我们分享了Kubernetes的核心架构,编排概念,以及具体的设计和实现,我们再说下Kubernetes中监控相关的一些核心技术
Kubernetes整体架构中,也是由千奇百怪的方案到整体统一的一个方案的发展
而现在已经成为Prometheus为中心的一套整体统一的方案
而这个Prometheus项目,也是来源于谷歌的Borg体系,其原型系统,叫做BorgMon,是一个和Borg同时诞生的内部监控系统,希望能够通过对用户用好的方式,将Googole内部的设计理念,更加好的传递给用户的开发者
而整体的架构概念,Prometheus项目基本如下
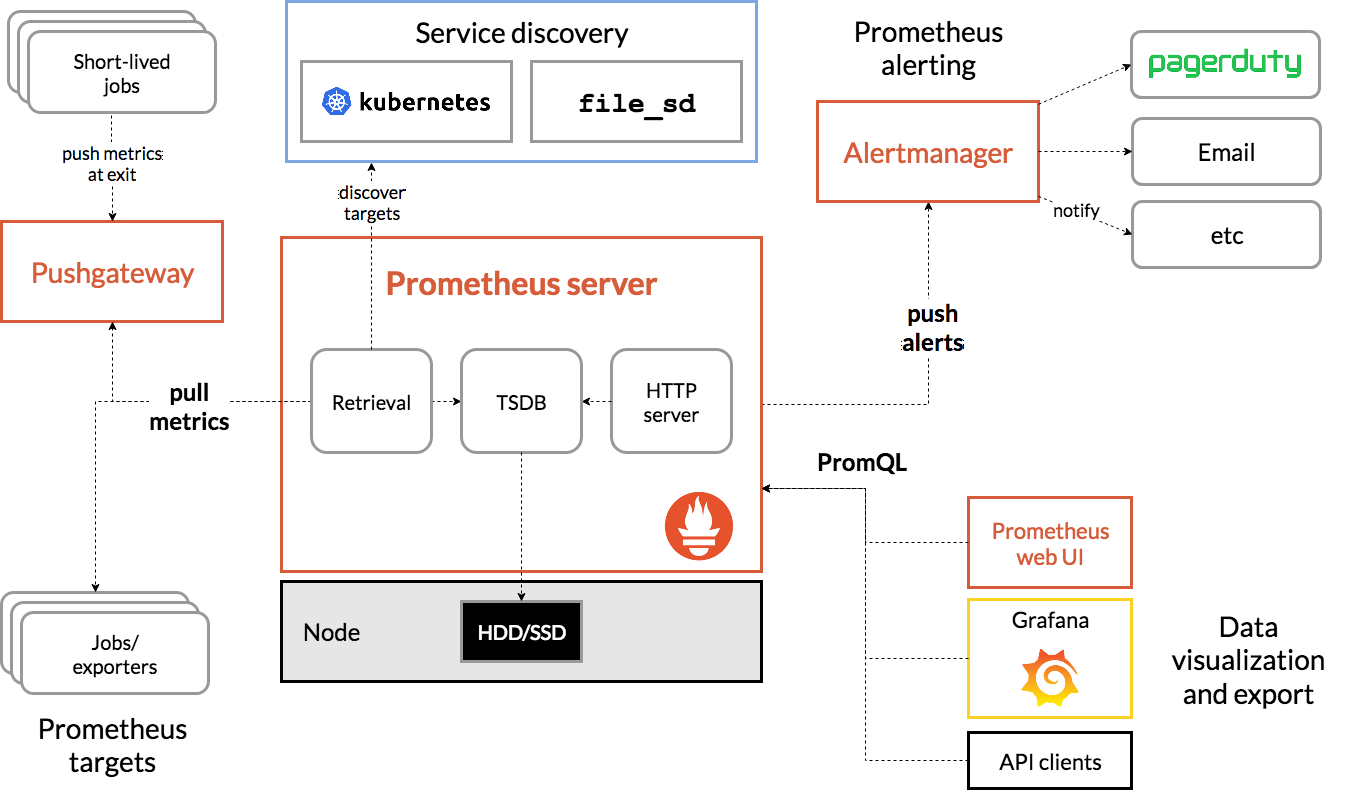
整体的过程可以简化为,利用Job或者exporters去搜集被监控对象的Metrics(监控指标数据),然后将其保存在一个TSDB 时序性数据库,比如OpenTSDB,InfluxDB等,方便后续进行搜索
有了这个核心监控机制,Prometheus剩下的组件就是配合这套机制的运行,比如Pushgateway,允许被监控的对象以Push的方式向Prometheus推送Metrics数据,而Alertmanager,可以根据Metric信息灵活的设置报警,而且自带的灵活配置的监控数据可视化的界面
具体的Metrics可以分为
1.具体的宿主机的监控数据,这部分的数据的提供,需要借助一个由Prometheus维护的Node Exporterg工具,以DamonSet的方式部署在了节点上,方便去抓取Metrics信息,其中包含的Node Exporter给暴露出的信息有 CPU 内存 磁盘等
2.来源于Kubernetes的API Server,Kubelet等上报的metrics API,这部分暴露了一些K8S的核心组件的监控指标,包括Api Server中的多个Controller的工作队列,请求的QPS,延迟信息,这些也是K8S的主要工作依据
3.Kubernetes的业务监控数据,关于Pod Node 容器, Service等主要Kubernetes核心概念的Metrics,关心细化到每一个容器的CPU 文件,网络的情况
这样的Kubernetes的重要扩展能力,称为Metrics Server,其中在Kubernetes社区中,Meitriv Service 是一种标准的API 规范,方便实现者进行解耦和上层调用.
而在Metrics Server规范出台之后,用户就可以直接通过API访问到监控数据了,如下所示
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
当访问这个Metrics的API时候,会返回一个Pod的监控数据,这些数据就是从Kubelet中采集而来的,包含了cAdVisor的监控数据
这个Metrics,是在Kube Aggregator模式之中体现的,就是类似Nginx,根据不同的后缀选择不同的实现项目
