这一次我们利用LangChain,先搭建一个简单的系统,来查看整体看下LangChain的每个具体组件。
这里先说下这个系统的需求大概。
即我们作为一个平台,内部包含大量文档,不同类型,不同格式,为此我们需要开发一个系统的QA系统,可以通过自然语言,来让员工查询最新的员工手册。
系统按照实现可以分为三个部分
数据源 DataSources,数据可以包含很多种,包括PDF在内的非结构化数据,SQL在内的结构化数据,这里我们聚焦于非结构化的数据
大模型应用 Application,也就是外部提供的大模型,来生成所需回答
用例 Use-Cases,大模型生成的和预设的案例
核心逻辑可以简化为下图
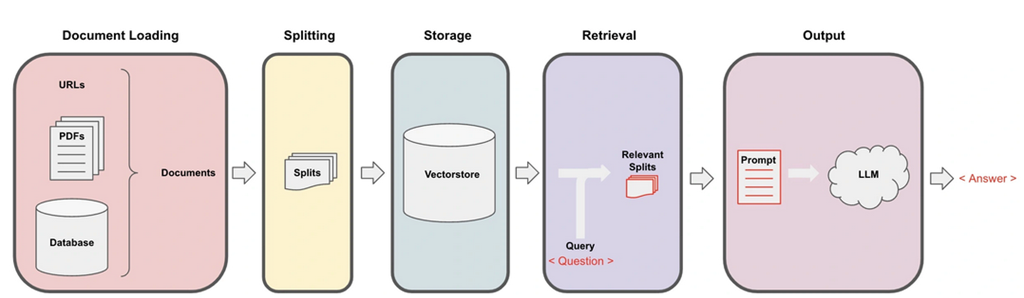
分为了
Loading,文档加载为LangChain能读取的形式
Splitting,进行文本切割,切割为文档块或者文档片
Storage,将文档块嵌入到向量数据库中,形成嵌入片
Retrieval,应用程序从存储中检索分割后的文档
Output,将问题和相似的嵌入片传递给大模型,从而生成答案。
具体的每一部操作,就是我们需要实现的代码。
首先我们准备了一些PDF,word等类型的文件。
然后进行书写
1. Loading
利用 LangChain中的document_loaders来加载各种格式的文本文件
|
# 1.Load 导入Document Loaders
from langchain.document_loaders import PyPDFLoader from langchain.document_loaders import Docx2txtLoader from langchain.document_loaders import TextLoader # 加载Documents base_dir = ‘.\OneFlower’ # 文档的存放目录 documents = [] for file in os.listdir(base_dir): # 构建完整的文件路径 file_path = os.path.join(base_dir, file) if file.endswith(‘.pdf’): loader = PyPDFLoader(file_path) documents.extend(loader.load()) elif file.endswith(‘.docx’): loader = Docx2txtLoader(file_path) documents.extend(loader.load()) elif file.endswith(‘.txt’): loader = TextLoader(file_path) documents.extend(loader.load()) |
利用不同的格式的Loader,将文本从文件中加载了出来。
然后我们对文本进行相关的切割
这个也有相对应的傻瓜包
直接使用LangChain中的RecursiveCharacterTextSplitter来分割文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
这样,我们的文档中的文本就被切分为了200个字符串左右的文档块。
之后就是将这些分割后的文本转换为可嵌入的形式,存储在一个向量数据库之中。
如何转换为嵌入形式,这需要使用到模型提供的能力,最好是配套的模型能力
转换完成的值,可能是一个多维度数组,例如
“国王” -> [1.2, 0.5, 3.1, …]
“皇帝” -> [1.3, 0.6, 2.9, …]
“苹果” -> [0.9, -1.2, 0.3, …]
可以看出,国王和皇帝的词义是相似的,但是和苹果的差距就比较大。
然后这样一个多维数组,需要存储在向量数据库之中。
向量数据库之中,可以用来存储向量形式的数据的数据库,存储多维度数据,从而方便支持人工智能应用。
常见的向量数据库包含 Pinecone,Chroma和Qdrant
分为开源和非开源的
我们这里使用Qdrant作为向量数据库
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents, # 以分块的文档
embedding=OpenAIEmbeddings(), # 用OpenAI的Embedding Model做嵌入
location=”:memory:”, # in-memory 存储
collection_name=”my_documents”,) # 指定collection_name
这样,所有的内部文档,都被以嵌入片的格式存储在向量数据库之中了。
之后就是在提问的时候,将问题转换为向量进行匹配了
不过在计算向量匹配的时候,有两种计算方式,欧式距离和余弦相似度
两者对应的场景不一致
欧式距离偏向绝对距离,比如用户的购买量,相似产品的推荐
余弦相似度偏向方向的相似性,更符合信息检索的场景。
那么我们在这里就是一个信息检索的场景,更加适合使用余弦作为度量标准
那么我们就以余弦为匹配模板,创建一个RetrevalQA链。
其中包含两个部分,一部分是大模型,一部分为检索文档
from langchain.chat_models import ChatOpenAI # ChatOpenAI模型
from langchain.retrievers.multi_query import MultiQueryRetriever # MultiQueryRetriever工具
from langchain.chains import RetrievalQA # RetrievalQA链
# 实例化一个大模型工具 – OpenAI的GPT-3.5
llm = ChatOpenAI(model_name=”gpt-3.5-turbo”, temperature=0)
# 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
# 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
然后我们创建一个Flask示例
通过暴露接口来对外提供QA能力
|
@app.route(‘/’, methods=[‘GET’, ‘POST’])
def home(): if request.method == ‘POST’: # 接收用户输入作为问题 question = request.form.get(‘question’) # RetrievalQA链 – 读入问题,生成答案 result = qa_chain({“query”: question}) # 把大模型的回答结果返回网页进行渲染 return render_template(‘index.html’, result=result) return render_template(‘index.html’) |
总结一下,我们利用LangChain,支持进行了从加载到切片的一系列操作,并将结果。
存储在了向量数据库,然后将用户输入和从向量数据库中检索到的本地知识传递给了大模型,最终生成了想要的答案。