对于K8S如何对Pod进行调度的
我们根据不同的可配置方向进行分类,并进行讲解
1. nodeSelector
nodeSelector是我们节点选择约束的最简单方式
使用nodeselecotr,可以配置对应的节点标签,然后将pod调度到包含这个标签的node上
比如下面的yaml
| apiVersion: v1
kind: Pod metadata: name: “MYAPP” namespace: default labels: app: “MYAPP” spec: containers: – name: MYAPP image: “debian-slim:latest” nodeSelector: gputype: amd |
在上面我们就声明了需要选择包含标签为gpu类型为AMD的Node
而且往往K8S集群会给Node填充一些标准的标签,不过可能由于云供应商的不同,并不一定保证一致
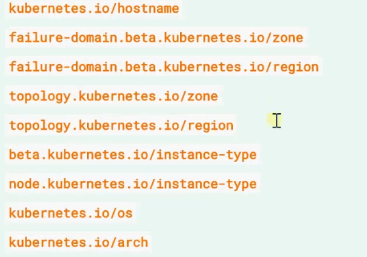
除此外,有一种直接分配Pod的方式
就是在spec中声明nodeName字段,这样Pod会直接分配到node上,但是我们一般不用
其次是更加常用的,Affinity和 anti-affinity 亲和和反亲和
也就是Pod到底去哪些机器,由Scheduler根据我们声明这些亲和和反亲和来调度到Pod喜欢的机器上
具体的声明在pod.spec.affinity中,如果我们直接使用explain来进行查看
会发现,其中的可选字段有三项
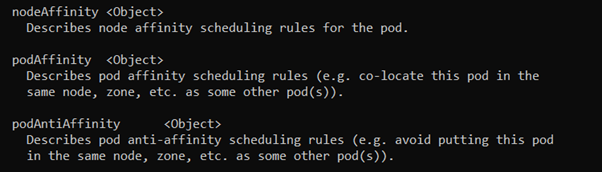
分别是节点的亲和性,Pod的亲和和反亲和,我们将会按照顺序来依次说明这三个选项.
首先是NodeAffinity
是Node Selector的升级版,增加了根据节点属性来确定调度到哪些节点
引入了运算符 In NotIn
增加了硬性条件和软性评分机制
我们首先查看对应的explain信息
| KIND: Pod
VERSION: v1 RESOURCE: nodeAffinity <Object> DESCRIPTION: Describes node affinity scheduling rules for the pod. Node affinity is a group of node affinity scheduling rules. FIELDS: preferredDuringSchedulingIgnoredDuringExecution <[]Object> The scheduler will prefer to schedule pods to nodes that satisfy the affinity expressions specified by this field, but it may choose a node that violates one or more of the expressions. The node that is most preferred is the one with the greatest sum of weights, i.e. for each node that meets all of the scheduling requirements (resource request, requiredDuringScheduling affinity expressions, etc.), compute a sum by iterating through the elements of this field and adding “weight” to the sum if the node matches the corresponding matchExpressions; the node(s) with the highest sum are the most preferred. requiredDuringSchedulingIgnoredDuringExecution <Object> If the affinity requirements specified by this field are not met at scheduling time, the pod will not be scheduled onto the node. If the affinity requirements specified by this field cease to be met at some point during pod execution (e.g. due to an update), the system may or may not try to eventually evict the pod from its node. |
上面分别有
