首先之前说了DDos导致的响应缓慢的问题,DDos因为分布式 难以追踪的特点,导致没有办法可以完全的防御DDos带来的问题,只能设法缓解DDos的影响
比如专业的流量清洗工具和网络防火墙,在网络入口处阻断恶意流量,就能缓解很大一部分
服务器中加上DPDK XDP等方法,增大服务器抗攻击能力,应用程序中利用多级缓存 WAF CDN等方法继续宁缓解
但是只要进入服务器中,那么还是会带来一定的性能损失
除了DDos的攻击,还有很多其他的原因导致网络延迟,比如
网络传输慢,导致延迟
Linux内核处理报文慢,导致延迟
应用程序慢,导致延迟
我们看下上面说的,除了DDos之外的问题
首先是网络延迟
网络延迟,往往是说的一个包的来回双向消耗的时间,即从源地址发到目标地址,然后从目标地址发回响应,往返的全程时间
常见的Ping测试,就是统计的双向延迟RTT Round-Trip Time
而应用程序的延迟,就是应用程序从发出请求到获得响应的全程,其中在数据处理之外,就包括了网络传输的延迟
而Ping使用的ICMP。常用于一些网络攻击之中,比如端口扫描工具 nmap,组包工具hping3就可以组织ICMP相关网络攻击
为了保证不能有ICMP的相关攻击,很多网路服务都会将ICMP禁止掉,导致我们没有办法用ping来测试网络服务的可用性和往返延迟
还是考虑使用TCP或者UDP来获取网络延迟
比如baidu.com为例,可以执行如下的hping3,测试到百度搜索的服务器延迟
| # -c表示发送3次请求,-S表示设置TCP SYN,-p表示端口号为80
$ hping3 -c 3 -S -p 80 baidu.com HPING baidu.com (eth0 123.125.115.110): S set, 40 headers + 0 data bytes len=46 ip=123.125.115.110 ttl=51 id=47908 sport=80 flags=SA seq=0 win=8192 rtt=20.9 ms len=46 ip=123.125.115.110 ttl=51 id=6788 sport=80 flags=SA seq=1 win=8192 rtt=20.9 ms len=46 ip=123.125.115.110 ttl=51 id=37699 sport=80 flags=SA seq=2 win=8192 rtt=20.9 ms — baidu.com hping statistic — 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 20.9/20.9/20.9 ms |
来回的RTT的延迟为20.9ms
类似的traceroute可以获得类似的结果
| # –tcp表示使用TCP协议,-p表示端口号,-n表示不对结果中的IP地址执行反向域名解析
$ traceroute –tcp -p 80 -n baidu.com traceroute to baidu.com (123.125.115.110), 30 hops max, 60 byte packets 1 * * * 2 * * * 3 * * * 4 * * * 5 * * * 6 * * * 7 * * * 8 * * * 9 * * * 10 * * * 11 * * * 12 * * * 13 * * * 14 123.125.115.110 20.684 ms * 20.798 ms |
上面的输出中,traceroute会在路由的每一跳发送三个包,然后得响应后,输出来回延迟,如果无响应,则是一个星号
接下来,我们拿着一个案例,学习网络延迟升高的分析思路
这次使用wrk Wireshark hping3 tcpdump等工具进行讲解
对于Wireshark,如果Linux没有图形化界面,则可以使用Win端的安装
然后启动一个Nginx的docker容器
$ docker run –name nginx –network=host -itd feisky/nginx:latency
