7. Starrocks的导入(一)
Starrocks的导入会被定义为一个job,每个job有自己的标签 (Label),由用户指定或系统自动生成。每个标签在一个数据库内都是唯一的。
并且StarRocks 中所有导入方式都提供原子性保证,即同一个导入作业内的所有有效数据要么全部生效,要么全部不生效,不会出现仅导入部分数据的情况。这里不出意外的采用了二阶段提交方式,只有所有节点就绪才会进行i叫操作
那么我们就说下导入的详细信息
从导入的使用来说,分为同步导入和异步导入。
对于同步导入,会阻塞等待作业执行完成返回导入结果。可以通过返回的导入结果判断导入作业是否成功。
支持同步模式的导入方式有 Stream Load 和 INSERT。
对于异步导入,会直接创建一个job并返回,异步执行这个job,这就需要通过语句或命令来查看导入作业的状态,并且根据导入作业的状态来判断数据导入是否成功。
支持异步模式的导入方式有 Broker Load、Routine Load 和 Spark Load。
那么我们具体同步导入和异步导入之间详情
- Stream Load
从本地文件或者流式数据而来,通过 HTTP 协议导入本地文件、或通过程序导入数据流。一般导入10 GB 以内数据,支持json和CSV,属于同步导入
- Broker Load
从HDFS,Amazon S3等存储系统导入而来,支持导入数十到数百 GB,可选 CSV Parquet ORC格式,属于异步导入
- Routine Load
从Apache Kafka®导入,支持微批导入 MB 到 GB 级,可以导入CSV,JSON,Avro,属于异步导入
- Spark Load
HDFS,Hive. 通过 Apache Spark™ 集群初次从 HDFS 或 Hive 迁移导入大量数据, 支持数十 GB 到 TB级别。CSV,ORC,Parquet
- INSERT INTO SELECT
常见于外表导入,属于同步导入
官方也附上了一个图,来展示不同数据源下,该如何选择导入方式
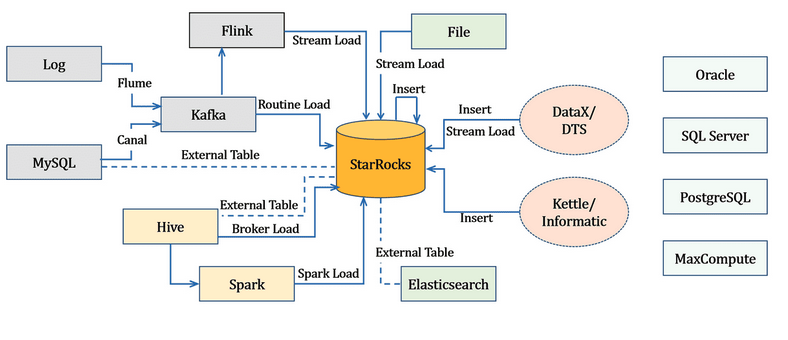
这里我们在给出一些Load重要的配置项
max_load_timeout_second 和 min_load_timeout_second
最大最小超时区间
desired_max_waiting_jobs
等待队列可以容纳的导入作业的最大个数,默认值为 1024
max_running_txn_num_per_db
StarRocks 集群每个数据库中正在进行的导入事务的最大个数
label_keep_max_second
导入作业记录在 StarRocks 系统的保留时长,默认值为 3 天。
load_process_max_memory_limit_bytes 和 load_process_max_memory_limit_percent
导入的最大内存使用量和最大内存使用百分比,用来限制单个 BE 上所有导入作业的内存总和的使用上限。
主要是百分比,默认为 30%,假设 BE 所在机器物理内存大小为 M,则用于导入的内存上限为:M x 90% x 90% x 30%。