我们说过了Linux网络的基础原理和性能观测方法,整体基于了TCP/IP模型,构建了网络协议栈,将网络划分为了应用层 传输层 网络层 网络接口层 等四个不同层次,解决了网络环境的异构问题和解耦了网络协议的复杂性
在TCP/IP模型中,Linux可以通过带宽 吞吐量 延迟 PPS等衡量网络性能
接下来,我们回顾一下C10K和C1000K问题,理解Linux的网络工作原理
C10K是指的多个Client同时发起1万个请求的问题,C1000K则是类似的数量累加
C10K如何进行的解决,也就是如何支持并发1万的请求的呢?
在早期的服务器上,还是可以从硬件上支持C10K问题的
但是需要进行优化软件相关的问题,特别是网络的IO模型
在早期的Linux网络模型处理中,都采用的同步阻塞的方式,为每一个请求分配一个线程或者进程,这样会导致占用大量的系统资源
后来为了减少对应的物理资源的占用
进行了相对应的网络模型的修改,即IO模型的优化
异步的,非阻塞的IO的优化思路,是首先想到的网络编程中的IO多路复用
在Linux中,可以有水平触发和边缘触发,常用于套接字接口的文件描述符中
水平触发,就是文件描述符可以非阻塞的执行IO,就会触发通知,应用程序主动检查文件描述符的状态,然后根据状态,进行IO
边缘触发,就是文件描述符的状态发生改变的时候,才会进行通知,这时候,应用程序需要尽可能多的进行执行IO,直到无法继续读写,或者因为某种原因没有来得及处理,这次通知丢失了
我们再来看对应的IO多路复用的方法
第一种,使用非阻塞的IO和水平触发通知,select或者poll
基于水平触发的原理,select和poll从文件描述符列表中,找到那些可以执行IO,然后进行真正的IO读写,由于IO是非阻塞的,一个先册灰姑娘就可以同时监控一批的套接字的文件描述符,这样就达到了单线程处理多请求的目的
这种方式的优点,就在于对应用程序友好,API简单
但是这种方式,应用程序获得了通知,还是要利用select 和 poll 对文件描述符列表进行轮询,请求数多的时候比较耗时,而且Select需要在进行监听,而监听有一个上限,故Select的监听上限,取决于对应的FD_SETSIZE限制
poll虽然没有了固定长度的数组,但是应用程序使用poll的时候,需要对文件描述符进行轮询,这样效率还是不高
最后,有什么最好的方式进行处理呢?
Linux给出了非阻塞IO和边缘触发的结合 epoll
epoll使用红黑树,在内核中管理文件描述符的集合,保证不需要应用程序在每次操作的时候都传入 传出集合
epoll使用事件驱动的机制,只关注有IO事件发生的文件描述符,不需要进行轮询
在继续IO模型优化之后,进行工作模型的优化
分为了两种,第一种 主进程+ 多个worker子进程,由主进程和多个worker组成,主进程负责初始化套接字,管理子进程的生命周期,worker进程,则是负责实际的请求处理
