我们说了Docker项目到Linux容器的具体实现方式,一个容器,实际上由着Linux Namesapce Linux Cgroup rootfs三种技术实现的一个进程隔离环境供进程使用
那么我们看得出一个Linux容器,可以被看为两个部分
一部分是rootfs,容器的静态视图
另一部分,是Namespace+Cgroups构成的隔离环境,这一部分是容器运行时,是容器的动态视图
但是,只是运行了一个容器并不够,还需要进行容器编排,因为一个容器可以作为Docker镜像被运行起来,就能在整体的一个技术生态上作为一个承载点,将整个容器技术栈上的价值,沉淀在节点上
这样,就是容器编排的价值
我们先不说 Docker的Compose+Swarm是如何实现的,主要是说Googole 和 RedHat主导开发的Kubernetes
Kubernetes是基于Google公司提供的理论基础,Google的秘密武器Borg系统
在Google公布的基础设施论文中,Borg项目在技术栈的最底层
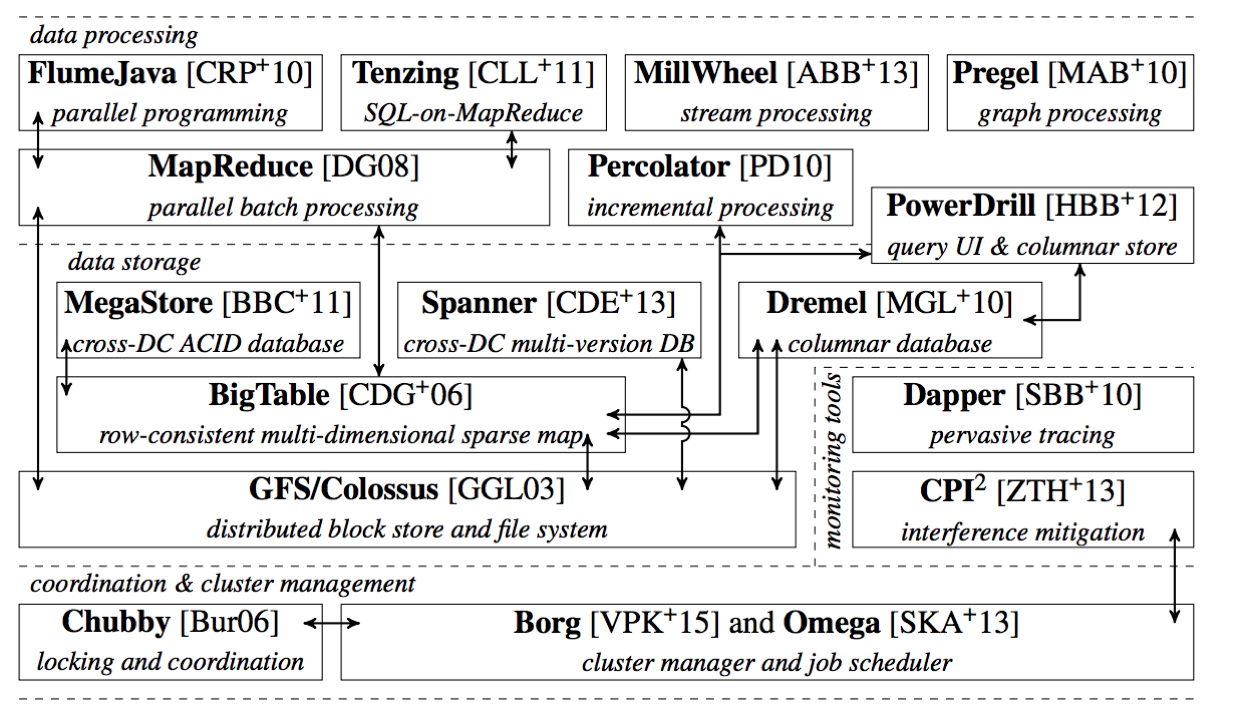
这是之前的Google的基础设施栈,整体中,Borg处于技术栈的最底层
Borg本来不太可能开源的东西,因为Docker技术的风靡,从而可以以kubernetes的方式和大家见面了
那么我们说下K8S为了解决什么问题而出现的
编排,调度,容器云,集群管理
一般来说,K8S提供的最基础的方面包含,给与一定的集群服务器,部署一定的应用
还能提供路由网关 水平扩展 监控 备份 灾难恢复等一系列运维能力
但是这些都是经典的PAAS项目的能力
有了Docker之后,我们不需要什么Kubernetes Paas,只需要Docker提供的Compose+Swarm就可以提供这些功能了
