Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message —- —— —————– —————— —— ——- OutOfDisk Unknown Wed, 02 Sep 2020 16:38:01 +0800 Wed, 02 Sep 2020 16:37:58 +0800 NodeStatusUnknown Kubelet stopped posting node status. MemoryPressure Unknown Wed, 02 Sep 2020 16:38:01 +0800 Wed, 02 Sep 2020 16:37:58 +0800 NodeStatusUnknown Kubelet stopped posting node status. DiskPressure Unknown Wed, 02 Sep 2020 16:38:01 +0800 Wed, 02 Sep 2020 16:37:58 +0800 NodeStatusUnknown Kubelet stopped posting node status. PIDPressure False Wed, 02 Sep 2020 16:38:01 +0800 Wed, 02 Sep 2020 15:25:00 +0800 KubeletHasSufficientPID kubelet has sufficient PID available Ready Unknown Wed, 02 Sep 2020 16:38:01 +0800 Wed, 02 Sep 2020 16:37:58 +0800 NodeStatusUnknown Kubelet stopped posting node status. Addresses: InternalIP: 10.152.240.112 Hostname: dev-code2 Capacity: cpu: 4 ephemeral-storage: 51175Mi hugepages-2Mi: 0 memory: 8009204Ki pods: 110 Allocatable: cpu: 4 ephemeral-storage: 48294789041 hugepages-2Mi: 0 memory: 7906804Ki pods: 110 System Info: Machine ID: 5d63f0cbd9934b7691f8249d2f157602 System UUID: 258F4D56-1E72-8D61-D1E8-96E117945DD1 Boot ID: ed1a4ca5-76ec-48e4-8693-332adad577bd Kernel Version: 3.10.0-957.el7.x86_64 OS Image: CentOS Linux 7 (Core) Operating System: linux Architecture: amd64 Container Runtime Version: docker://18.3.1 Kubelet Version: v1.11.1 Kube-Proxy Version: v1.11.1 Non-terminated Pods: (5 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits ——— —- ———— ———- ————— ————- kube-system etcd-dev-code2 0 (0%) 0 (0%) 0 (0%) 0 (0%) kube-system kube-apiserver-dev-code2 250m (6%) 0 (0%) 0 (0%) 0 (0%) kube-system kube-controller-manager-dev-code2 200m (5%) 0 (0%) 0 (0%) 0 (0%) kube-system kube-proxy-bj826 0 (0%) 0 (0%) 0 (0%) 0 (0%) kube-system kube-scheduler-dev-code2 100m (2%) 0 (0%) 0 (0%) 0 (0%) Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits ——– ——– —— cpu 550m (13%) 0 (0%) memory 0 (0%) 0 (0%) Events: Type Reason Age From Message —- —— —- —- ——- Normal NodeHasSufficientMemory 14m (x58 over 1h) kubelet, dev-code2 Node dev-code2 status is now: NodeHasSufficientMemory Normal NodeHasSufficientDisk 3m (x67 over 1h) kubelet, dev-code2 Node dev-code2 status is now: NodeHasSufficientDisk |
因为没有网络插件,所以没法Ready
我们又通过kubectl检查这个节点各个系统Pod的状态,其中kube-system是Kubernetes项目预留的系统Pod的状态,
我们看下主节点相关的Pod的状态都是Pending的状态,就是调度失败的,这是因为Master节点的网络尚未准备就绪
| kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE coredns-78fcdf6894-85mpn 0/1 Pending 0 1h coredns-78fcdf6894-kjtmt 0/1 Pending 0 1h etcd-dev-code2 1/1 Running 0 1h kube-apiserver-dev-code2 1/1 Running 0 1h kube-controller-manager-dev-code2 1/1 Running 0 1h kube-proxy-bj826 1/1 Running 0 1h kube-scheduler-dev-code2 1/1 Running 0 1h |
我们进行网络插件的部署
我们部署网络插件相当简单,kubectl apply,我们利用这个命令部署Weave
kubectl apply -f https://git.io/weave-kube-1.6
这时候在看节点的信息
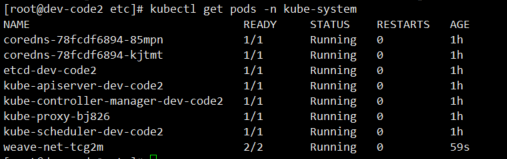
发现已经都启动起来了
刚刚的部署,在kube-system下面启动了一个weave-net-tcg2m的节点
这就是网络插件
Kubernetes支持网络插件,使用的是CNI的通用接口,是容器网络的事实标准,所有容器开源项目通过CNI接入Kubernetes,比如Flannel,Calico,Canal,Romana等,都是利用这个接口接入的
部署完了Master节点,在尝试在Master节点上运行用户Pod之前,我们先部署Worker节点
直接使用join指令
kubeadm join 10.152.240.112:6443 –token f0m0tr.qto4au6bp15l5l47 –discovery-token-ca-cert-hash sha256:75686062786ad9e7b83fa0a93850a4458e271005e2bd823a2d877a234df1e4d2
最后我们说一下如何在Master节点上执行Pod策略
而Kubernetes做到这一点,依靠的是Kubernetes的Taint/Toleration机制
污点机制,一个节点被打上了Taint,就被打上了污点,所有的Pod就不能在这个节点上运行
除非个别Pod声明自己能够容忍这个污点,声明了Toleration,才能在这个节点上运行
为一个节点打上污点的命令是
Kubectl taint nodes nodel foo=bar:Noschedule
这个node1节点上,就会增加一个键值对的Taint
foo=bar:NoSchedule,其中的NoSchedule,意味着这个Taint只会在调度新的Pod的时候使用,对已经存在的Pod,没有任何影响
那么Pod如何声明自己能容忍Toleration呢?
