这次我们讲解一下Kafka的精准一次处理语义
首先我们确定常见的三种交付语义分别是
最多一次 at most once 消息可能丢失,最多只会被处理一次
最少一次 at least once 消息不会丢失,可能被处理多次
精准一次 exactly once 消息会被处理,且只会被处理一次。
当然,这三者的实现,需要大家根据实际的业务需求来确定,对于大量的日志数据,完全是没有必要使用exactly once的。
那么对于这三个交付语义,我们从consumer和producer两个角度来说,
对于at least once,producer发送消息后,假设网络出现故障没有响应,生产者很有可能再次发送消息,导致一条消息被发送多次,这一点,producer是天然的at least once
对于consumer端,不同语义的实现是根据consumer的提交时机确定的,如果consumer在消息处理完成才提交,那么就是at least once,如果是在处理之前就提交,那么就是at most once。
而精准一次,则需要依赖于新版本引入的事务。
而幂等性则是实现EOS的一个利器,Kafka为了实现幂等性,则是采用和TCP类似的工作方式,发送到broker端的每批消息都会赋予一个序列号,方便消息去重,这个序列号会被kafka保存在日志中,保证高可用,
其次是Kafka为每个producer实例分配了一个producer id,分配了一个PID,从而形成了一个Map
Map的Key是(PID,分区号),value为序列号,那么如果新来了一条数据,如果消息的序列号小于或者等于序列号,那么就拒接这次写入操作。
如果出现了重试操作,也会保证日志只记录一次。这就是producer端的消息去重。
对于整体的事务
是引入了一个唯一的id来表示事务,这个id是事务id,在所有的会话都是唯一的。
提供了TransactionaId,Kafka就可以确保
这个TransactionaId是由用户设置的,和PID不同的是,PID是Kafka内部分配的
故Producer不提交的事务,Consumer不会消费到
但是consumer角度来说,其可能遇到log segment被删除了,
Consumer可以使用seek方法来定位事务中的任意消息的情况。
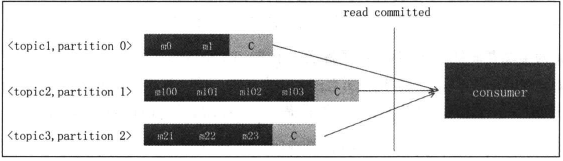
而且Kafka引入了一类特殊消息,即控制消息control message,事物控制消息和普通Kafka消息一样,都是在消息属性中标记是不是control message.内部分为了两个类型,COMMIT,ABORT,表示事务提交和事物终止。方便consumer识别事物边界,读取下面所有的消息
并在Kafka内部引入了新组件和新的内部topic
Transaction Coordinator
负责保存producer的事务状态,内部引入了一个新的topic,类似__consumer_offsets topic
这个组件来存储事务的最新状态,事物的状态和OnGoing,Prepare commit,Completed
而且每个transactional.id通过hash来对应的transaction log的一个分区,从而确定对应的broker.
Kafka提供了5个事务相关方法
initTransactions()**方法用来初始化事务,这个方法能够执行的前提是配置了transactionalId,如果没有则会报出IllegalStateException:
beginTransaction()**方法用来开启事务;
sendOffsetsToTransaction()**方法为消费者提供在事务内的位移提交的操作;
commitTransaction()**方法用来提交事务;
abortTransaction()**方法用来中止事务,类似于事务回滚。
而消费端的配置,可以配置isolation.level级别,分别为read_uncommitted和read_committed,分别来看到未提交的消息和已经提交的消息。这一点也是根据上面的控制消息来实现的。根据上面的消息来判断事务是否提交还是中止,从而将对应的消息返回consumer.
基本的api顺序调用为
| Producer.initTransactions();
Try{ Producer.beginTransaction(); Producer.send(record); Producer.send(record1); Producer.commitTransaction(); }catch (KafkaException e){ Producer.abortTransaction(); } |
首先是在initTransactions的时候,会将自己注册到transaction coordinator。然后这时候会关闭所有相同transaction id但是还在pending的事务。
其次是发送消息,这时候会先发送消息给transactional coordinator,保存诸如transaction id和partition的关系,然后producer 按照正常流程发送消息到目标 topic。
最后是提交或者回滚消息。这里采用了二阶段提交,第一阶段是“prepare_commit”,先记录进transaction log
然后写入控制消息到目标topic的目标partition,分别表示事物已经提交或者已经终止。
之后写入transaction log更新事务状态为 “commited” 或 “abort”。
最后我们给一个事物使用的基本代码:
| public static void main(String[] args) {
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(new Properties()); consumer.subscribe(Arrays.asList(“topic_source”)); KafkaProducer<String,String> producer = new KafkaProducer<String, String>(new Properties()); //初始化事务 producer.initTransactions(); while (true) { ConsumerRecords<String, String> message = consumer.poll(Duration.ofMillis(1000)); if (!message.isEmpty()) { Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>(); //开启事务 producer.beginTransaction(); //遍历消息所在的分区 try{ for (TopicPartition partition : message.partitions()) { //获取指定分区的消息信息 List<ConsumerRecord<String, String>> records = message.records(partition); //遍历每一个分区拉去的消息 for (ConsumerRecord<String, String> record : records) { //这里可以做,一些数据转换逻辑 //组装发送消息 ProducerRecord<String,String> producerRecord = new ProducerRecord<>(“topic-sink”,record.key() ,record.value()); //消费->生产 producer.send(producerRecord); } //获取提交的offset值 long lastConsumerOffset = records.get(records.size() – 1).offset(); offsets.put(partition,new OffsetAndMetadata(lastConsumerOffset)); } //提交offset记录给事务 producer.sendOffsetsToTransaction(offsets,”group_id”); producer.commitTransaction(); }catch (Exception e){ //log //出现异常,终止事务 producer.abortTransaction(); } } } } |
最后要使用事务,需要的配置为:
producer 配置项更改:
enable.idempotence = true
acks = “all”
retries > 1 (preferably MAX_INT)
transactional.id = ‘some unique id’
consumer 配置项更改:
根据需要配置 isolation.level 为 “read_committed”, 或 “read_uncommitted”;