如果说Kubernetes只是个能拉取用户镜像,运行容器和常见的运维的项目,那么也没啥竞争力
但是,Kubernetes脱颖而出了
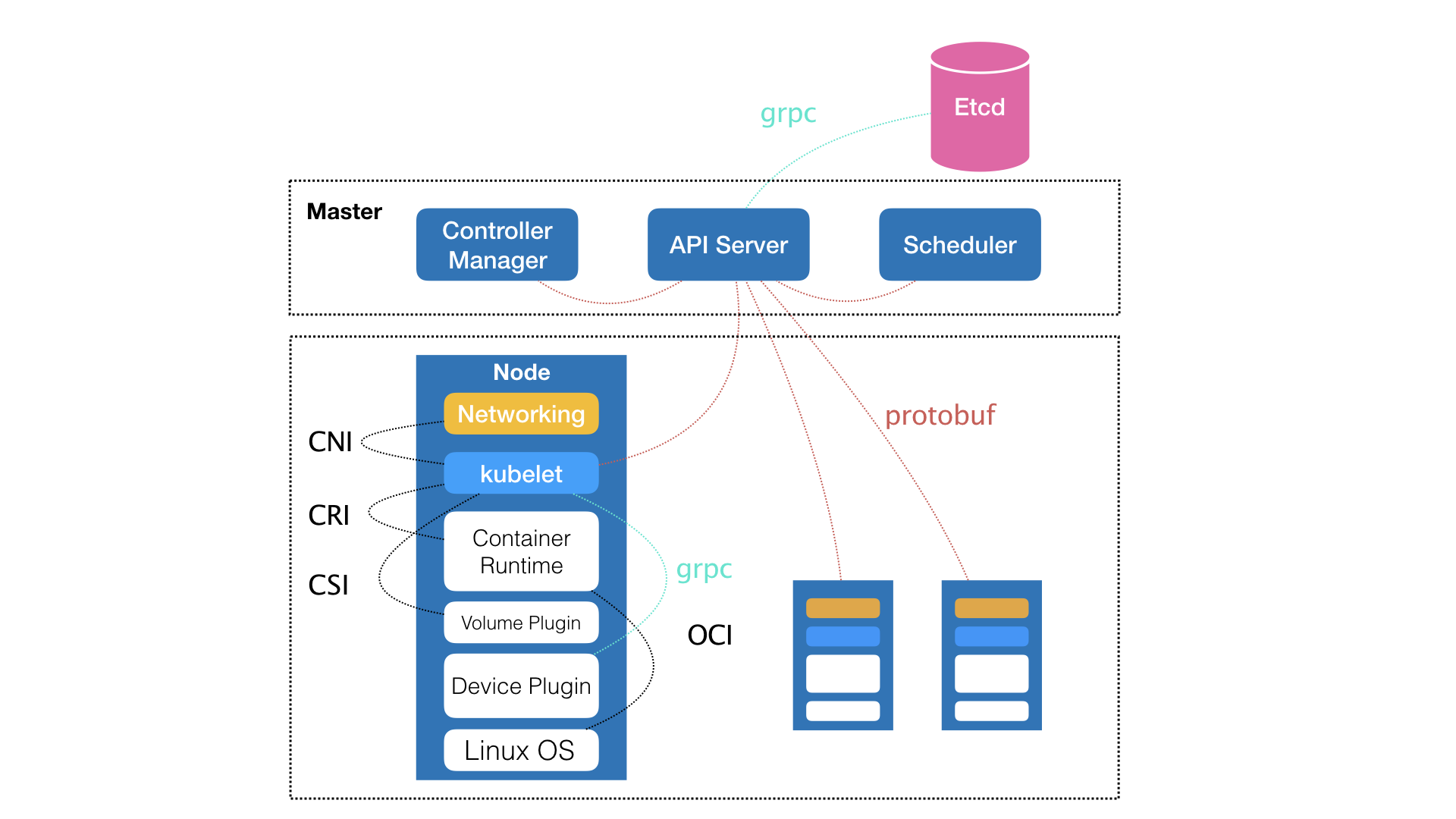
kubernetes项目整体的架构,和其原型项目Borg非常类似,都由Master和Node节点构成,
控制节点,即为Master节点,由三个紧密合作的组件构成,API服务的kube-apiserver
调度的kube-scheduler,容器编排的kube-controller-manager,整体的集群的持久化数据,则由kube-apiserver处理后保存在Etcd中
最核心的节点,叫做kubelet的组件
在kubernetes项目中,kubelet主要负责同容器运行时的项目打交道,而这个交互所依赖的,是一个称为CRI的远程调用接口协议,这个接口定义了容器运行时的各项核心操作
只要是实现了CRI的标准的容器镜像,就可以通过CRI接入到Kubernetes项目中
具体的容器运行时,比如Docekr 项目,通过OCI这个容器运行时规范和底层Linux操作系统交互
CRI可以将请求翻译为Linux操作系统的调用
另外,kubelet还通过gRPC协议来进行Device Plugin的插件进行交互,这个插件,是Kubernetes项目进行管理GPU等宿主机物理设备的主要组件,基于Kubernetes进行机器学习的训练必须要关注的功能
Kubelet的另一个重要的功能,是调用网络插件和存储插件为容器配置网络和持久化存储,这两个插件和kubelet的交互接口,分别是CNI和CSI
Borg对Kubernetes有什么指导作用吗?
