数据仓库的复习
- ODS层常用的压缩和存储方式
对于压缩,则是Snappy,对于存储,既有Parquet,也有ORC技术进行压缩。
- 数据仓库中常见的分层有哪些
ODS 原始数据层, DWD 明细数据层,DWS 服务数据层
DWT 主题数据层 ADS 应用数据层
- DWD层的主要工作
主要是数据清洗,这里包括了对于数据的空值去除,对于数据的脱敏。
对于业务数据的表进行维度的退化,进行数据落库,进行列式存储。
使用的技术有Flink,Kafka, HDFS等
- DWS层的工作呢?
DWS 主要是联合更多的维度表,提供更明晰的数据,形成一个宽表
从而提供多个指标
- 事实表中存在哪些类型
常见的有事务事实表,周期事实表,累计事实表,非事实事实表
事务事实表,存放的是最基础的数据
周期事实表,可以理解是按照一个固定时间间隔进行聚集的聚集表
累积快照事实表,按照某些指标或者事物的生命周期进行聚集的聚集表
非事实型事实表,记录一些事件的范围
- 常见的数据模型
主要有星型模型,雪花模型,星座模型
星型模式最为常见,就是一个事实表和多个维度表
维度表围绕事实表呈星形分布
雪花模型,也就是维度表之外还有维度表,就比如客户信息表之外还有地址表
维护成本较高
星座模型,就是多个事实表之间共享同一个的维度表,这是因为多维空间中的事实表往往不止一个,一个维度表可能被多个事实表共享,也是现在数据仓库构建中采用的数据模型
- 数据漂移问题
什么是数据漂移问题,就是一个存在迟到数据,导致在某一个固定周期内丢失了某些数据
或者错误的加入了不属于这个周期的数据。
对于这个问题,常见的解决方案有两种,多获取数据,或者利用多个时间戳来进行保证数据的
比如我们在ods层中,存储的数据里面包含多个时间戳字段,modified time 数据更新的时间戳字段, 数据记录更新时间的时间戳字段 log time, 业务发生时间的时间戳字段proc time,提取的时间戳字段 extract time
常见的就是根据log time 多获取一部分,然后利用proc_time来获取到想要的数据。
- 维度建模和范式建模的区别
通常来说的范式建模,也就是3NF模型具有如下的特点,原子性,实体属性完全依赖于主键,任何非主属性不依赖于其他非主属性
从而保障数据一致性,也是主要为了确保数据的一致性
但是维度建模不一样,主要是可以快速,灵活的提供大规模的数据响应,也就是我们的星型模型,雪花模型,星座模型。
- 什么是数据仓库中的元数据
在整个数据仓库中,处理直接读写的业务数据,其他用来维护整个系统运转所需的数据,都是元数据。
常见的元数据可以分为,技术元数据,业务元数据。
技术元数据主要是为了描述数据仓库的运转模式,数据仓库本身的描述,比如不同数据的存放位置,刷新规则等。
