即散列值的范围在0-M,把大小为M的数组中每一个索引下都对应一个链表
然后依次把键值放在对应散列值的链表中,一个链表中可以存在多个键值对
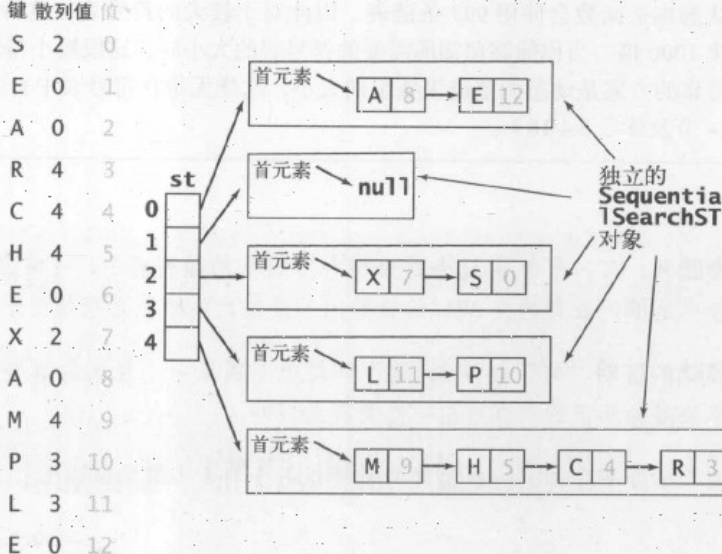
链表的平均长度为N/M
简单的实现代码如下
|
public class SeparateChainingHashST <Key,Value>{
private int N;//键值对数量 private int M;//散列表的大小 private SequentialSearchST <Key,Value>[] st;//数组 public SeparateChainingHashST() { this(997);//默认997个 } public SeparateChainingHashST(int i) {//创建链表 this.M = i; st = (SequentialSearchST <Key,Value>[])new SequentialSearchST[i]; //创建一个链表数组 for(int j =0;j<st.length;j++) { st[j] = new SequentialSearchST();//对应创建链表 } } private int hash(Key key) {//hash值计算 return ((key.hashCode()&0x7fffffff)%M); } private Value get(Key key) {//获取值 return (st[hash(key)].get(key));//调用链表查找 } private void put(Key key,Value val) {//输入 st[hash(key)].put(key, val); } } |
还有着改进方式,就是增加为动态数组的方式,进行动态的扩容
从算法上我们可以看出来,这个算法极其依赖散列函数是否是均匀的
但是在实际应用中,散列表中的高性能并不需要散列函数完全符合均匀性,依旧能够高效的提高性能
对应的删除操作
要删除一个键值对,先使用散列值找到含有含有该键的链表对象
然后直接调用对象的delete对象
但是因为散列表的格式,所以对于有序性来说,他不是一个好选择
(比如,快速找到最大,最小键,查找范围的键)
但刨去有序性,只要是键的顺序不重要的应用中,其可能是最快的(也是应用范围最广的)