微博内部的业务场景中广泛的使用了Redis,这一次,我们希望通过微博的Redis经验,更好的掌握和应用Redis
我们来看下微博业务需求场景,微博的业务很多,比如红包数,音乐榜单等信息,这些业务面临的用户体量非常大,业务级别很可能达到TB的级别
对于这些需求,我们简单总结一下
需要可以提供高性能 高并发的读写访问,保证读写延迟低
能够支持大容量存储
可以灵活扩展,快速扩容
针对这些需求,微博对Redis做了大量的优化改进,即增加了对Redis本身数据结构 工作机制的改进,也基于Redis自行研发了支持大容量存储的RedRock和实现服务化的RedisService
那么我们也分别按照对Redis本身数据结构/工作机制的改进和自行研制的额外服务两个方面,讲解微博实现的Redis
1.Redis本身数据结构和工作机制的改进
其主要的方向是避免阻塞和节省内存,对于常见的阻塞问题,在Redis官方还没推出RDB+AOF配合的机制之前就推出了混合使用的机制
将写文件和刷盘分离开来,异步刷盘
增加了aofnumber配置项,设置AOF的文件数量,控制AOF写盘的总文件数量,避免写入过多的AOF日志文件导致磁盘写满问题
在主从复制机制上,使用独立的复制线程进行主从库同步,避免主线程的阻塞影响
