伴随着业务数据的增加,Redis需要能够保存更多的数据,但是在集群使用中,如果每个实例数据规模都很小的话,那么维护并不方便,如果数据量大的话,会导致一些数据同步和数据恢复上的错误
后来,为了解决大容量的保存,360利用RocksDB实现了Pika键值对数据库,实现这一个需求
Pika在刚开始设计的时候,主要是为了满足单实例可以保存大容量数据,避免大实例恢复和主从同步的潜在问题
第二是和Redis数据类型保证兼容,支持使用Redis的应用平滑的迁移到Pika上
故Pika成了我们本章讲解的重点
首先是关于Pika的整体架构,包含五个部分,分别是网络框架,Pika线程模块,Nemo存储模块,RocksDB和binlog机制
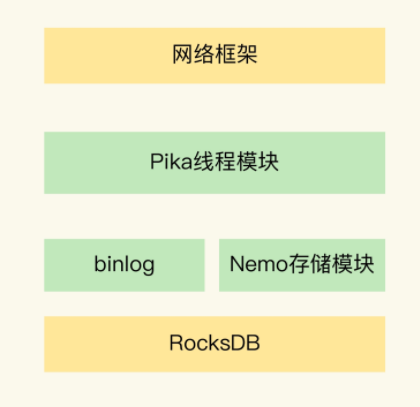
对于上面的模块进行分模块的讲解
首先是网络模块,利用了多线程模型来处理客户端的请求,包含一个请求分发线程 DispatchThread 一组工作线程,一个后台线程池,请求分发线程负责客户单的链接,建立链接后将请求交给工作线程处理,工作线程提交Task给线程池中的线程,由这些线程进行实际数据处理
然后Nemo模块,负责Redis和Pika数据类型的兼容,当我们把Redis服务迁移到Pika的时候,不需要额外处理操作
然后是binlog机制,在写入数据的同时保存到binlog中,同时将binlog机制用于主从节点的同步
之后是最底层的RocksDB,这是一个业界通用底层数据库,其利用了顺序读的机制,在写入数据的时候,首先写入到内存中,然后写满之后写入磁盘,内存中写入数据利用了sorttable的机制,使得key本身是有序的,去并且在磁盘上不断的进行合并处理,减少占用,保证磁盘有序
1.Pika针对Redis大内存出现的潜在问题,进行了什么样的优化
首先是Redis数据备份时的RDB,RDB的文件大小和Redis内存大小成正比,同样和RDB文件生成时的fork时长成正比
而且,主从节点之间的同步第一步要进行全量同步,RDB文件过大也会影响主从同步,而且再同步过程中可能出现复制缓冲区溢出的问题,导致重新全量复制
Pika使用了binlog日志,解决了在数据同步过程中出现了RDB过大阻塞主线程的问题,从线程只需要记录自己的同步起始点即可
2.Redis持久化
利用了底层的RocksDB这样一个持久化键值对,避免了利用内存快照进行恢复
那么说了Pika在持久化和存储上的优化,我们说一下,Pika如何保证和Redis数据类型兼容
