Redis为了避免直接从后端数据库中读取数据,才诞生的一个内存数据库
那么这个避免读取,不等于将后端数据库所有的数据都缓存起来,如果将后端数据库的所有数据都缓存起来,那么性价比就降下来了,1TB的内存价格和1TB的硬盘价格是非常悬殊的,而且往往实际场景中存在八二原则,即80%的请求只访问了20%的数据,所以合理的选择将数据存入Redis才是王道
那么我们本章就从两个方面入手,分别从缓存大小的抉择和缓存淘汰策略的选择来分别讲解
1.缓存大小的抉择
缓存容量设置是否合理,会直接影响使用缓存的性价比,通常希望以最小的代价获取到最大的收益,所以将昂贵的内存资源用在关键地方非常重要了
下面有张图,蓝线代表八二原则中的数据局部性 红线就是当前应用负载下,数据局部性的变化
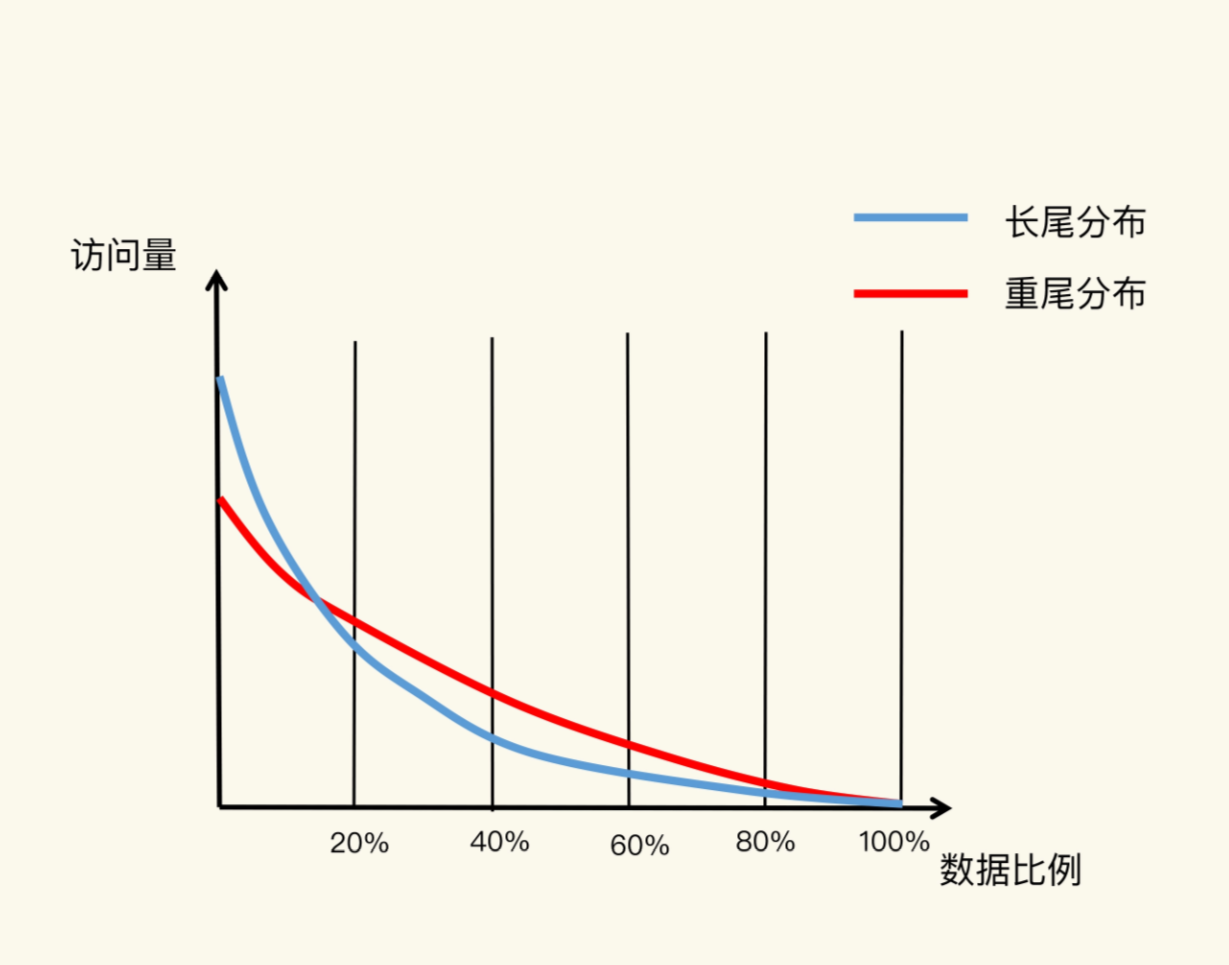
对于蓝线,因为是八二原则的代表,所以在20%之后,就会急速的下降访问量,形成了一个长长的尾巴,称为长尾效应
在实际的使用中,因为现在应用中,用户的个性化需求越来越多,在一个业务中用户访问的数据可能并不是那集中的20%,所以导致成为了80%的访问量上去了,称之为重尾效应
所以在实际应用中,不能单一的将容量设置为后端数据库容量的20%
可以考虑将其放大或者放小,兼顾性价比和访问性能
而设置缓存的大小,可以使用如下的命令
CONFIG SET maxmemory 4gb
那么说完了缓存大小的设置之后,我们明确下如何选择淘汰的策略
Redis一共提供了8种淘汰策略
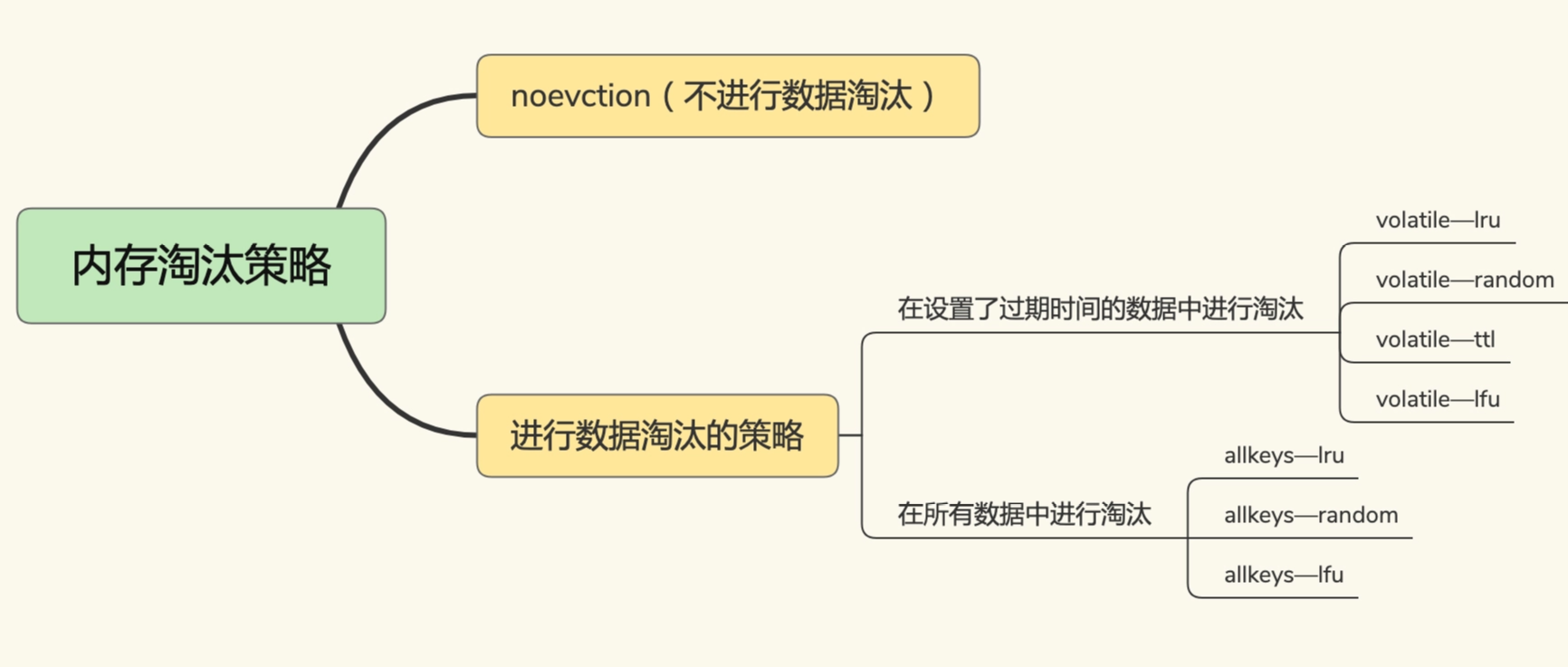
不进行淘汰的,只有Noeviction
其表示在使用内存超过了maxmemory值的时候,并不会淘汰,而是在写满之后,不提供任何服务,直接返回错误
然后就是其他的内存策略,volatile-random volatile-ttl volatile-lru 和 volatile-lfu这四类分为一种,表示会删除有过期时间的key
在内存使用量达到了一定额度,或者设定的过期时间快到了,都会开启淘汰筛选策略
volatile-ttl 会按照过期时间先后进行删除