其次是定制化数据结构,增加了LongSet数据结构,存储Long类型的集合,底层元素是一个Hash数组,设计LongSet类型的主要目的就是替换Hash类型,避免保存大量数据导致的内存空间消耗较大
2.修改了Redis的一些服务
因为需要Redis保存大量缓存数据,所以为了满足大容量存储需求,还将RocksDB和硬盘结合使用,扩大了单实例的容量
因为微博的业务场景中,数据的热度是很重要的一个属性,那么海量的用户访问这些热度高的话题时候,就希望直接从内存中读取,对于一个过了热度的话题,访问人数就会急剧下降,这些数据就变成冷数据了,利用RocksDB的机制,可以直接保存在硬盘中,因为这个冷热分离的机制,单个实例的容量就直接上去了
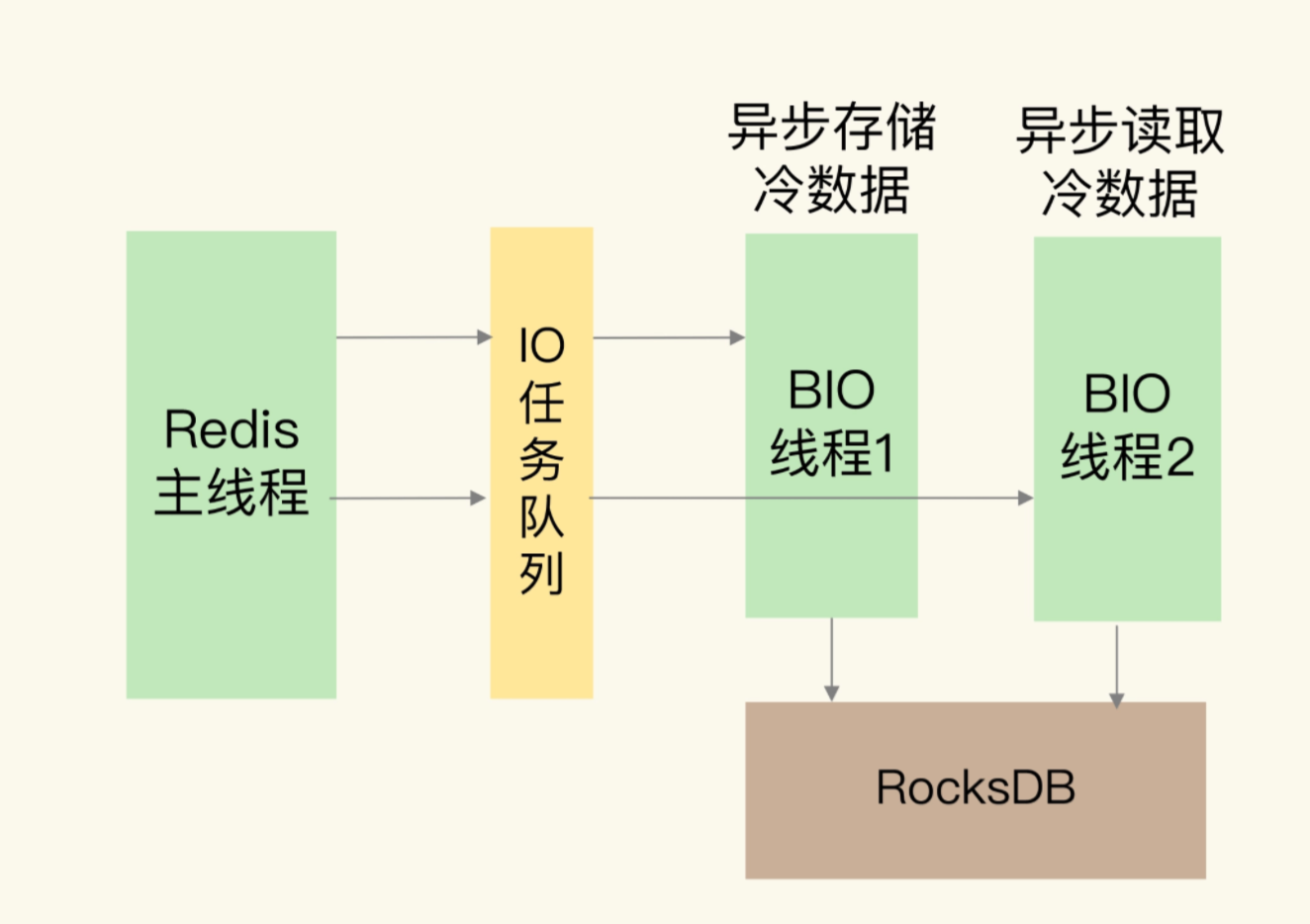
对于冷数据的读取,整体流程如上,使用了异步线程在RocksDB中读写数据
而RocksDB面对的实际的硬盘存储,也是借助了高速的SSD进行实现
对于这一点,我们总结一下,实现大容量的单实例在某些业务场景下是有需求的,其次对于大容量的Redis实例,可以考虑借助SSD和RocksDB实现
