我们在上一节末尾说了一个如果系统缓存被其他应用占用,乃至清理,MyISAM引擎很难利用系统缓存,以至于导致IO性能瓶颈
一般来说,应用系统的性能优化不能完全依靠系统缓存,而是能在应用程序内部分配内存,构建自主控制的缓存,或者使用第三方的缓存,比如Memcached Redis等
Redis是常用的键值存储系统之一,常用于数据库,高速缓存,消息队列代理等,Redis基于内存存储数据,但是为了保证持久化,也是有部分的IO,故还是可能引发IO性能问题
那么我们就来看一个Redis导致的IO性能问题
本次案例有对应的Python Redis构成,Python是一个基于Flask的应用,利用Redis,管理缓存,并提供接口来查询指定值的缓存数据
接下来,我们在第一个终端中,运行两个docker应用
| # 注意下面的随机字符串是容器ID,每次运行均会不同,并且你不需要关注它
$ docker run –name=redis -itd -p 10000:80 feisky/redis-server ec41cb9e4dd5cb7079e1d9f72b7cee7de67278dbd3bd0956b4c0846bff211803 $ docker run –name=app –network=container:redis -itd feisky/redis-app 2c54eb252d0552448320d9155a2618b799a1e71d7289ec7277a61e72a9de5fd0 |
docker run的过程中,将两个的network namespace进行了整合,之后利用
docker ps命令,确认两个容器处于运行状态
然后进行对应的curl进行相关的测试
curl http://192.1168.0.0:10000/search/xxx
查看返回
发现接口调用有10秒,这个响应时间,说明应用程序有问题
我们接下来,为了避免分析过程中客户端请求结束,循环来进行请求
$ while true;
do curl http://192.168.0.10:10000/get_cache;
done
然后继续进行分析
首先是top命令,查看全局信息
| $ top
top – 12:46:18 up 11 days, 8:49, 1 user, load average: 1.36, 1.36, 1.04 Tasks: 137 total, 1 running, 79 sleeping, 0 stopped, 0 zombie %Cpu0 : 6.0 us, 2.7 sy, 0.0 ni, 5.7 id, 84.7 wa, 0.0 hi, 1.0 si, 0.0 st %Cpu1 : 1.0 us, 3.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st KiB Mem : 8169300 total, 7342244 free, 432912 used, 394144 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7478748 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9181 root 20 0 193004 27304 8716 S 8.6 0.3 0:07.15 python 9085 systemd+ 20 0 28352 9760 1860 D 5.0 0.1 0:04.34 redis-server 368 root 20 0 0 0 0 D 1.0 0.0 0:33.88 jbd2/sda1-8 149 root 0 -20 0 0 0 I 0.3 0.0 0:10.63 kworker/0:1H 1549 root 20 0 236716 24576 9864 S 0.3 0.3 91:37.30 python3 |
在top的输出中可以看出,CPU0的iowait比较高,高达84%,但是CPU使用率不高,对应的python和redis-server只有8%和5%
对应的内存中,总内存只有8GB,剩余内存有7GB多,内存没有问题
综合top的信息,还是从iowait下手吧,看是不是IO的问题
先利用iostat进行查看io性能问题
iostat -d -x 1