b99bd136dcfd907747d9c803fdc0255e578bad6d66f4e9c32b826d75b6812724
在终端二中执行curl,验证容器是否正常启动
接下来使用hping3,来测试延迟,
| # 测试8080端口延迟
$ hping3 -c 3 -S -p 8080 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=0 win=29200 rtt=7.7 ms len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=1 win=29200 rtt=7.6 ms len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=2 win=29200 rtt=7.3 ms — 192.168.0.30 hping statistic — 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 7.3/7.6/7.7 ms |
这种单线程的请求,是7ms的延迟
那么,换成并发请求呢?分别是80端口和8080端口的性能
| # 测试8080端口性能
$ wrk –latency -c 100 -t 2 –timeout 2 http://192.168.0.30:8080/ Running 10s test @ http://192.168.0.30:8080/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 43.60ms 6.41ms 56.58ms 97.06% Req/Sec 1.15k 120.29 1.92k 88.50% Latency Distribution 50% 44.02ms 75% 44.33ms 90% 47.62ms 99% 48.88ms 22853 requests in 10.01s, 18.55MB read Requests/sec: 2283.31 Transfer/sec: 1.85MB |
性能比=并不高,平均的延迟高达44ms
对于此,我们需要进行相关的性能测试
首先是利用tcpdump命令进行相关的抓包
tcpdump -nn tcp port 8080 -w nginx.pcap
然后切换到终端二上,重新执行wrk命令
进行并发的执行wrk命令
wrk –latency -c 100 -t 2 –timeout 2 http://192.168.0.30:8080
将抓取到的nginx.pcap,复制到装有Wireshark的机器,并用Wireshark打开
之后从界面话的Wireshark进行分析
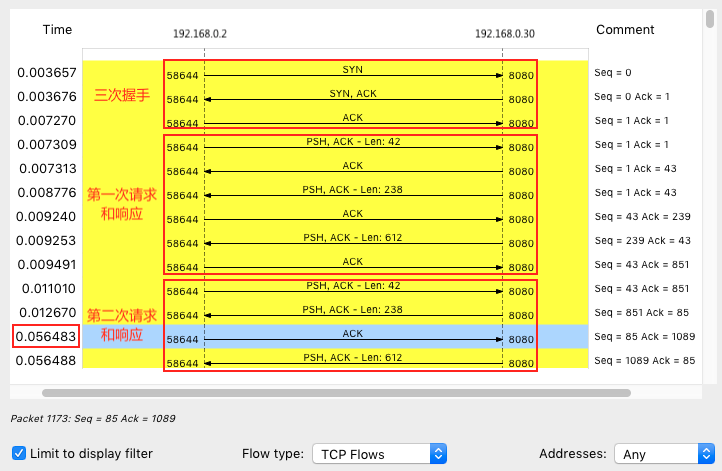
上图上可以了解,第二次的请求比第一次的请求间隔,大于了40ms,每次请求间隔要40ms,这跟TCP延迟确认的最小超时时间是一致的
这是不是开启了延迟确认的机制呢?
就是针对TCP ACK的优化机制,每次确认不会都发送一个ACK,而是多个ACK一起发回,如果一直等不到可以一起发送的ACK,则在一定时间后进行单独发送
对于这个延迟确认的机制是否开启?我们可以查看TCP套接字是不是设置了TCP_QUICKACK
如果设置了,就是开启快速确认机制,不然就是延迟确认机制
对于此套接字的确认,可以利用strace,来观察wrk为套接字设置了哪些TCP选项
strace -f wrk –latency -c 100 -t 2 –timeout 2 http://192.168.0.30:8080
在设置之中,wrk设置的套接字如下
$ strace -f wrk –latency -c 100 -t 2 –timeout 2 http://192.168.0.30:8080/
这样,wrk只设置了TCP_NODELAY的选项,导致了延迟确认
但是这样为何影响到了Nginx服务器呢?