volatile-random 会在设置了过期时间的键值对中,随机删除
volatile-lru 会使用LRU算法筛选设置了过期时间的键值对
volatile-lfu 使用LFU算法筛选过期键值对
然后是allkeys-lru allkeys-random allkeys-lfu 这几种淘汰策略,其扩大了筛选范围,扩大到了所有键值对,和键值对是否设置了过期没有关系了
allkeys-random 策略,从所有键值对中随机选择并删除数据
allkeys-lru 使用LRU算法在所有数据中筛选
allkeys-lfu 使用LFU算法在所有数据中筛选
LRU算法大家并不陌生,在Redis中是如何体现的呢?
因为LRU基本上是利用链表的数据结构实现的,而Redis中维护一个所有key都存在的链表实在太过于耗时了,所以进行了简化,减轻数据淘汰对缓存性能的影响,Redis在头中记录了时间戳,然后淘汰开始的时候,会随机选出N个数据,作为一个候选集,然后淘汰一部分lru小的数据
选择多少个数据作为采样(即N),可以通过配置来设置
CONFIG SET maxmemory-samples 100
当再次出发淘汰策略的时候,Redis挑选数据进入第一次淘汰时的集合作为补充,这时候的补充挑选标准是lru字段必须要小于候选集合中最小的lru值,如果达到了N值,那么就开始淘汰
在上面的淘汰策略中
推荐使用allkeys-lru,但是这样没法设置固定值,因为固定值可能也会出现过期删除的情况,所以有固定值的时候推荐使用volatile-lru
其次我们不能指望,在淘汰的key的时候,由Redis做什么事,所以我们需要在数据被修改的时候就将其写回数据库
本章总结一下
我们说了Redis缓存大小的选型和Redis的淘汰策略,从淘汰策略来看,一种是所有的数据都是候选集,一种是设置了过期时间的数据是候选集
无论是那种候选集,都可以选择淘汰策略是随机还是LRU算法还是LFU算法,确定这些,就可以实际的使用Redis筛选了
那么最后一个问题Redis缓存是符合只读缓存还是读写缓存
是只读缓存还是读写缓存取决于实际应用中的使用方式,没有什么固定之说