在这个机制下,可以拥有过重kube-aggregator,根据不同的URL选择后端的代理服务器,Aggregator模式是默认开启的,如果是手动DIY搭建的话,则需要在kube-apiserver的启动参数中加上了如下所示的配置
|
–requestheader-client-ca-file=<path to aggregator CA cert>
–requestheader-allowed-names=front-proxy-client –requestheader-extra-headers-prefix=X-Remote-Extra- –requestheader-group-headers=X-Remote-Group –requestheader-username-headers=X-Remote-User –proxy-client-cert-file=<path to aggregator proxy cert> –proxy-client-key-file=<path to aggregator proxy key> |
那样,我们就可以开启了Aggregator功能了
这样,我们就可以看到这个API可用了
这样我们就可以让Prometheus去采集就可以了
在本片中,我们介绍了Kubernetes当前监控体系的设计
介绍了Prometheus项目在这套体系中的地位,讲解了以Prometheus为核心的监控系统的架构设计.
然后详细的讲解了Kubernetes核心监控数据的来源,Metrics Server的具体工作原理,Aggregator APIServer的设计思想
我们就可以对Kubernetes的监控有了一个整体的认知,体会到在监控的发展趋向
在具体的监控指标的规划中,遵循了几种通用的USE原则和RED原则
USE原则值得是按照如下的几个维度划分
1.利用率,资源被有效了利用起来的平均时间占比
2.饱和率,资源拥挤的程度,比如工作队列的长度
3.错误率,错误的数量
而RED原则,按照的是如下的三个维度规划服务监控指标
1.每秒请求数量 Rate
2.每秒错误数量 Errors
3.服务响应时间 Duration
USE关心的是资源,RED关心的是服务,比如kube-apiserver或者某个应用的工作情况,这两个指标,就是我们讲解的kubernetes+prometheus中覆盖掉的
在监控体系中,对于数据的采集,有着Pull模式,还有着Push的模式,这两个模式的异同和优缺点呢?
Pull和Push的区别在于
Pull是交由被监控者提供一个Server并进行维护的
监控方控制采集的频率,但是这样的话,可能导致有些时候监控着拿不到数据的情况
Push则是交给被监控着主动上报一个数据,并监听者被动采集这个数据,推动作有利于被监听者自己控制上报数据和频率,对监听者有额外的压力,有信息丢失的风险
我更加倾向于使用Push的模式,因为使用Pull的话,可能会导致频率时间短的情况下,对Server的造成巨大的压力