Pika底层的存储利用了RocksDB,而RocksDB是一个只支持键值对存储的持久化数据库,所以Pika提供了Nemo模块作为上层的计算引擎,将Redis的集合类型转换为单值的键值对
我们分别按照List,Set,Hash,Sorted Set这几个类型划分进行讲解
对于List类型,分为了Ket和Values,那么在底层存储中
组合为了下面结构
Key中首位是L,表示是一个List类型,还增加了一个1字节的Size字段
然后在Key的后面增加了sequence字段,表示当前元素在List中的顺序
value中前面加了pervious sequence和next sequence表示前一个和后一个元素
value的后面加了version和ttl字段,表示当前数据的版本号和剩余过期时间

之后是Set集合
Set的数据类型组合为下图
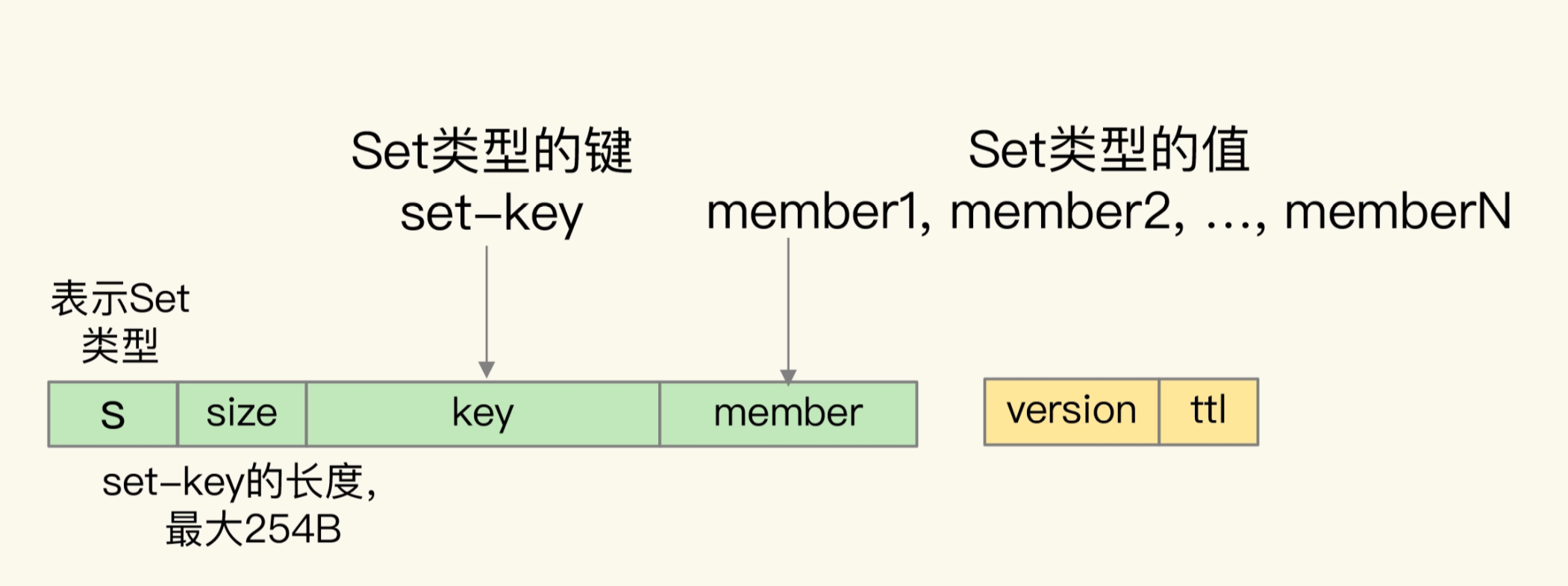
key中前面是S,表示是Set字段,之后是Size字段,然后将原本的Value放在key中,作为memeber
value中只保存了版本信息和剩余存活时间
对于Hash类型,Hash由 key field value组成
故组合成如下的数据类型

首先是h表示hash类型,然后是一个size,之后是key和field
value中保存了value和version及ttl
最后是Sorted Set类型,能够按照集合的score值来排序的,RocksDB只支持单值键来进行排序
所以需要将member放在key中,组合后的结构如下
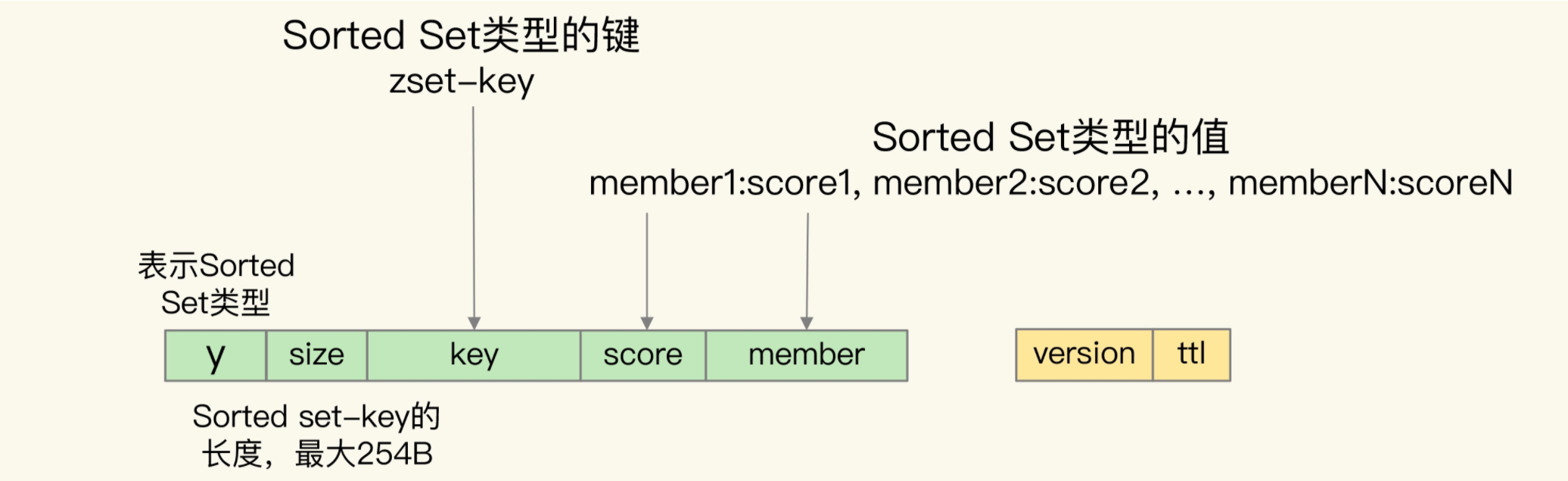
上面的转换,让Pika不仅能够兼容Redis的数据类型,还保留了数据特征
最后说一下,可能存在的一个问题,Pika因为利用硬盘保存数据,是否会性能上比不过Redis呢?
虽然说SSD可能从性能上劣于内存,但Pika的多线程执行模型,从一定程度上弥补了硬盘读取数据造成的性能损失
从单机大容量保存性能的角度来说,Pika是一个相对不错的方案
总结一下,我们Pika是一个大容量数据保存的数据库,底层利用RocksDB进行存储,而且利用多线程降低了硬盘和内存之间的性能鸿沟
最后说明一下,对于Redis迁移Pika,Pika支持命令
aof_to_pika -i [Redis AOF文件] -h [Pika IP] -p [Pika port] -a [认证信息]