Spark + Kafka
我们这一次就说下Kafka如何配合Structured Streaming
在实际生产中,Kafka和Spark这对组合还是比较常见的,这里我们就拿一个简单的实例看下如何将两者进行集成
在这里,我们进行资源利用率计算,我们搜集各个服务器上的资源利用率,将其写入Kafka,然后使用Spark的Structured Streaming进行消费,分析聚合后将其写入Kafka,或者打印到Console中
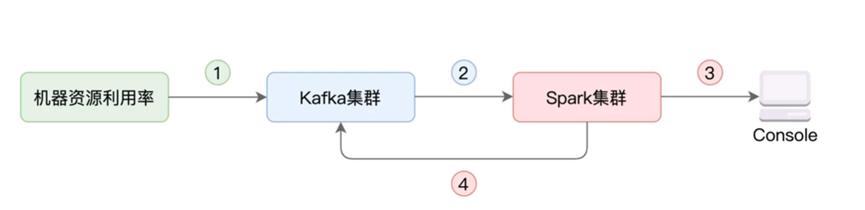
在这里,我们直接先跳过介绍Kafka,直接看Kafka和Spark如何进行集成
我们假设已经存在了两个topic,分别对应着cpu和内存的检测,分别叫做cpu-monitor和mem-monitor两个topic
我们需要在Structured Streaming 中的readSteam上配置相关属性
|
import org.apache.spark.sql.DataFrame 2
// 依然是依赖readStream API val dfCPU:DataFrame = spark.readStream // format要明确指定Kafka .format(“kafka”) // 指定Kafka集群Broker地址,多个Broker用逗号隔开 .option(“kafka.bootstrap.servers”, “hostname1:9092,hostname2:9092,hostname3:9092” // 订阅相关的Topic,这里以cpu-monitor为例 .option(“subscribe”, “cpu-monitor”) .load() |
在format中我们指定了输入源为kafka,然后配置kafka.bootstrap.servers的相关属性
需要配置多个Broker服务器地址,多个Broker之间需要以逗号进行分割
之后利用subscribe指定消费的topic名,明确Structured Stream要消费的Topic
之后我们就将其读取为了DataFrame,我们就可以利用Data Frame相关的处理算子进行处理,而且配合流处理的Window机制,可以以窗口为粒度进行统计
这里我们拿控制台作为输出进行下测试,看下输出格式
|
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import scala.concurrent.duration._ dfCPU.writeStream .outputMode(“Complete”) // 以Console为Sink .format(“console”) // 每10秒钟,触发一次Micro-batch .trigger(Trigger.ProcessingTime(10.seconds)) .start() .awaitTermination() |
这里我们获取到了Kafka中信息本体
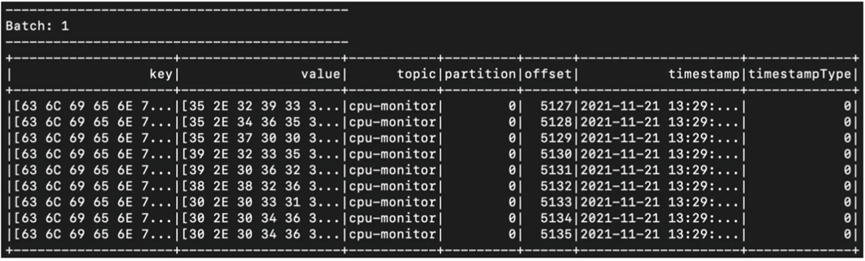
这样我们就可以对数据进行处理了
|
import org.apache.spark.sql.types.StringType 2
dfCPU .withColumn(“clientName”, $”key”.cast(StringType)) .withColumn(“cpuUsage”, $”value”.cast(StringType)) // 按照服务器做分组 .groupBy($”clientName”) // 求取均值 .agg(avg($”cpuUsage”).cast(StringType).alias(“avgCPUUsage”)) .writeStream .outputMode(“Complete”) // 以Console为Sink .format(“console”) // 每10秒触发一次Micro-batch .trigger(Trigger.ProcessingTime(10.seconds)) .start() .awaitTermination() |
首先是代码中,我们将key和value设置为列String ,然后按照ClientName进行聚合
并且我们设置了每十秒触发一次,输出到控制台
或者我们修改下outputMode, 指定kafka为输出,代码如下
|
dfCPU
.withColumn(“key”, $”key”.cast(StringType)) .withColumn(“value”, $”value”.cast(StringType)) .groupBy($”key”) .agg(avg($”value”).cast(StringType).alias(“value”)) .writeStream7 .outputMode(“Complete”) 8 // 指定Sink为Kafka .format(“kafka”) // 设置Kafka集群信息,本例中只有localhost一个Kafka Broker .option(“kafka.bootstrap.servers”, “localhost:9092”) // 指定待写入的Kafka Topic,需事先创建好Topic:cpu-monitor-agg-result .option(“topic”, “cpu-monitor-agg-result”) // 指定WAL Checkpoint目录地址 .option(“checkpointLocation”, “/tmp/checkpoint”) .trigger(Trigger.ProcessingTime(10.seconds)) .start() .awaitTermination() |
我们通过format指定输出为Kafka,设置Kafka的集群环境 并且通过topic设置了输出topic
并且设置了WAL Checkpoint路径
这样我们就将聚合后的信息再一次的输出到了Kafka中
还需要注意两点,也就是写入写出的topic需要不一样,避免无限循环
一个是写出的Schema中必须要用到 key 和 value两个固定的字段
那么我们总结一下,我们手把手的实现了kafka和sprak的集成,完成了从Kafka读取数据,然后写回到Kafka的全过程