对应的sda的磁盘写数据为2.5MB,IO使用率是0,说明没有达到IO的性能瓶颈
那么,虽然没有说明异常,但是应用性能就是存在瓶颈,这是怎么回事呢?
我们还是要考虑从io入手,先查看io读写来自于那些的应用进程
pidstat中观察对应的IO性能
| $ pidstat -d 1
12:49:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 12:49:36 0 368 0.00 16.00 0.00 86 jbd2/sda1-8 12:49:36 100 9085 0.00 636.00 0.00 1 redis-server |
可能看出,IO最多的进程正是PID为9085的redis-server,然后进行查找redis读写的磁盘文件是什么
我们使用strace和lsof组合,查看redis-server正在写什么?
我们利用strace -f -T -tt -p 9085
查看对应的redis进程号
| # -f表示跟踪子进程和子线程,-T表示显示系统调用的时长,-tt表示显示跟踪时间
$ strace -f -T -tt -p 9085 [pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055> [pid 9085] 14:20:16.826301 read(8, “*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-“…, 16384) = 61 <0.000071> [pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063> [pid 9085] 14:20:16.826645 write(8, “$3\r\nbad\r\n”, 9) = 9 <0.000173> [pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032> [pid 9085] 14:20:16.827030 read(8, “*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-“…, 16384) = 61 <0.000044> [pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043> [pid 9085] 14:20:16.827285 write(8, “$3\r\nbad\r\n”, 9) = 9 <0.000141> [pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049> [pid 9085] 14:20:16.827641 read(8, “*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-“…, 16384) = 61 <0.000043> [pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034> [pid 9085] 14:20:16.827945 write(8, “$4\r\ngood\r\n”, 10) = 10 <0.000288> [pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057> [pid 9085] 14:20:16.828486 read(8, “*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535″…, 16384) = 67 <0.000040> [pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052> [pid 9085] 14:20:16.828760 write(7, “*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535″…, 67) = 67 <0.000060> [pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415> [pid 9085] 14:20:16.834493 write(8, “:1\r\n”, 4) = 4 <0.000250> |
看出对应的系统调用比较频繁,其中可能涉及io的就是write和fdatasync导致的
然后查看lsof输出的系统调用的操作对象
lsof -p 9085
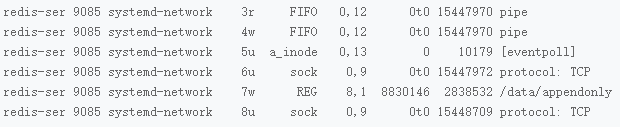
在这些输出中,显示出只有7号文件涉及了磁盘写,对应的路径是
/data/appendonly.aof,调用有write和fdatasync
这个文件是,redis用于持久化的文件,那么是否是持久化的配置不合理,导致的磁盘写升高
执行命令 reids-cli config get ‘append*’
来查看对应的配置
发现appendfsync配置的是always,appendonly配置的是yes
redis提供了不同的持久化方式
一种是快照,一种是追加文件
快照对应的是按照指定的时间间隔,来生成数据的快照,保存在文件中,这个保存是利用的fork的子进程,但是由于数据量大,所以fork需要大量内存
还有就是追加文件,文件末尾追加记录,进行持久化,支持的配置是always everysec no等
always 表示 每个操作都会执行一次fsync
everysec 表示 每秒钟都调用一次fsync,保证1秒一次的保存
no 表示交给操作系统处理
appendfsync配置的是always,每次写数据,都有一次的fsync,导致磁盘压力过大,此外,还有strace,观察整个系统的执行情况,通过-e选项指定fdatasync后,得到下面结果

这就是每10ms,都有fdatasync的问题
Redis的配置有问题,但是我们只进行了查询,也会触发fsync吗?
在每次的触发了磁盘写的时候,还会有一个编号为8的 TCP socket,观察上面的内容,8号对应的TCP读写,是一个标准的请求-响应 格式
从socket读取 GET uuid
然后读取的是SADD 命令
SADD是一个写操作,于是触发了持久化
观察这些结果,会发现GET返回good的时候,都会有一个SADD操作,导致明明是查询接口,却又大量的磁盘写
我们继续观察一下,上面的TCP链接,是不是链接到了Redis上
这需要我们进入容器的网络链接内部,查看完整的TCP链接
使用nsenter,可以进入容器命名空间
安装命令如下
docker run –rm -v /usr/local/bin:/target jpetazzo/nsenter
下述的命令为
nsenter –target $PID –net — lsof -i
在其中显示,TCP链接就是localhost:6379 -> localhost:32996
正是 redis -> python
reids延迟的原因可以发现了
1.reids配置文件,appendfsync是always,导致Redis每次的写操作,都会触发fdatasync的调用
2.python查询中会调用Redis的SADD命令,这是不合理的调用
首先我们将appendfsync设置为默认的everysec
docker exec -it redis redis-cli config set appendfsync everysec
然后是修改源码

python将reids作为临时文件缓存临时存储的数据了,导致数据调用拥堵.完全没必要不是
基于这个思路,我们将代码修改了
导致性能平稳下来了
总结一下,本次还是利用了pidstat strace lsof nsenter等一系列的工具,找到了潜在问题,一个Redis的配置不合理,一个是Python对应的redis的滥用,找到瓶颈后,优化就简单了