RocksDB是Facebook开源的一个高性能持久化KV存储,很少有RocksDB在生产环境来保存数据,在未来,RocksDB也不会像Redis那样直接被使用
但是很多新生代的数据库会选择使用RocksDB来作为存储引擎,例如 MyRocks,就是利用RocksDB来给MySQL做后端存储引擎,取代现有的InnoDB存储引擎,并且MySQL的亲兄弟MariaDB已经可以使用Rocks了,再者说,Flink,Flink的State就是一个KV存储,也就是RocksDB,还包括MongoDB,Cassandra等数据库,都有基于RocksDB的存储引擎
那么,其和Redis有何区别?
两者本质上完全不一致,一个是缓存,一个是存储系统,Reids作为一个内存的缓存,读写的性能在50万次/秒,RocksDB的随机读写性能在20万次/秒,性能不如Redis,但是也是一个量级的了
RocksDB作为一个存储引擎,比起Redis,还需要进行保存在磁盘上,在加上这个桎梏还能做到这种性能,就是价值所在
Rocks在保证数据持久化的前提下,还能如此高的性能,说明其整体架构和存储结构上有过人之处
Rocks对于存储设计了一个非常复杂的数据存储结构,此结构整合了内存和磁盘混合的模式,利用磁盘来保证数据恢复,利用内存提升读写
比如,我们往B+树中写入一条数据,必须按照B+树的排序,按照B+树的排序,写到固定的某个节点下
这样编写方式,导致我们的数据录入的时候,可能导致录入的数据是随机写,RocksDB利用了自身精妙设计,避免了随机写,这就是高性能写入的根本原因
其数据结构为LSM-Tree
如何兼顾的读写性能,LSM-Tree的全称,The Log-Structured Merge-Tree,非常复杂的符合数据结构,包含了WAL 日志 , 跳表 SkipList 分层的有序表SSTable Sorted String Table
下面就是LSM-Tree
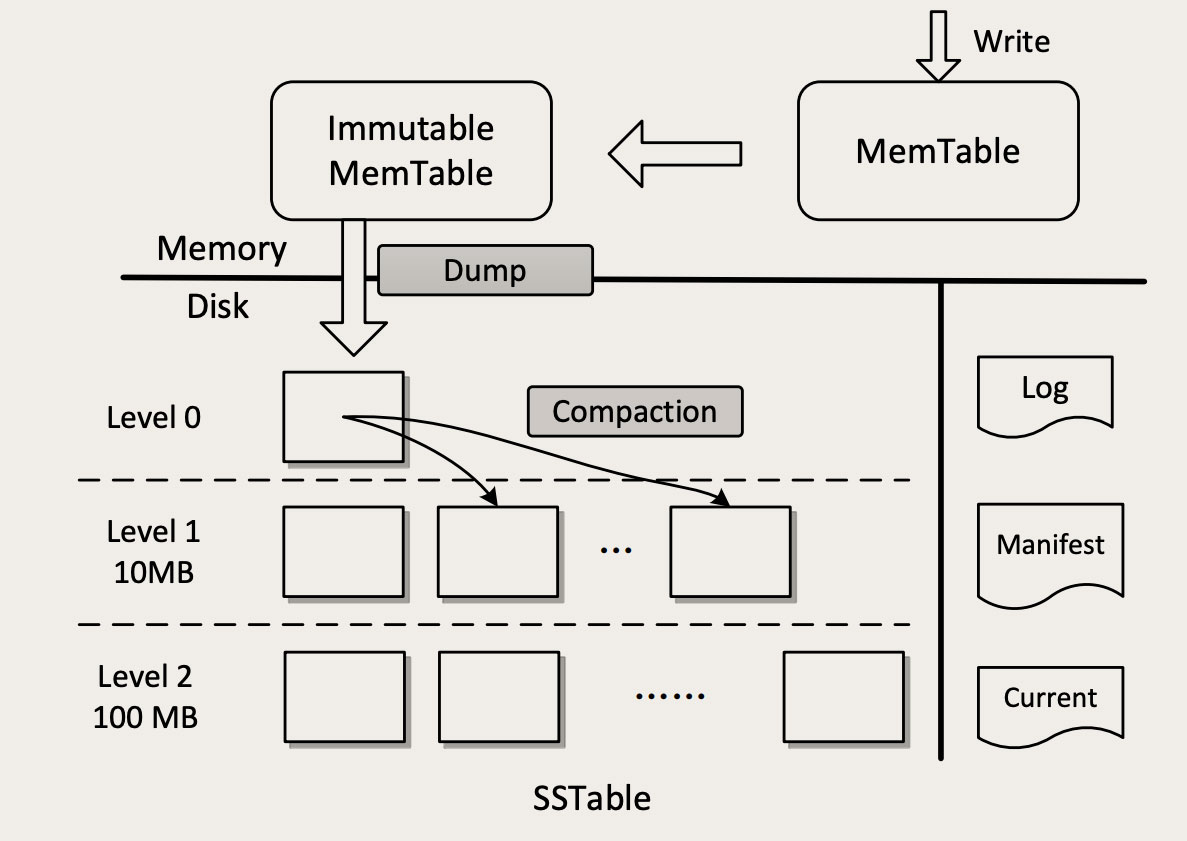
本质上比这个图更加的复杂
但是我们简单的复述下存储的流程,假设,收到了一个写请求,比如PUT foo bar,将Key foo的值设置为bar,这条命令会被写入磁盘的WAL日志,顺序写磁盘的操作,性能很好,日志的唯一作用是用于故障恢复,一旦系统宕机,就可以将日志中内存还没有来得及写入磁盘的数据恢复出来,这还是复制状态机的理论
写完日志之后,数据可靠性就解决了,然后希尔内存的MemTable中,这就是跳表,这个写入是一个内存操作,写入后就直接返回成功了,这个写入操作也不校验Key是否存在,而是直接尝试写入
然后写到MemTable的存储上限,一般32M,就转换为Immutable MemTable,然后创建一个新的MemTable,Immutable 利用了不变性,不允许再写入
一旦转换为了Immutable Memtable的话,就存入磁盘文件,利用跳表的有序性,来将保证内存写入文件,是一个有序的顺序写操作,转换为了SSTable
但是这些SSTable本身有序,但是文件之间无序,所以还有一个分层合并机制
SSTable被分为了很多层,越往上,文件数越少,越往里,文件数越多,每层的容量有一个固定的上限
,每层写满了,就会往下一层合并,数据合并了之后,本层的SSTable就可以删除了,合并的时候,也是排序的时候,内部数据有序,方便查找
对于LSM-Tree的查找,查找也是分层查找,先去MemTable和0层,然后依次往下层查找
找到了就直接返回,但是这种方式有利于对数据的加热处理
因为最经常读写的Key大概率在内存中,不用读写磁盘就能完成查找,也不用穿透很多层SStable才能查找到最底层
还能利用布隆过滤器来避免无所谓的查找
总结一下
RocksDB是一个高性能持久化的kv存储,很多新生代的数据库都将其作为存储引擎,RocksDB在保证不错的读性能的前提下,提升了写性能,得益于其数据结构LSM-Tree
LSM-Tree利用混合内存和磁盘的多种数据结构,将随机写转换为顺序写来提升写性能
这种数据结构适合写入性能的优化,适合交易类场景
关于LSM-Tree的删除,如何实现的呢?
必然先去写日志,然后写入删除的缓存,然后同步到实际的SSTable中