只要在Pod的yaml文件的spec部分,加入tolerations字段即可
| apiVersion: v1
kind: Pod … spec: tolerations: – key: “foo” operator: “Equal” value: “bar” effect: “NoSchedule” |
整体的配置含义是,Pod能够容忍键值对为foo=bar的Taint,operator的含义是 Equal,表示等于操作
这时候我们回到搭建好的集群上,可以通过kubectl describe检查主节点的Taint字段
| $ kubectl describe node master
Name: master Roles: master Taints: node-role.kubernetes.io/master:NoSchedule |
Master节点被默认加上了node-role.kubernetes.io/master:NoSchedule这样的污点,这个污点只有key,没有value
如果直接声明Pod在此节点上运行,可以直接使用Exists操作符,书写的yaml文件如下
| apiVersion: v1
kind: Pod … spec: tolerations: – key: “foo” operator: “Exists” effect: “NoSchedule” |
使用Exists操作符即可,说明只要存在key就行
当然,最简单的方式,就是直接删除这个Taint
kubectl taint nodes –all node-role.kuberntes.io/master-
这后面加上了一个 短横线 -,就意味着移除了所有node-role.kuberntes.io/master的Taint
这样就是一个简单的Kubernetes集群的搭建,有了这个原生的管理工具,我们就基本搭建了一个完全可用的Kubernetes,接下来是一下辅助性质的插件
Dashborad和远程存储
部署Dashboard
这是一个可以提供可视化Web界面的插件,对于可以直接连上谷歌镜像仓库,部署非常简单,直接
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc6/aio/deploy/recommended.yaml
但是对于国内用户,我们还是得考虑自定义镜像的方式去拉推镜像
wget https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
拉取不到,可以考虑直接编写kubernetes-dashboard.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
– port: 443
targetPort: 8443
nodePort: 30001
selector:
k8s-app: kubernetes-dashboard
然后进行拉取国内的镜像源
docker pull anjia0532/google-containers.kubernetes-dashboard-amd64:v1.10.0
docker tag anjia0532/google-containers.kubernetes-dashboard-amd64:v1.10.0 k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.0
docker rmi anjia0532/google-containers.kubernetes-dashboard-amd64:v1.10.0
然后直接
kubectl apply -f kubernetes-dashboard.yaml
查看对应的Pods状态
最后部署一下容器的持久化存储
我们需要用数据卷 volume,将外部宿主机的目录或者文件挂载到容器的Mount Namesapce中,达到容器和宿主机共享这些目录或者文件的目的,容器的应用,也就是可以再这些数据卷内新建和写入文件
可是一台机器上启动的一个容器,无法看到其他机器上的容器在数据卷中写入的文件,这就是容器的无状态性
容器的持久化存储,是保存容器状态的重要手段,可以考虑在容器内挂载一个基于网络或者其他机制的远程数据卷,以分布式的方式保存在多个节点上,和当前的宿主机没有任何的绑定,这样,无论在哪个宿主机上启动了新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷内的内容,这就是持久化的含义
由于Kubernetes的松耦合的设计,绝大数存储项目,NFS Ceph,都可以为Kubernetes提供持久化存储能力,这次我们部署Rook
Rook其基于Cepth,不过不同于Ceph的简单封装,Rook在自己的实现中加入了水平扩展,迁移,灾难备份,监控等企业级功能,非常牛皮,其利用了很多诸如Operator,CRD等重要扩展特性,使得其变成了目前社区中基于Kuberntes API构建最完善最成熟容器存储插件
部署的方式,很简单,
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/common.yaml
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/cluster.yaml
部署完成后,可以看到Rook项目将自己的Pod放在自己管理的两个Namespace中
| $ kubectl get pods -n rook-ceph-system
NAME READY STATUS RESTARTS AGE rook-ceph-agent-7cv62 1/1 Running 0 15s rook-ceph-operator-78d498c68c-7fj72 1/1 Running 0 44s rook-discover-2ctcv 1/1 Running 0 15s $ kubectl get pods -n rook-ceph NAME READY STATUS RESTARTS AGE rook-ceph-mon0-kxnzh 1/1 Running 0 13s rook-ceph-mon1-7dn2t 1/1 Running 0 2s |
这样,在Kubernetes上创建的所有Pod都可以通过Persisent Volume PV和 Persistent Volume Claim PVC的方式,在容器中挂载Ceph提供的数据卷
而Rook项目,会负责将这些数据的生命周期管理,灾难备份等运维
其实Kuberetes原生,约等于 云原生这个概念,像是Rook Istio这样的项目,就是这个思路的典范
在本章中,我们从0开始,在Bare-metal环境下使用kubeadm部署了一个完整的kubernetes集群,这个集群,并使用Weave作为容器网络插件,Rook作为容器持久化存储插件,Dashboard插件提供了可视化的Web界面
整个集群的部署过程,靠着Kubeadm,提供的配置证书,二进制文件的准备,集群版本的管理,简化了不少
然后基于万物皆容器的思想,加上良好的扩展机制,插件的部署非常简便,只需要部署一个kubectl即可
我们接下来在部署的时候考虑,工作是否可以容器化
工作是否可以借助kubernetes API和可扩展机制来完成
那么两个思考题
1.其他的工具部署过Kubernetes吗?
2.kubernetes能够有效管理多少个节点
2.对于集群来说,我们将整个集群认为是一个大型的工作节点,那么集群内的可以分为多少个节点首先取决于集群的性能之和,比如我们的性能之和是32个CPU,128G内存,那么可以分为8个 4核16G的节点