Redis中的时序数据
对于一般的应用中,都有则记录时序性数据的需求
在物联网的项目中,这个需求更为常见,一般可能存在统计近万台设备的实时状态,包括设备ID,压力,温度,湿度,对应的时间戳
虽然Redis本职并不是存储时序性数据库的,但是如果使用Redis去存取的话,考虑使用哪些数据结构,也不枉是一个好的话题
对于此类思考,需要先了解的是,时序性数据的概念,一般时序性数据主要是插入新数据,而不会更新一个已经存在的数据,所以要求数据结构在进行插入的时候不会发生阻塞的情况
但时序性数据对读有一定的要求,简单点的是查询单个记录,再之后有对一个时间范围内的数据查询,以及对一个时间范围内的数据做聚合运算,包括计算平均值,最大 最小值
综上所述,对于时序性数据,要求数据结构支持查询的花样多,新增只需要支持尾部插入即可
Redis中提供了RedisTimeSeries这一额外模块进行支持,但是否可以使用原生的数据类型,Sorted Set或者Hash进行数据存储呢?
如果使用Sorted Set或者Hash,是否有什么缺点呢?
如果是使用Hash记录时序数据,那么存储基本如下

但是查询时候会出现一些问题,就是不支持范围的查询
Hash类型的底层是哈希表,并不会做排序,所以范围查询也是需要取出key值,然后一个个的查询,效率很低
那么这时候,为了支持范围查询,Sorted Set可以上场了,支持根据元素的权重分数来排序,,而这个权重可以利用时间戳作为权重,方便进行记录
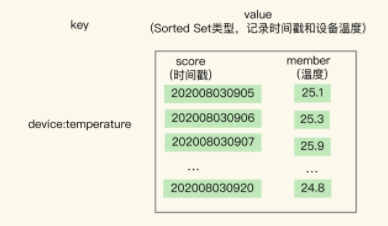
使用Sorted Set保存数据之后,可以使用类似ZRANGEBYSCORE命令,根据时间戳的范围来查找一段时间内的Value了
如果想要方便的支持单值查询和范围查询,可以考虑一个数据存两个地方,分别放在Hash和Sorted Set两个地方
如果需要保证原子性,可以利用MULTI 和 EXEC命令
MULTI保证原子性的操作开始,EXEC保证原子性操作的结束
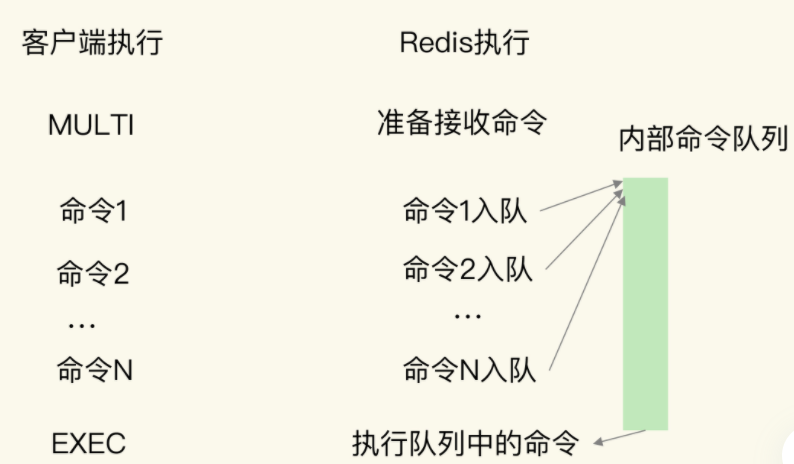
这样就做到了单值和范围的查询,但是对于数据的聚合查询,Reids原生的数据类型并不支持聚合查询,为了解决这个天然的缺陷,只能考虑在客户端自行完成聚合,这有一个问题,就是会有大量的数据在Redis和客户端之间频繁传输,会导致和其他的命令竞争网络资源,系统阻塞
为了支持聚合运算,Redis提供了RedisTimeSeries来保存时序性数据
ReidsTimeSeries直接在Reids实例上进行聚合运算,减少的数据的传输,对于其的使用,需要先将其编译为动态链接库,然后进行加载
对于其支持的操作,主要有以下5个
TS.CREATE 创建时间序列数据集合
TS.ADD 命令插入数据
TS.GET 获取最新的数据
TS.MGET 根据标签获取数据集合
TS.RANGE 进行聚合计算
1.TS.CREATE
设置时间序列数据集合的key和数据的过期时间,
TS.CREATE device:temperature RETENTION 600000 LABELS device_id 1
上面命令就是
创建一个key为device:temperature,数据有效期为600s的时间序列集合,最后加上了标签属性{device_id:1},表明记录的是设备ID为1的数据
2.TS.ADD插入数据
命令如下
TS.ADD device:temperature 1596416700 25.1
插入一条数据
3.TS.GET TS.MGET
TS.GET device:temperature
获取最新的数据
TS.MGET 根据标签过滤集合
我们一开始创建队列的时候,在其中加入了集合的标签属性,那么在查询的时候就可以利用MGET,以及FILTER,过滤查询数据
| TS.MGET FILTER device_id!=2
1) 1) “device:temperature:1” 2) (empty list or set) 3) 1) (integer) 1596417000 2) “25.3” |
4.TS.RANGE支持需要聚合运算的范围查询
使用TS.RANGE命令指定要查询的时间范围的时候,同时用AGGREGATION参数指定要执行的聚合计算类型,包括求均值,最大最小值 求和
我们可以按照每180s的时间窗口,对其进行均值计算
TS.RANGE device:temperature 1596416700 1596417120 AGGREGATION avg 180000
和使用Hash和Sorted Set来保存时间序列数据相比,ReidsTimeSeries是专门为时间序列数据的模块
总结一下,本章说了Redis提供了时序性数据解决方案
第一种是使用原生的Hash和Sorted Set类型,将数据保存在Hash集合和Sorted Set ,但是不支持聚合运算
第二种是RedisTimeSeries模块,专门为时间序列数据设计的扩展模块,支持在Redis上进行多种数据聚合运算,避免了大量数据在实例和客户端之间进行传输,不过RedisTimeSeries的底层数据结构使用了链表,范围查询的复杂度是O(N)级别的
最后一个问题,就是使用Sorted Set作为时间序列数据,将时间戳作为Score,实际的数据作为member,这样保存数据有没有潜在的危险
首先说,对于时序性数据,一定要选择专业的时序性数据库,包含InfluxDB Opentsdb,哪怕使用ES也行,
然后上面的问题,如果使用Sorted Set作为数据结构保存时序性数据,会出现大量写入从而引起的big key问题,
而且聚合运算的受众面太小,并不适合直接作为一个内在功能