Flink的系统架构
我们这一次来讲解一下Flink的架构,并根据架构来看其如何运行解决流处理相关问题的
因为Flink是一个分布式系统,在运行过程中除了本身的计算能力,还需要保证高可用,且需要确定故障恢复等.
而Flink并没有完全实现上面的所有功能,而是将非核心功能的集群管理,持久化存储交给了其他系统负责,比如集群管理能力的YARN Kuberenetes,负责持久化能力的HDFS,S3等,并提供了相关的接入方式.
在抛开了上面那些交给外部管理的能力,Flink搭建需要的组件还有:
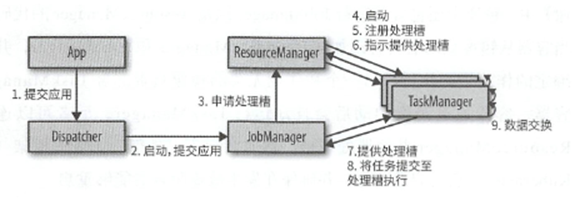
JobManager,ResourceManager,TaskManager,Dispatcher.所有组件都是由Jvm运行的.
对应的职责有:
JobManager控制着一个应用,一个计算的执行,JobManager接受一个需要执行的任务,一个应用,然后从中取出JobGraoh和其他所需的资源,并将JobGraph转换为ExecutionGraph这个Dataflow图,这个图中包含了可以执行的任务,之后JobMangaer向ResouceManager申请执行的资源,TaskManager的slot,一旦收集到了足够的slot,就会开始执行.而在执行过程中,还需要执行创建检查点等操作.
ResouceManager,这个组件依托于部署的环境,ResourceManager负责管理TaskManager的处理槽,如果有申请到来,而自己无法提供足够的slot,就会和资源提供者通信,通过启动额外的TaskManager来获取资源.
TaskManager是Flink的工作进程,提供了计算资源Slot,Slot中执行了具体任务,而且因为Flink的数据传输,不同TaskManager会产生数据交换.
Dispatcher负责在应用提交的时候,会启动一个JobManager来执行它.
具体交互图如下
三者的架构如下
关于Flink中不同组件的故障恢复
TaskManager,其提供了计算资源,如果出现了故障,那么会导致资源不足,从而Job无法继续运行,故JobManager需要向ResourceManager申请更多的处理槽.
JobManager的故障更加棘手,因为其控制流式应用的执行和元数据的保存,如果jobManager消失,就无法继续处理数据.而在高可用状态下,JobManager会将自己的的元数据写入远程存储中,并将远程存储中的路径写入Zookeeper,这样一旦JobMananger出现了故障,新启动的JobMananger可以利用Zookeeper来请求存储位置,获取JobGraph,JAR文件以及检查点再远程存储的状态句柄.
向着ResourceManager申请处理槽来继续执行应用,并依据最近的检查点来重置任务状态.
Flink的应用执行方式有两种
第一种呢,是直接提交给Dispatcher这些Flink中的组件,这样都会启动一个JobManager,并将应用转交给它,最后交给JobManager来执行这个应用.
另一种呢,是容器启动,Flink的应用会被打包到一个容器镜像,然后其中还包含着JobManager 以及 ResourceManager代码,这样容器启动后,往往还有其他镜像负责启动TaskManager来联系这个容器中的ResourceManager来提供资源.这一类的部署往往还有外部资源管理框架来负责管理镜像.诸如Kubernetes.
关于两者的实践,我们会在后文去讲解.
接下来我们聚焦Flink中真正的执行者 TaskManager,其提供了固定数量的处理槽来执行任务,这些任务可以来自于同一个算子(数据并行),来自于不同算子(任务并行),来不同的应用(作业并行)
而一个Slot中,并不是只会存在一个算子,往往是根据JobGraph来包含多个算子,比如下面的graph
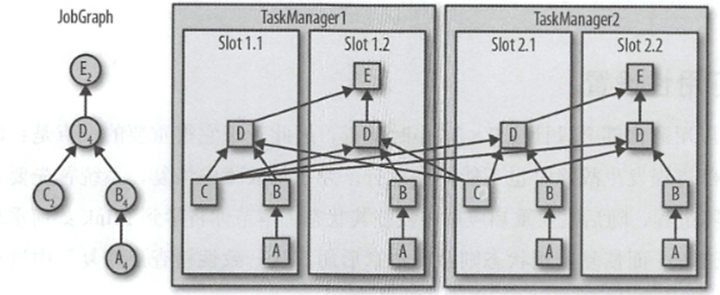
Graph中存在5个算子,C E的并行度为2,其他的为4,那么算子的最大并行度为4,故需要4个处理槽.
如果一个TaskManager中有两个处理槽,那么运行两个TaskManager即可.
然后JobMananger讲任务展开分配到4个Slot中,并行度为4的算子,每个槽中都会分配一个.对于并行度为2的,会只存在于两个处理槽中.
一个TaskManager是一个JVM,内部的Slot都存在于一个JVM下,如果有一个任务异常,可能导致整个TaskManager的卡死.但是Flink提供了灵活的配置,支持一个TaskManager只运行一个任务,提供一个槽.