在Master节点上,Borg和Kubernetes项目不尽相同,出发点高度一致,如何编排,管理,调度用户提交的作业
所以,Kubernetes没有像其他的容器一样,将Docker作为架构核心,而是将其作为一个容器的运行时实现罢了
所以Kubernetes项目着重解决的问题,来自于Borg研究人员在论文中提到的一个重要观点
运行在大规模集群各个任务间,存在着各种各样的关系,这些关系的处理,才是任务编排和管理系统的着重侧倾点
这种任务和任务之间的关系,在平常的各种技术场景中随处可见,一个Web应用和数据库的关系,一个负载均衡和后端服务之间的代理,一个门户和授权组件的调用关系
同属一个服务单位的不同功能之间,可能存在这种关系,一个Web应用和日志搜集组件之间的文件交换关系
容器技术普及之前,这种环境的处理就是比较粗粒度的,很多不想管的应用被一股脑的塞在一起,只是因为会偶尔的发起几个HTTP请求
而且,还需要处理很多协同进程
但在容器技术出现之后,在功能单位的划分之后,容器更加细粒度,毕竟容器的本质,就是一个进程罢了
容器的出现,让各个应用,都可以单独做成镜像,在一个个自己的专属容器中,互不干涉,拥有各自的资源,调度在集群的任何一个机器上
但是这种封装微服务,调度单容器的层次,Docker Swarm就可以实现,再加上Compose项目,还具有了一些处理依赖关系的能力,一个Web服务和对应的DB容器
在Compose项目中,可以为两个不同的容器定义一个link,在Docker项目中会维护这个link的关系,Docker会将DB容器的相关信息,注入到Web容器中,供应用进程使用
当DB容器发生变化的时候,环境变量的值会伴随着Docker项目自动更新,这就是平台项目自动处理容器间关系的例子
可是,现在可能出现的需求是,可能出现更多种类的关系,如何来进行支持呢?