业务元数据,则是存放一些企业的数据基本概念,可以让非数据使用者明白,分别存放的什么方向的数据
让数据使用者明白,都有哪些维度的数据
- 数据仓库的主题
这往往和业务有很高的关联度,一般来说,这是企业某一宏观分析领域的具体u底下爱哪个
一般都是根据业务的关注点进行划分
- 数据质量怎么监控
这一点可以通过建立完整的数据监控体系来解决
通过数据量进行对比,可以进行同比或者环比进行测评
以及设置合理的报警触发条件
- 数据分析方法论
一般在商业数据中,数据分析主要是为了
观察数据当前发生了什么,比如不同赛道各自带来了多少流量
或者观察数据模型理解不同赛道的数据差异原因
或者预测未来会发生什么,比如投放新赛道的时候,可以预测哪个产品更受欢迎
并以此为依据,来进行商业化决策。
- 数据湖的意义
其本身就是存放各个业务系统的原始数据,称为数据湖
在上面进行汇总清洗后的数据,形成数据仓库
比如我们的HDFS,或者线上的OSS,以及S3
- 数据湖的优势
在于可以轻松的进行收集数据,因为对于写入没有限制,变得更容易写入
以及消除了数据孤岛,毕竟是存放了所有的原始数据
成本低带来了更高的扩展性和敏捷性
- 数据湖的能力
可以提供足够的数据存储能力
可以存储任意类型的数据
可以具有完善的数据管理能力,可以管理各种各样的要素
可以连接多种外部分析工具,比如批处理工具,流处理工具,甚至是机器学习

并附上AWS的官方对比
- 数据湖和数据仓库的区别
数据仓库是面向主题的,对外直接暴露了可以开箱即用的数据
而且数据仓库的集成能力很高,具有统一的存储方式
而数据湖,则是具有高度的灵活性,支持多种存储能力
而且具有大批量存储的能力
- 常见云厂商的数据湖
AWS的数据湖解决方案,基于AWS Lake Formation
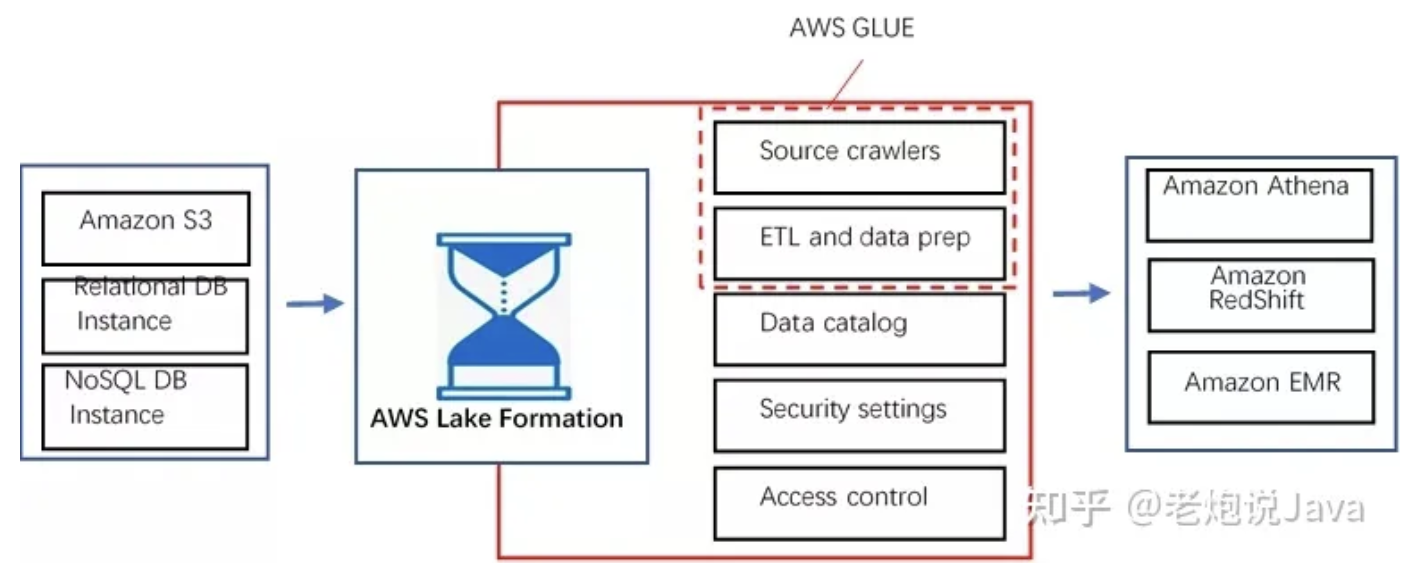
AWS 利用 Glue进行数据抓取,并提取获取其中的元数据
利用S3 进行存储
利用Glue和Lambda进行计算操作
最后通过EMR提供Spark集群从而进行计算
通过Athena提供了基于SQL的交互能力
阿里云的数据湖解决方案
阿里云的数据湖解决方案叫做DLA,使用OSS作为集中存储
DLA支持一键建湖,也支持自动发现Schema,对外叫做Meta data catalog组件进行统一的管理
而且支持集成Spark
并且可以向上直接推送到云原生数据仓库 ADB组件
Azure的数据湖解决方案
包括数据湖存储,接口层,资源调度和引擎层
存储层是基于Azure object Storage构建的
并且提供了U-SQL Hadoop Spark等计算处理引擎