Starrocks不同的性能压力测试
本次测试主要分为两个方面进行测试,对应的也是硬件上的两个方面,分别是内存使用率, CPU使用率。本文主要是测试在不同情况下,这两方面的使用率,以确定Starrocks的压力来源。
本文根据真实的生产环境进行测试。主要测试SQL运行期间的硬件使用率。
其次,现有集群分为两种类型的机器,分别是集群中的FE节点和BE节点。FE节点主要用于存储元数据信息,BE节点存储实际数据和负责实际SQL执行
对于FE节点,我们是8核,16GB的机器
对于BE节点,我们是16核,64GB的机器
关于机器的选型,则是参考了官方文档上的生产集群搭建建议
https://docs.starrocks.io/zh-cn/3.0/deployment/plan_cluster#cpu-%E5%92%8C%E5%86%85%E5%AD%98
- 查询
首先给出在没有使用情况下,正常的集群利用率
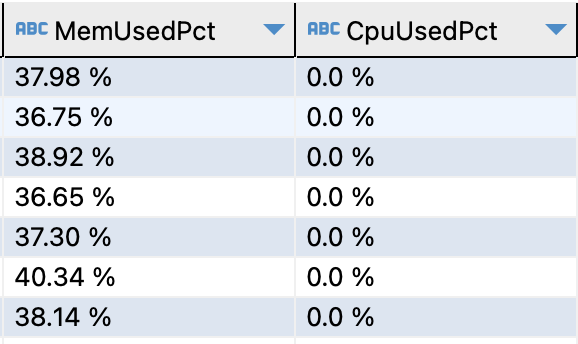
从上面Starrocks自身统计中可以看出,默认情况下,内存使用率大约在35%-40%之间,CPU理论为0
这里我们首先准备了一张数据单表,数据量为487096772,硬盘占用51GB
建表语句如下
| CREATE TABLE `test` (
`basic_id` varchar(1048576) NULL COMMENT “”, `version` varchar(1048576) NULL COMMENT “”, `unit_type` varchar(1048576) NULL COMMENT “”, `model_type` varchar(1048576) NULL COMMENT “”, `data_date` varchar(1048576) NULL COMMENT “” ) ENGINE=OLAP DUPLICATE KEY(`basic_id`) DISTRIBUTED BY HASH(`basic_id`) PROPERTIES ( “replication_num” = “3”, “in_memory” = “false”, “storage_format” = “DEFAULT”, “enable_persistent_index” = “false”, “replicated_storage” = “true”, “compression” = “LZ4” ); |