link这种单一的连接会不太合适,也是kubernetes考虑从更加宏观的角度,来定义任务之间的关系,来支持更多种类的任务关系
我们来对一些不同类型的关系进行区分,比如常规环境下,应用往往会被部署在一台机器上,通过Localhost来进行访问,通过本地磁盘交换文件,这些容器会被换为为一个Pod,Pod中的容器共享一个Network Namespace,同一组数据卷,达到高效交换信息的目的
Pod是Kubernetes的基础对象
然后是一种更为常见的需求,Web应用和数据库之间的访问关系,Kubernetes项目提供了一种叫Service的服务,像两个应用,一般不在同一机器上,即使Web应用宕机了,数据库也不会受影响,那么这两者之间的信息是如何维护的呢?
Kubernetes的项目的做法是给Pod绑定一个Service服务,这个Serivce服务保证自己的IP地址信息不会改变,方便其他的节点进行调用
对于Web后端的Pod,会比较关心数据库的Pod信息,这样Service保证了实际IP和其维护的固定IP的关系,这就是Kubernetes的职责
下面就是Kubernetes的核心功能的全景图
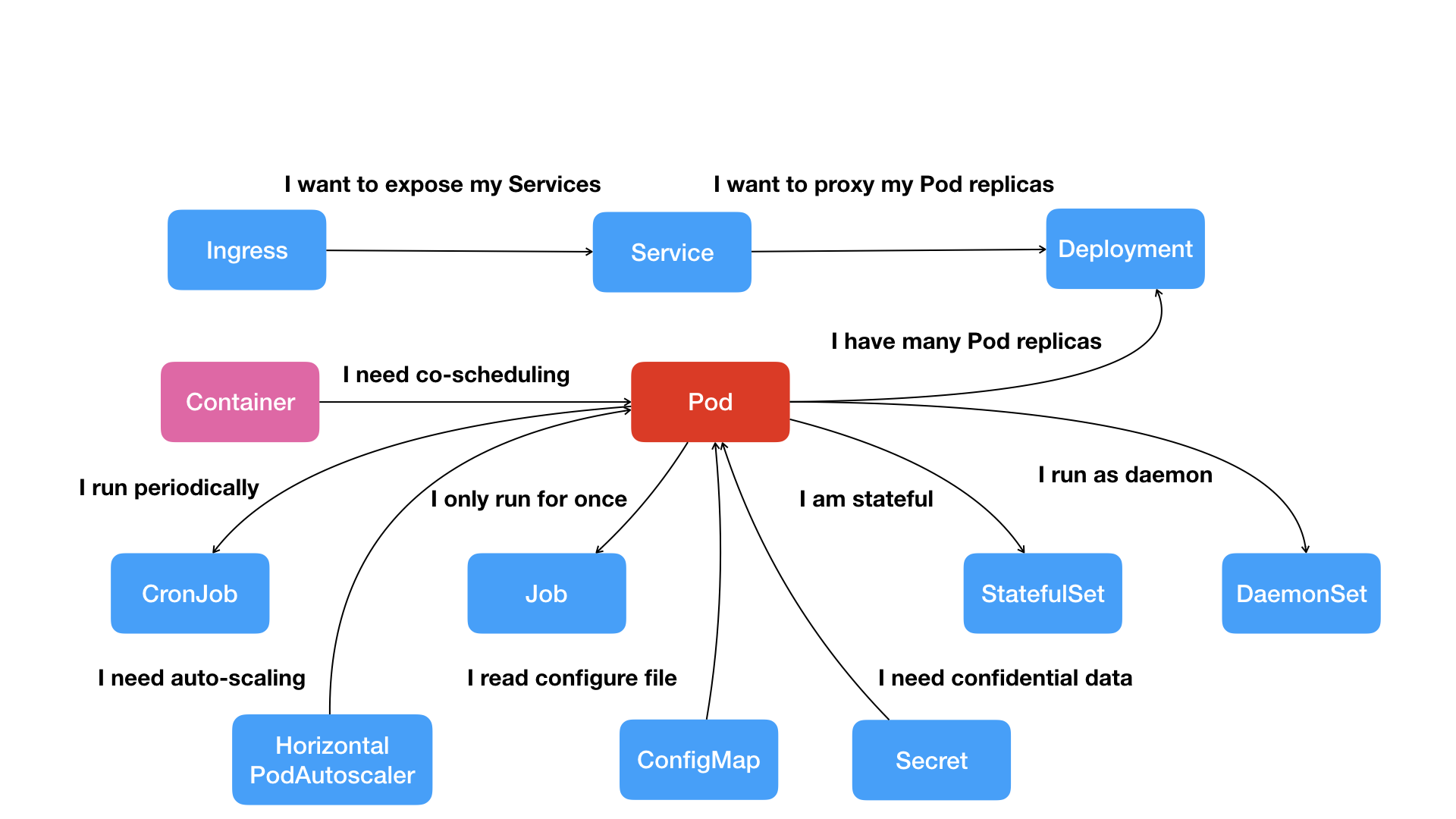
首先是容器的合作关系,于是出现了Pod这个划分概念,然后就有了Deployment这个Pod的多实例管理器,有了这一组相同的Pod之后,就需要一个固定的IP地址和负载均衡来进行访问,就是Service
然后两个Pod之间不仅仅有访问关系,还有授权关系,比如Web对数据库访问的密码信息,这就需要将这些授权信息以secret的方式保存在Etcd中,kubernetes会在指定的Pod启动的时候,将Secret中的数据以Volume的方式挂载到容器中,这样Web应用访问数据库了
然后容器化这个应用,是kubernetes接下来考虑的问题
kubernetes定义了一些诸如Pod这样基础的对象,然后改进了Job这样的对象,用来描述一次性运行的Pod
还有DaemonSet,用来描述守护进程服务,CronJb,用来描述定时任务
这就是Kubernetes项目没有像其他项目那样,为每一个管理创建一个指令,然后实现这个逻辑
而是,简单的通过一个编排对象,比如Pod Job CronJob来描述管理的应用