根据Wireshark 的响应,我们查看如下的一点蛛丝马迹
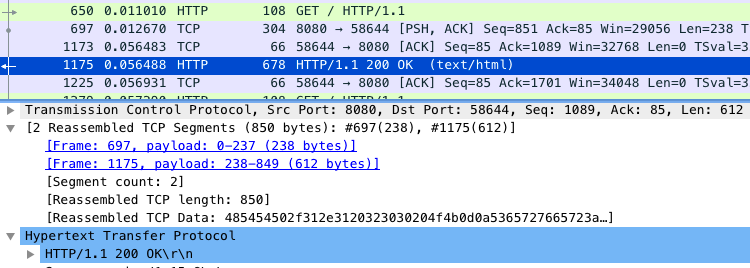
上面的1173包,是第一个请求的响应,但是第一个请求的响应,是跟着第二个分组包,1175,一起进行的ACK
这好比是TCP的Nagle算法
为了减少小包发送数量的一种优化算法
Nagle为了解决,每个数据包,无论数据多小,都有着TCP头和IP头占用的20个字节,如果全是小包,那么利用率就太低了
于是,为了解决这个问题,就通过合并TCP小包,提高利用率
但是当Nagle和延迟ACK一起使用的话,就会出现如下的场景
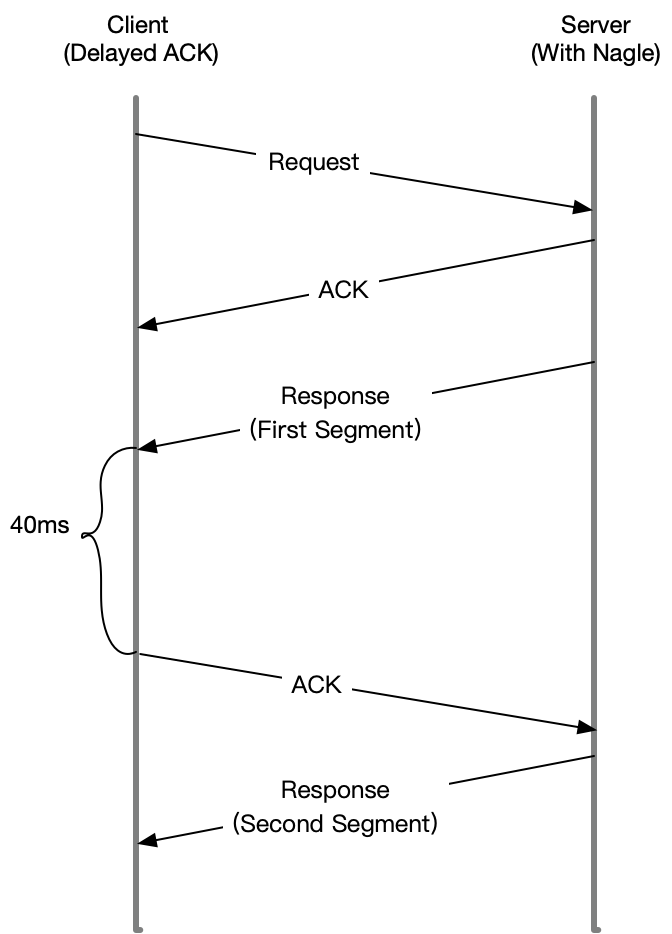
Server发送第一个分组之后,由于Client开启了延迟确认,需要等待40ms才会回复ACK
Server端也开启了Nagle,导致Server因为没有第一个分组的ACK,也会一直等待
直到40ms超时之后,Client才会回复ACK,Server才会才会进行发送第二个分组
那么,接下来就是查看Nginx有没有开启Nagle了
Nginx也有对应的TCP_nodelay选项
查看Nginx的配置,
$ docker exec nginx cat /etc/nginx/nginx.conf | grep tcp_nodelay
tcp_nodelay off;
发现tcp_nodealy是关闭的,设置为on即可解决
如上,便是今天的网络传输的优化解决方案
今天我们说了,发现网络延迟加大之后,可以使用traceroute hping3 tcpdump Wireshark strace等工具进行发现网络问题
使用hping3和wrk,查看网络延迟是否正常
使用traceroute 确认路由是否正确,查看路由中的每一跳网关延迟
使用tcpdump和Wireshark,确认网络包的收发
使用strace,观察应用程序对网络套接字的调用是否正常
依次,从路由,网络包的收发,应用程序等,进行逐层排查