32.Redis的脑裂
使用集群的时候,如果有一主多从的集群出现了链接故障,就可以出现脑裂问题
所谓的脑裂,就是在主从集群中,如果有多个节点都能接收写请求,导致数据丢失的问题,那么我们就从脑裂的原因说起,最后说如何应对脑裂
为何发生了脑裂呢?
常见的原因就是主库的数据没有同步到从库,但是从库升级到了主库之后,同步的数据就丢失了,比如下面就是新写入的数据a:1 b:3,主库在故障之前没有同步到从库而丢失了:
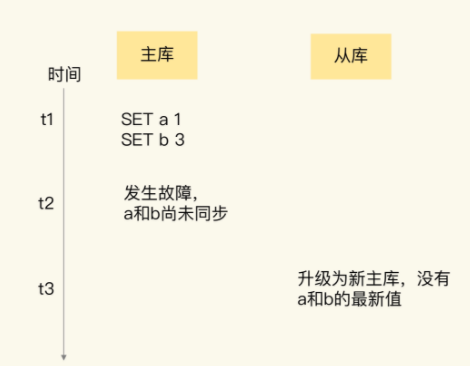
这种情况出现的可能1就是,主库上的master_repl_offset和slave_repl_offset有差值,导致了对应的数据丢失
但如果主从库的数据保证了一致,为何还会出现客户端发送的数据丢失呢?
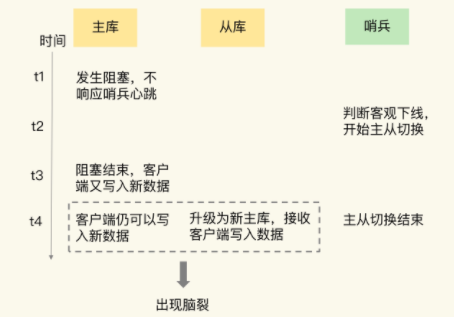
对于之后的问题,我们可以在客户端发现,在主从切换后的一段时间后,有客户端在和之前的老主库进行沟通,这就导致了一个集群中有多个主节点,导致了脑裂问题
而且在后续的日志中,可以看出来,原本的主节点还是跟随了新节点,导致完全同步了新节点的数据,导致了数据丢失.
那么为何原本的客户端还可以链接到之前的主节点呢?是否是主库并没有发生故障,而是由于某些原因没有处理请求,也没有响应哨兵的心跳,导致被下线了,而在之后,原主库又开始处理请求,哨兵已经选择了新主库,导致了上面问题的出现
我们可以通过原主库的日志来验证我们的猜想,应该可能出现了一些CPU被大量占用,导致一段时间没有回应心跳请求
这就导致我们出现了脑裂问题
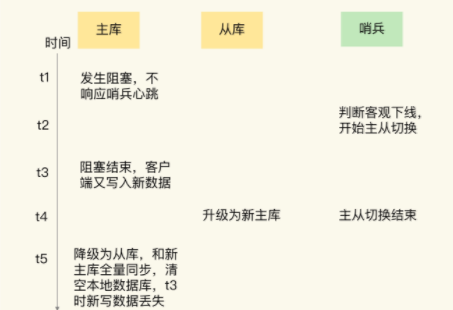
那么这个脑裂出现的原因就很明显了,从库一旦升级为了主库,哨兵会让原本的主库执行Slave of 命令,进行全量同步,在全量同步的最后阶段,原本主库需要清空本地数据,这样就导致了主从切换期间的数据丢失了
那么如何应对Redis的脑裂问题呢?
可以考虑从配合上来限制主库接收请求,对应的Redis配置项有min-slaves-to-write和min-slave-max-lag
min-salves-to-write:这个配置项设置了主库能够进行数据同步的最少从库的数量
min-slaves-max-lag,配置项设置了主从库之间的数据复制时候,从库给主库发送ACK的最大延迟(以秒为单位)
对于实际的使用,可以将min-salves-to-write和min-slaves-max-lag两个配置项搭配使用
利用这两个设置,确保自己在假故障的时候无法响应哨兵心跳,无法和从库进行同步,然后就不处理客户单请求,保证客户端不能在主库中写入新数据了
这样,等到新主库上线后,新写入的数据直接写到新主库中,原本的主库被降为从库,保证了不会有数据丢失
具体的配置可以参考如下
将min-salves-to-write设置为1,然后将min-slaves-max-lag设置为12,将哨兵的down-after-millisecond设置为15,这样我们主库出现了问题,会在12秒之后就不响应了,等到15秒就会触发切换流程,避免了数据丢失的可能性
总结一下,我们这次说了脑裂问题,脑裂指的是主从集群中,同时有两个主库都能收到,如果发生了脑裂,那么客户端的数据就会写入到原主库,原主库顺便变成从库的话,新写入的数据就丢失了
对于脑裂的问题,可以在集群部署的时候,通过合理的配置参数min-slaves-to-write和min-slaves-max-lag,预防脑裂的发生
常见的设置可以为,假设从库有K个,可以将min-slaves-to-write设置为K/2+1,
min-slaves-max-lag设置为十几秒
最后一个小问题,假设将min-slaves-to-write设置为1,min-salves-max-lag设置为15s,哨兵的down-after-milliseconds设置为10s,主从切换需要5s,主库卡住了12s,这时候会发生脑裂吗?
这是必然的,因为,假设10s后哨兵达成了客观下线,那么会进行主从切换的操作,但是这个时候,主库还没达到min-slaves-max-lag时间,这时候还是可以接受客户端请求的,故可能导致了脑裂问题
还有一个min-slaves-to-write的设置,如果只有1个从库,那么运维的时候需要注意,如果需要更换从库的实例,先添加新的从库,再移除旧的从库才可以,或者使用config set修改 min-slaves-to-write为0才可以