然后定义一些服务对象,比如Service Secret等对象,来负责具体的管理
这种使用的方式,就是所谓的生命式API,这种API对应的编排对象和服务对象,都是Kubernetes中的API对象
最后Kubernetes如何启动一个容器化的任务呢?
我们已经制作好了一个Nginx容器,如何去运行呢?而且最好能运行两个完全一样的Nginx副本,以负载均衡的方式对外提供服务
如果是DIY,可能需要启动两个虚拟机,分别安装两个Nginx,然后利用keepalived来为两个虚拟机做一个虚拟IP
如果是使用Kubernetes,则只需要进行编写如下的YAML的文件,比如nginx-deployment,yaml
| apiVersion: apps/v1
kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: – name: nginx image: nginx:1.7.9 ports: – containerPort: 80 |
我们定义了一个Deployment的对象,主体是一个使用了Nginx镜像的Pod,Pod的副本数为2
然后执行
kubectl create -f nginx-deployment.yaml
这样,两个Nginx副本就启动了
这样Kubernetes的声明式API的简介就完事了
我们这次讲解中,介绍了kubernetes项目的架构,讲解了如何使用声明式API,来描述容器化业务和容器间关系的设计思想
我们还介绍了kubernetes项目的架构,如何使用声明式API,来描述容器化业务和容器间业关系的设计思想
我们之前,都是将一个容器,按照某些规则,放在某些节点上运行,这种功能,叫做调度
kubernetes,则是按照用户的意愿和系统规则,自动的编排好容器的之间的关系
1.Docker Swarm和Kubernetes在架构和使用方式上的异同
2.Kubernetes之前,很多项目无法管理有状态的容器,无法阻止从一台宿主机往另一台宿主机迁移,为何?
1.对于Swarm,和docker公司的风格很一致,上手简单,但是对于大量的依赖在不同容器间的传递并不好处理,K8S从更高层的视野看服务器软件架构从而提出了更加庞大的解决方案,反而是更加有效
2,主要是因为在本地有很多临时文件,迁移的时候无法进行有效的迁移