preferredDuringSchedulingIgnoredDuringExecution和requiredDuringSchedulingIgnoredDuringExecution
两个字段,分别对应着软性打分和硬性要求
字段的名字代表了意味着调度期间考虑,但是运行期间不考虑,也就是对于硬性要求,如果运行期间不满足了,也不会触发调度了
我们来根据对应的yaml来查看字段的选择
| affinity:
nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: – matchExpressions: – key: disktype operator: In values: – ssd – hdd |
上面就表示我们选择硬性要求为labels为disktype=ssd或者hdd的node
除了这个,可以选择的operator还有NotIn,对应的label不是hdd或者ssd就行
Exists,只要存在disktype这个标签就行,值是什么无所谓
DoesNotExist 只要不存在这个disktype标签就可以
Gt 如果标签值是数值的,选择大于的
Lt 小于的
而对于preferredDuringSchedulingIgnoredDuringExecution
则是引入了权重机制
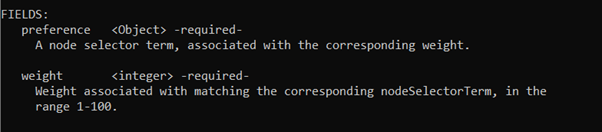
其中的preference和上面的nodeSelectorTerms类似
Weight则是声明了一个int类型的数值,表示权重,越大优先级越高
| preferredDuringSchedulingIgnoredDuringExecution:
– preference: matchExpressions: – key: cpunumber values: – 16 operator: Gt weight: 90 – preference: matchExpressions: – key: gpu values: – 2080 operator: Gt weight: 20 |
这样基本的权重就设置了
交给Scheduler根据权重大小,选择匹配的Node调度
其次关于Pod相关的配置,即亲和Pod与反亲和Pod,关于这两点的配置,我们一齐讲了
比如我们有一个需求,就是在一个多节点的集群上,部署一个使用redis的网页应用程序,并且希望web-server尽可能的和redis的在一个节点上,而应用程序尽可能的分布在不同节点上
而在部署web-server之前,我们需要先部署redis
首先在redis之中,我们需要考虑要在集群范围内尽可能的分布广
所以首先需要pod中的反亲和,要求彼此冲突
那就是首先是podAntiAffinity中的requiredDuringSchedulingIgnoredDuringExecution
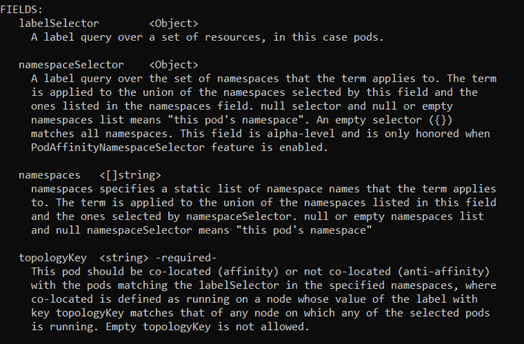
支持labelSelector namesapceSelector namespaces topologyKey
其中namespaceSelector和namespaces的区别在于, namespaces是指定一个数组,其中包含了namespaces的名称,而namespaceSelector支持更多的表达式
而我们需要用到的主要是labelSelector及topologyKey(拓扑键)
| affinity:
podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: – labelSelector: matchExpressions: – key: app values: – redis operator: In |
在书写了反亲和之后,还需要注意,在Pod亲和反亲和策略中,还需要书写拓扑键
表明不同的作用域
我们以 – topologyKey: “kuberentes.io/hostname”
这个node的注解进行划分作用域,做到了基本上是一个Node一个作用域了
对于拓扑键,如果是亲和就是考虑都放在一个作用域上,如果是反亲和,就是考虑放在不同的作用域上
其次是web服务器Pod,对于这个Pod的部署,是在Redis部署之后的进行的
这就要求,即要分布均匀,还要和Redis亲和
那么我们就首先写一个Pod亲和,表示和Redis亲和
| podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: – labelSelector: matchExpressions: – key: app values: – redis operator: In – topologyKey: “kuberentes.io/hostname” |
这样就以hostname为作用域,进行对Reids的亲和了