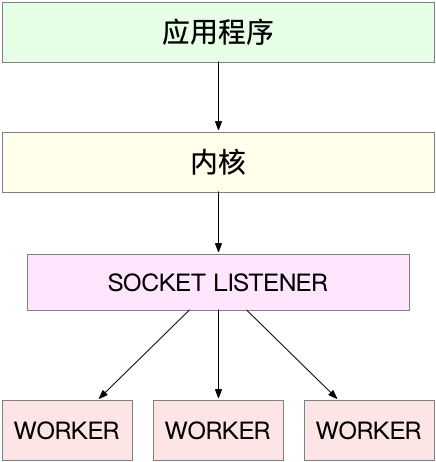
当然,accept() 和 epoll_wait() 调用,还有这一个惊群的问题,当网络IO事件发生的时候,多个进程都会被唤醒
但实际上只有一个进程负责相应这个事件
后来,这些问题都被默默修复了
第二种工作模型,就是监听到相同端口的多进程模型,所有的进程都监听相同的接口,然后开启SO_REUSEPORT选项,将这些请求负载均衡到监听进程中
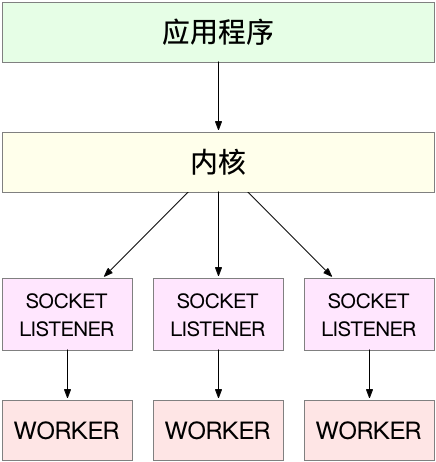
由内核保证只有一个进程可以被唤醒
之后我们说一下C1000K的问题
基于IO多路复用和请求处理的优化,C10K可以基于网络模型的优化进行解决
但是对于C1000K,之前不需要注意的硬件资源都快出现了瓶颈
假设每个请求都需要16KB,那么总共还需要15GB内存
而且带宽即使只有20%,那么可能也有1.6GB/s的吞吐量,那么这么大的吞吐量,还需要配置万兆网卡
而且,大量的请求带来的硬中断处理,会带来大量的代理成本,这样,需要多队列的网卡,中断负载均衡,CPU绑定 RPS/RFS,网络包的处理卸载等软硬件的优化
最后,就是我们说的C10M问题了,对于C10M问题,和C1000K最大的区别在于,软件和硬件的优化已经做到头了
硬件已经成了瓶颈
这时候,最大的问题,反而是Linux的内核协议栈,因为从网络中断的硬中断处理程序,到解包,到应用程序,这一个路径实在太长了,导致成为我们优化的拦路虎了
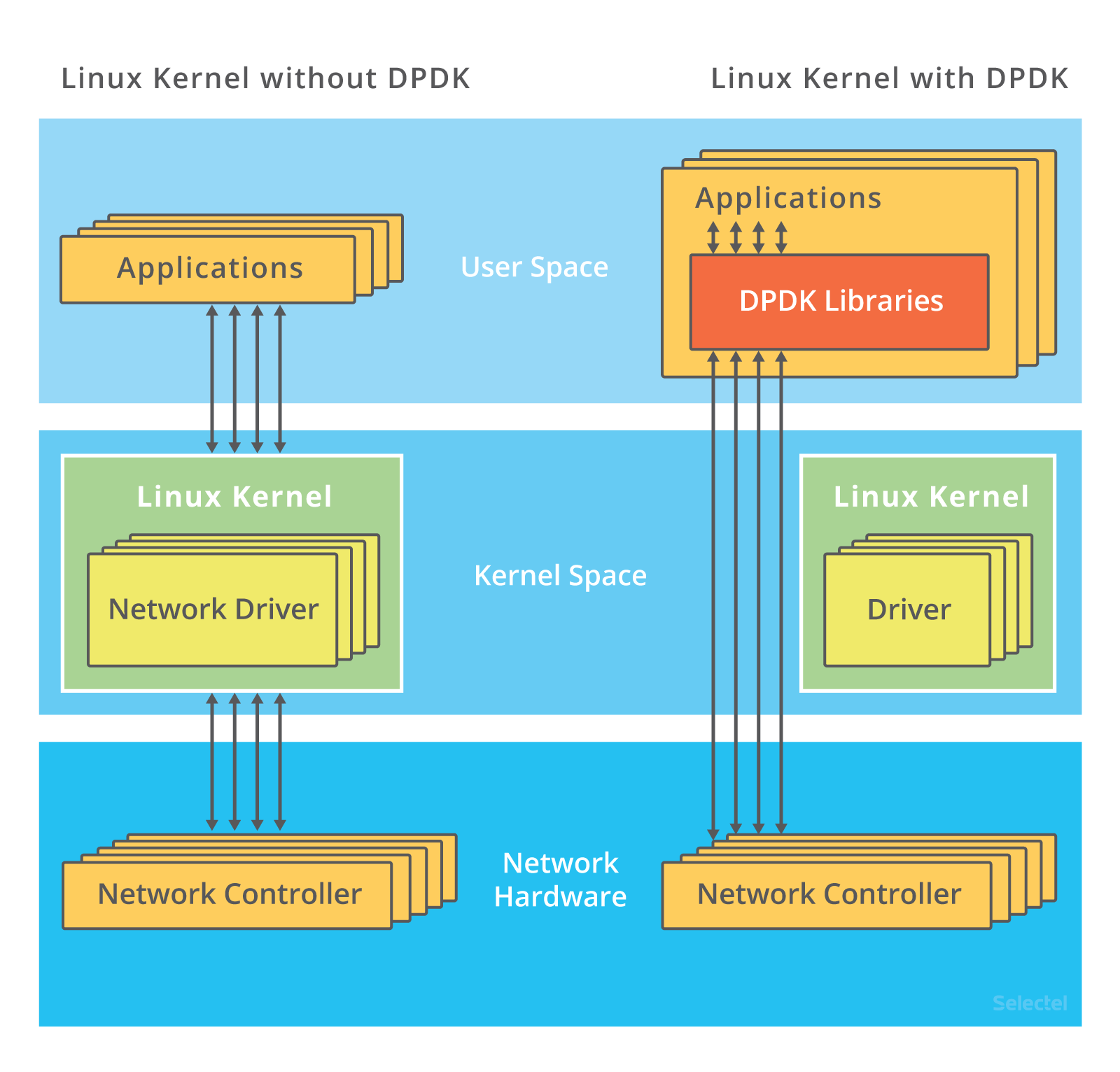
对于这种时候的优化,可以考虑跳过内核协议栈,将网络包直接送到要处理的应用处理程序,常见的由DPDK和XDP
我们只介绍一下DPDK
DPDK,是用户态的标准,跳过了内核协议栈,直接由用户态进程进行轮询,来处理网络接收
一般来说,轮询是一种低效的象征,但是一般来说,低效是源于查询事件多余工作时间,但是我们所面对的场景是C10M
这种情况下,轮询反而具有优势了
可以直接跳过内核态,省去了复杂的硬中断,软中断到Linux网络协议逐层处理的过程,进行有针对的优化网络包的处理逻辑
而且提供了大页 CPU绑定 内核对齐 流水线并发等机制,优化网络包的处理效率
我们总结一下今天的说法,我们从C10K一直延申到了C10M问题
C10K的问题,在于在系统有限的资源面前,进行网络IO模型的优化
C10K到C100K,可能只需要物理上的优化,从C100K到C1000K,就需要很多的优化工作,从硬件的中断处理到网络功能卸载,到网络协议栈的文件描述符数量,连接状态跟踪,缓存队列等内核优化,到应用程序的工作模型的优化
最后C10M,就需要优化内核协议栈,可以使用XDP或者DPDK进行处理了
当然,我们也不需要C10M,我们一般调整系统架构,将请求分发到多个服务器中来处理