对此我们给出的SQL为
| SELECT sum(cast(replace(version, “\””, ”) as DECIMAL64(10,2)) * cast(replace(basic_id , “\””, ”) as BIGINT))
FROM test WHERE data_date >= ‘2022-01-01’ and data_date <= ‘2023-05-31’ AND unit_type = ‘”778″‘ |
并模仿10个人的并发,获取到的CPU使用率为
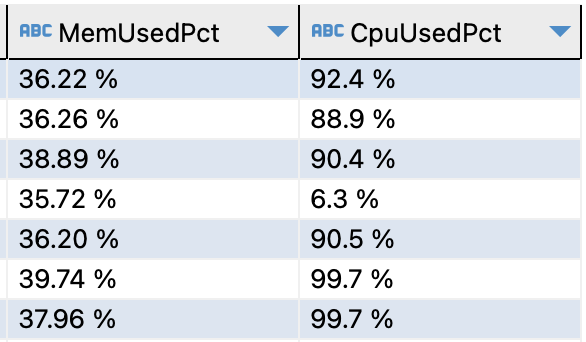
上述SQL包含较多的聚合函数,这是由于我们在正式使用中,往往需要配合Superset BI, Power BI 等BI工具使用。故在使用中会出现大量的聚合函数。
而从上面的使用我们可以看出,在出现大量聚合函数的时候,会导致CPU使用率大量的上升。
- 导入
针对数据的导入,我们这边采用的是Starrocks官方提供的Spark-connector进行的导入。
其过程可以简化为从OSS上读取parquet或csv文件,读入Spark集群。在进行处理之后,利用Spark-connector进行导入。
那么我们有一批大小为1TB的数据,导入到表test中
在启动相关的Glue job之后,可以观察其内存使用情况
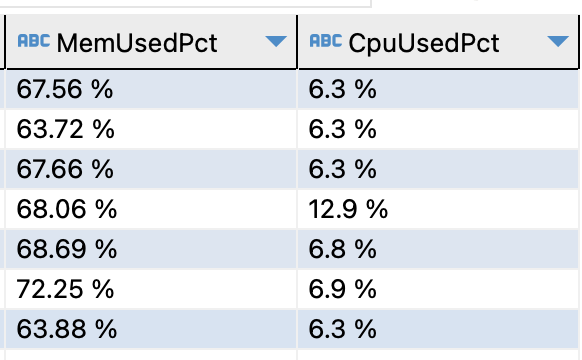
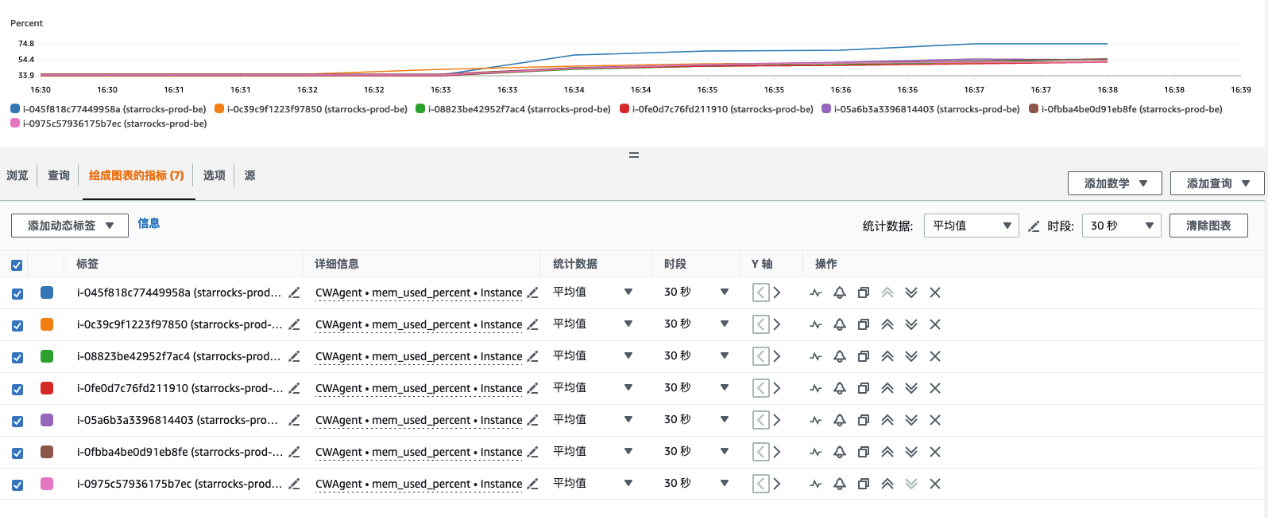
在启动后的十分钟内,内存持续达到70%使用率
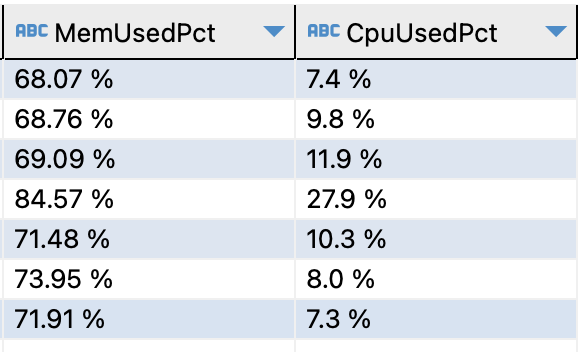
最大值甚至达到80%以上
而这是我们在进行单表导入时出现的内存使用率情况
由于我们在未来会同时运行多个导入任务在starrocks之上,在内存选型上可以充分发挥64GB的作用
最后是关于硬盘上的使用
对于硬盘使用,会伴随着导入数据的增多的增多,而一台机器的最佳配置中,往往是2T-4T搭配一台16核64GB的机器。所以伴随着数据增多,硬盘占用也会变多,最后也会导致集群的整体增大。