除了更改为了大容量的集群外,不同的业务对Redis容量的需求不一样,那么微博对Redis进行改造,改为了RedisService,利用Redis集群来服务不同业务场景需求,每个业务具有独立的资源,对于不同的业务上线还是下线,都可以从资源池中申请资源,或者将不用的资源归还到资源池中
Redis服务化的时候,采用了类似Codis的方案,通过集群代理层来链接客户端和服务器端,其在代理曾实现了丰富的服务化功能支持
那么客户端链接监听和端口自动增删
Redis协议解析,确定需要的路由,查看是否是非法和或者是不支持的请求
请求路由,根据数据和后端实例映射关系,将路由信息到对应的后端实例处理
指标采集监控,采集集群运行的状态,发送到专门的可视化组件,交由这些组件进行监控处理
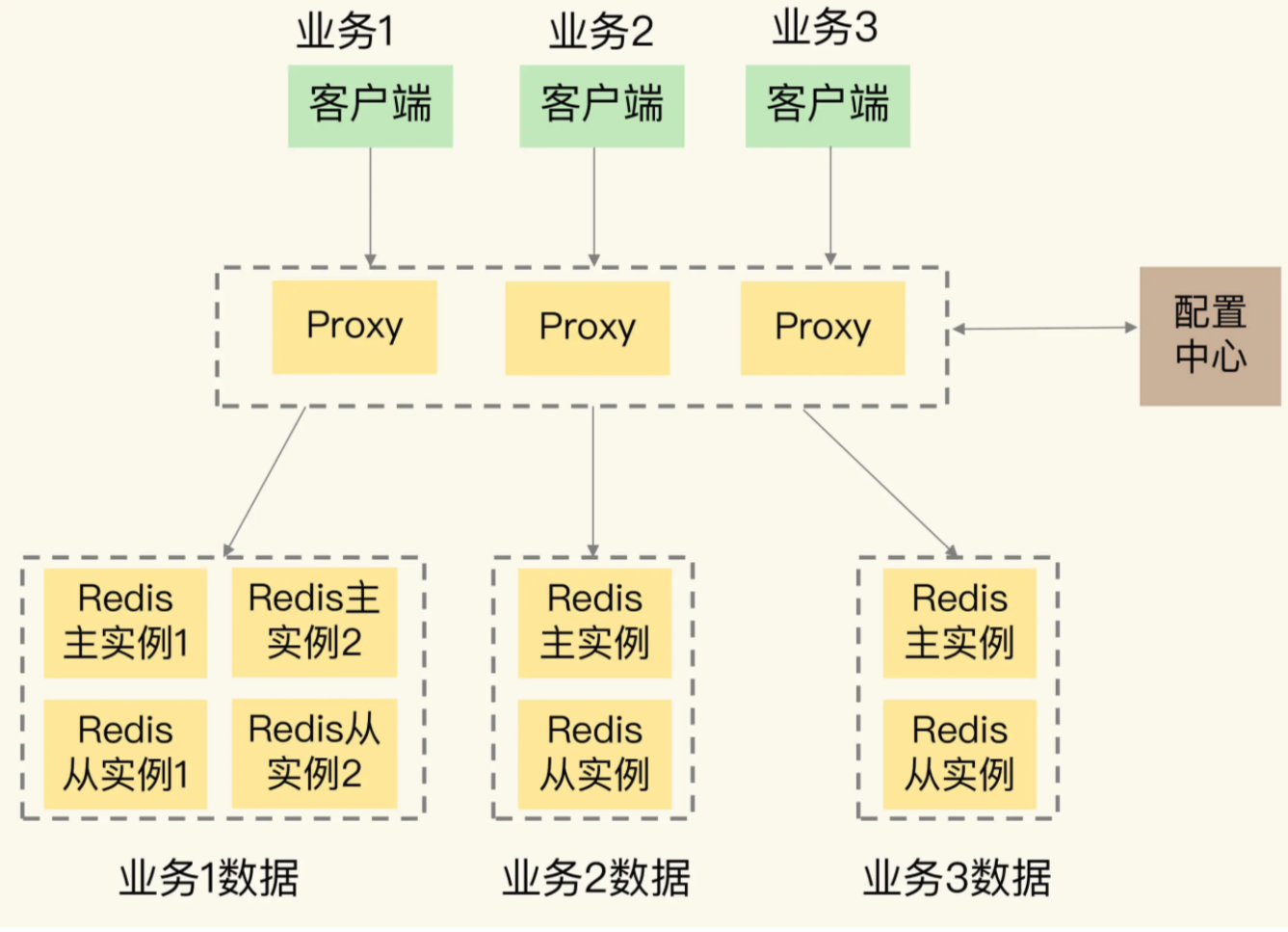
当有多个业务线有共同的Redis使用需求时候,提供平台级服务是一种通用方法,就是服务化
如果需要进行平台扩容,可以考虑借助Codis或者Redis Cluster实现,实现多租户和资源隔离,可以考虑通过proxy代理完成这个需求
总结一下本章
我们通过weibo的Redis实践,总结一些微博对Redis的计数需求,总结为高性能,大容量,易扩展
微博在对Redis进行优化之外,还自研扩展系统,基于RocksDB的容量扩展,和服务化的RedisService集群