Flink Stream API初识
这一次我们讨论常见的流式架构和组件,Flink的类型系统和支持的数据类型,
数据转换和分区转换操作.
构建一个典型的Flink流式应用需要以下几步
1. 设置执行环境
2. 从数据源中读取一条或者多条流
3. 通过流式转换来实现业务逻辑
4. 选择性地结果输出到一个或者多个输出中
5. 执行程序
先给出一个标准的执行代码

而设置执行环境是第一个需要做的事情,
执行环境明确了本地机器上执行还是集群上执行,DataStream API执行环境由StreamExecutionEnvironment来表示,如果直接执行getExecutionEnvironment来获取执行环境,那么会根据当时的上下文来返回不同的环境
如果是一个远端集群的客户端来调用,那么会返回一个远程执行环境,不然返回一个本地环境.
如果希望显式的指定环境,可以
StreamExecutionEnvironment.createLocalEnvironment() 获取本地执行环境
StreamExecutionEnvironment.createRemoteEnvironment() 获取远程执行环境
2.从数据源中获取输入流
StreamExecutionEnvironment提供了一系列创建流式数据源的方法,利用addSource即可
数据源的来源可以是消息队列或者文件等
上面我们就自定义了一个输入流来实现定期输入SensorReading记录.
3.记录在流中的转换
对记录进行转换,而转换的类型有很多,有时候会重新生成一个新的DataStrean,有时候会进行分区
比如上面的代码中,就是先利用map将温度转为摄氏度
然后利用keyBy()进行分区,然后进行窗口划分,利用timeWindow() 转换
4.进行结果输出
通常将结果输出到外部系统中,比如Apache Kafka,Flink提供了一组维护良好的流式数据输出算子,当然你也可以自己实现输出算子
有些应用的状态可能都不对外,只能利用Flink的可查询状态 queryable state对外提供服务.
上面我们使用print()来创建了一个简单的输出算子.
5.执行
这一点可以简化为StreamExecutionEnvironment.execute()来执行
在调用execute之后,才会将在执行环境中构建的执行计划,包含了从环境创建的流式数据源以及一系列转换的这样一个计划,触发执行.
执行的计划会被转换成JobGraph并提交给JobMananger执行.
简单的流程讲述完成了,我们来看下流式应用的核心,转换操作.
比如,流式转换以一个或者多个转换数据流作为输入,并转换为一个或者多个数据流
Flink应用的本质,就是一个执行多个转换,满足业务逻辑的DataFlow图.
大部分的函数都是用户自定义的,封装了用户的应用逻辑,并且在其中指定了输入流的元素和输出流的元素
比如下面的MapFunction

大部分的函数接口都是SAM类型的,支持书写Java中的Lambda函数
而自定义的函数转换,往往可以分为四类
1. 作用于单个事件的基本转换
2. 对事件的KeyedStream转换
3. 将多条数据合并或者将一条数据拆分为多条数据
4. 对流中的事件进行重新组织的分发转换.
我们接下来会详细讲下不同转换的使用
1. 基本转换,常见的转换函数有 简单的值转换,记录拆分和过滤等
比如Map,通过DataStream.map() 方法可以指定map产生一个新的DataStream,
对于每个到来的事件指定一个用户自定义的映射器,并通过映射器返回一个输出事件
抽象的可以看如下将每个方形转换为圆形
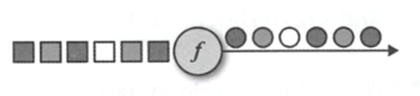
在MapFunction的实现中,有两个类型参数,分别是输入事件的类型和输出事件的类型,通过MapFunction接口来指定,
MapFuntion[T,O]
其次就是filter
作用于这个流上每一个输入事件,并返回一个布尔值来决定事件的去留
如果为true,就会保留这个输入时间,如果为false,则会将事件丢弃
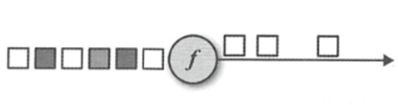
Filter函数基本如下

接口类型为输入流的类型,filter接收一个输入事件,返回一个布尔值.
FlatMap
类似filter和map的集合,对于每一个输入事件,可以产生0个或者1个,乃至多个输出事件
抽象的可以如下
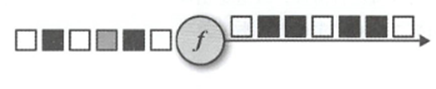
将灰色的方块丢弃,将黑色的复制,白色的不改变

2. 基于KeyedStream的转换
很多应用都需要进行分组后处理,DataStream API也提供了KeyedStream来进行数据的分流.
而且由于KeyedStream具有状态,故可以进行状态化处理.
而且KeyBy后的Stream也支持使用map,flatMap,filter进行处理
KeyBy方法接收一个用户指定分区键的参数,返回的是KeyedStream
简单的示例如下:

那么在获取一个KeyedStream 之后,我们可以对分区后的Stream进行聚合,也就是使用滚动聚合算子,滚动聚合算子会对每一个键值保存一个结果,然后每到来一个事件,都会更新对应键值的聚合结果
滚动聚合不需要用户自定义函数但需要接收一个指定聚合目标字段的参数
DataStream API提供了一些滚动聚合的方法:
Sum() 对每一个键值对流,计算其中指定字段的和
Min() 对每一个键值对流,计算其中指定字段的最小值
Max() 对每一个键值对流,计算其中指定字段的最大值
MinBy() 对每一个键值对流,计算其中指定字段的最小值对应的事件
MaxBy() 对每一个键值对流,计算其中指定字段的最大值对应的事件
除了进行聚合运算,还可以利用Reduce进行转换,在KeyedStream中利用ReduceFunction进行组合,产生一个新的DataStream
ReduceFunction中指定一个reduce函数,定义的reduce方法每次接收两个输入事件,然后再产生一个类型相同的事件.

除了能够按照键值对进行分割DataStream,
Flink还可以将一条流且分为多条流,或者将多条流合并为一条流.
Union()方法可以合并两条或者多条类型相同的DataStream,生成一个新的类型的DataStream,从而方便处理
但是需要注意,Union执行过程中,每个流中的事件会以FIFO 先进先出的方式合并,顺序无法得到任何保证,此外,union算子不会对数据进行去重,每个输入消息都会被发往下游

此外还有这Connect转换,一个DataStream方法接收一个DataStream,返回一个ConnectedStream对象

配合map和flatMap使用
分别接收一个CoMapFunction和CoFlatMapFunction函数
函数都是接收两个输入流的类型,外加上输出流的类型作为参数

需要注意,CoMapFunction和CoFlatMapFunction内的方法调用顺序无法保证,一旦有事件到来,就会调用对应的方法.
默认情况下,connect不会让两个输入流得事件之间有什么关联,这不是我们希望看到的
如果希望有确定性的处理
可以和keyBy,broadcast结合使用

无论是结合后keyBy,还是先keyBy后connect,都会有相同结果.
如果是使用广播流来进行-connect,则可以做到一个connect后的自流能够读取到另一个流的全部数据.

Split和Select
是union转换的逆操作,将一条输入流分割为两条乃至多条类型相同的输出流,
DataStream.split()需要一个OutputSelector,来定义如何将数据流中的元素分配到不同的输出中
内部的select 会传入一个对象事件,并期望获取一个包含String的迭代器,从而确定发往哪些输出流

下面就是操作,按照输入的数据,拆分为了一条大数字流和一条小数字流
