Flink的分发转换
在Flink中通过设定不同的数据分区策略,可以定义事件如何分配给不同的任务.
如果不设定,则系统会根据操作语义和并行度来自动选择数据分区策略并将数据转发到正确的目标.
而Flink提供了一些用于控制分区策略或者自定义分区策略的方法
1. 随机 利用DataStream.shuffle()方法可以实现随机数据交换的策略,可以按照均匀分布的方式将数据发往后面的并行任务.
2. 轮询 rebalance()方法会将输入流中的事件按照轮询的方式均匀的分发给后续的任务
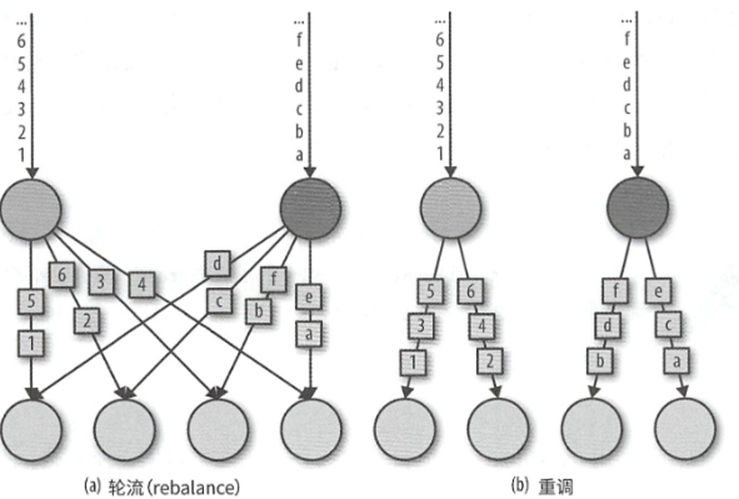
3. 重调 rescale() 也是轮询的进行分发事件,但是分发的目标算子是特定的几个算子,并非是所有算子,在接收端任务数量远大于发送端任务数量的时候,就很有效,rebalance和rescale的区别如下图
4. broadcast() 将输入流中的事件复制并发往所有下游算子的并性任务
5. global() 将所有事件发往下游算子的第一个并行任务,需要注意,使用的时候可能会影响程序性能.
6. 自定义策略,如果没有合适的预定义策略,那么可以使用partitionCustom的方式来自定义策略. partitionCustom()这个方法接收一个Partitioner对象,其中实现分区逻辑
7. 比如我们定义一个Partitioner,来实现对整数数据流进行分区,其中负数发往第一个任务,其余的都随机发送
| object myPartitioner extends Partitioner[Int]
{ val r = sea la.util.Random override def partition (key:Int ,「1 UmPartition s:Int):Int = { if (key < o) o else r.n ex tint(numPartitions) } } |