但是我们上面说了,拓扑键对于亲和的话,就是考虑放在一个作用域上
所以我们还需要声明一个反亲和,声明彼此对立
这就保证了web-server的分布均匀,又能保证和Redis贴合
之后,是关乎Pod的污点机制
为什么Master节点能保证不调度Pod呢?就是源于了K8S打上了对应的污点,从而避免了调度
就好比,买车的时候,会做出一些抉择,表示自己能够容忍某些车的缺陷
对应到K8S中,就是Pod在被Scheduler判断可调用的时候,如果Node上有污点,就看Pod是否能够容忍这些个污点,如果可以,Pod就可以调度上去
如果Node上有多个污点,就需要容忍多个
我们可以首先来看下Master节点上打的污点
Kubecetl describe node master
其中就包含了Taints一栏
![]()
污点写法 k=v:effect
其中k,v是用户自定义的,而effect则是包含了NoSchedule/PerferNoSchedule/NoExecuter
分别的含义是
NoSchedule 不调度
PerferNoSchedule 比NoSchedule更宽容一些,Kubernetes尽量避免将没有匹配容忍的Pod调度到这个节点上
NoExecute 不仅是不调度,而是不允许任何Pod在节点上运行
所以,这个命令为节点node1添加了一个污点
Kubectl taint nodes node-1 why=kkk:NoSchedule
如果是移除某个污点,则可以
Kubectl taint nodes node-1 why:NoSchedule-
而K8S会默认给Node进行打污点,触发的条件也不尽相同

而对于Pod上,可以进行打标记来容忍一些污点
处于kubectl explain pod.spec.tolerations下
可以进行的配置有
Key value operator effect
比如我们可以容忍一个
Tolerations:
– key: “why”
operator: “Exists”
effect: “NoSchedule
甚至可以不定义key,只指定了operator为Exists,这样匹配所有污点
Tolerations:
– operator: “Exists”
或者定义了key,不定义effect
容忍这个key所有的effext
最常见的一种方式就是
当K8S给一个Node打上node.kubernetes.io/network-unavailable的时候,很有可能只是网络抖动
这时候直接杀死Pod有些霸道,这时候我们就可以打上一个容忍的最大时间
就是其中的tolerationSeconds
再之后就是关于我们之前讲过的拓扑键的进化版
Pod中的topologySpreadConstraints字段
目的是管理拥有大量节点的集群网络分布图,用于规划整个集群的资源
https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-topology-spread-constraints/
我们最好根据事例使用来讲解其原理
kubectl explain pod.spec.topologySpreadConstraints
会发现起具有maxSkew\ topologyKey\ whenUnsatisfiable\ labelSelector四个字段

我们首先使用toplpgyKey进行分区,这一点和上面说的拓扑键使用方式一致
进行了分区之后,利用labelSelector来进行选择Pod
之后利用maxSkew来声明不同分区之间最大的数量偏差,即如果A区域有了两个Pod,而我们声明最大的偏差不能超过1个,那么B区域如果现在只有一个,那么新Pod必然要分配到B上,不然分配到A上,B和A的偏差就大于1个了
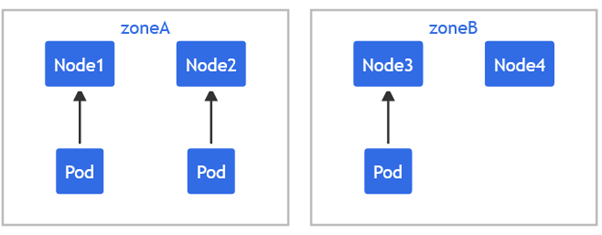
正如上面所说,我们有两个可用区
| kind: Pod
apiVersion: v1 metadata: name: mypod labels: foo: bar spec: topologySpreadConstraints: – maxSkew: 1 topologyKey: zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: foo: bar containers: – name: pause image: k8s.gcr.io/pause:3.1 |
并且声明了一个Pod,那么这个Pod的topologySpreadConstraints中声明了我们利用zone进行分区
并且最大偏差为1,最后还有一个上文没有说明的字段 whenUnsatisfiable,表示当新来的Pod实在无法找到合适的分区的时候动作
可选择为不要调度和降低偏差值
而且还可以根据Affinity相关规则进行匹配使用