本章我们希望通过讲解broker和client之间的通信,来串联Kafka不同功能的实现。
Kafka客户端和broker传输数据的时候,需要创建一个特定的Socket连接。然后分别按照规定好的请求和响应进行传输。而这样的一条Socket,会成为一条长连接,从而减少建立TCP的开销。
对于broker段,只需要维护一个Socket,进行数据的传输
对于client,则是创建多个Socket,进行网络传输,包括不同的broker,元数据获取,然后在之上利用了epoll的方式来进行轮询传输数据。
基本的请求和响应结构都是相似的,都包含了Size + Request/Response
Size是一个int32的正数,表示了这个消息的整体长度。
而Request中,基本分为了请求头和请求体,请求头结构基本固定,api_key 请求类型
Api_version 请求版本号
Correlation_id 响应的关联号,用于关联response和request,方便用户调试和排错。
Client_id 发出这个请求的client ID,区分不同集群client发出的请求。
响应中虽然也分为了头部和响应体,但是请求头中结构是非固定的,只有下面的字段
Correlation_id,用于管理request和response。
请求类型:
多达38个,不过我们会讲解一些比较重点的。
PRODUCE请求:
具有6个版本,最新版本格式为 事务Id + acks + timeout + topic[数据]
事务ID 为了支持事务而引入的字段
Acks 返回响应之前,需要保存好的broker个数。
Timeout 请求超时时间
Topic 数据,是一个数组,包含了topic + [partition + 消息集合]
Topic表示要发到哪些topic
Partition 表示发到topic的哪些分区
消息集合则是真正的消息。
PRODUCE的请求:
包含了[response+ throttle_time_ms]
throttle_time_ms 超过配额限制而延迟该请求处理的时间
response则是每个topic对应的返回数据,基本包含
partition 分区号
error_code 请求是否成功的code
base_offset 消息集合的起始位移。
Log_append_time broker端写入消息的时间
Log_start_offset response被创建时该分区日志的总起始位移。
其次是FETCH的请求和响应
存在于clients向着broker发送的FETCH请求,follower发给leader的FETCH请求。
FETCH具有7个版本,最新的版本中,请求格式为 replica_id + max_wait_time + min_bytes + max_bytes + isolation_level + [topics]
其中 replica_id 副本id,在follower向着leader发送消息的时候使用,如果是client发给broker的话,字段为-1.
max_wait_time 等待响应返回的最大时间
min_byte,max_bytes 分别代表这次FETCH携带的最小最大bytes数量
isolation_leve,隔离级别,用于事务
topic数组中包含了要请求的topic数据
其中一个元素包含 topic,分区信息,分区信息中又包含partition,fetch_offset,log_start_offset和max_bytes,其中fetch_offset是从哪个唯一开始读取消息,也是用于上面HW的同步的。
响应格式为 throttle_time_ms + [response]
其中重点是response,内部包含topic,以及消息集合。
METADATA请求:
基本格式为 [topics] + allow_auto_topic_creation
allow_auto_topic_creation 表示是否可以自动创建topic
topics则是需要获取元数据的topic数组
响应的格式为 throttle_time_ms + [brokers] + cluster_id + controller_id + [topic_metadata]
Brokers 包含了其中每个broker的详细信息,包括节点ID,主机名等信息
Cluster_id 集群ID
Controller_id 集群controller所在的broker ID
Topic_metadata,topic元数据组,包含了请求topic的所有元数据,比如
Topic_error_code topic错误码
Topic 名称
Partition_metadata topic下所有分区的元数据,每个分区的错误码,leader信息,副本信息,ISR信息。
整体的流程
对于clients段,基本流程如下
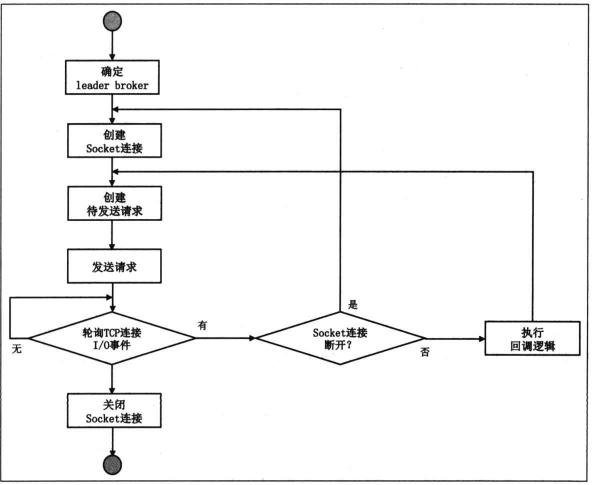
大部分的请求是发给特定的broker的,比如PRODUCE和FETCH,部分例如METADATA可以发给任意一个broker,因为每个broker都保存了相同的元数据信息。
对于broker端,处理逻辑要简单的多。
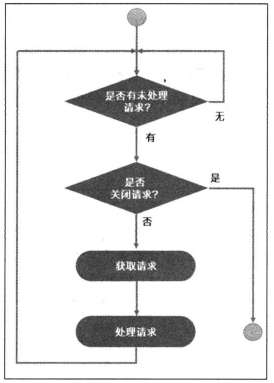
Broker会创建一个阻塞队列,专门接收clients发来的请求,然后由多个请求线程来处理这个阻塞队列中的请求。内部还引入了毒丸机制,即队列中获取到了一个特定的标记,就会终止自己的循环处理逻辑。
然后对于上面的版本,是需要考虑不同版本的兼容性
对于当前版本的broker所支持的版本,可以通过相关命令来查看的
Bin/kafka-broker-api-version.sh –bootstrap-server localhost:9092