我们说了Kubernetes调度和资源管理相关的内容,我们在调度完成后,Kubernetes就需要调用kubelet来将这个容器在宿主机上创建出来
我们将会说一下Kubernetes的运行时管理能力
在Kubernetes社区,与Kubelet以及容器运行时管理相关的内容,都属于SIG-NODE的范围,SIG-NODE是Kubernetes中一个核心的部分,毕竟,这才是Kubernetes和容器打交道的主要场所
kubelet也是不建议进行修改的
kubelet本身是按照控制器模式工作的,实际的工作原理,如下
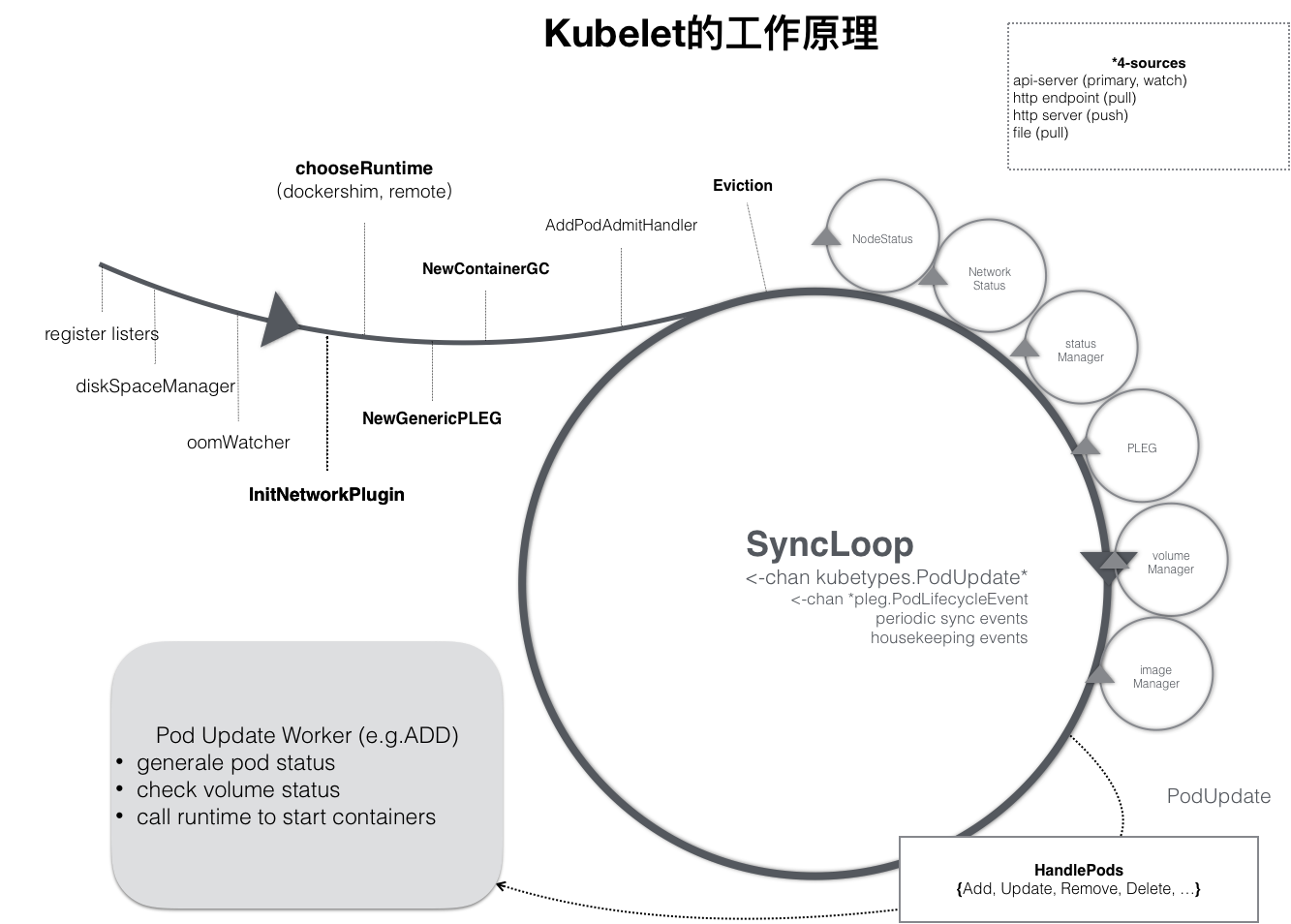
整个kubelet的工作核心,就是一个控制循环,SyncLoop,驱动这个控制循环的事件,分为四种
Pod更新事件
Pod生命周期变化
kubelet本身设置的执行周期
定时的清理事件
跟其他的控制器类似,kubelet启动的时候,需要设置Listers,注册关心的各种事件的Informer,这些Informer,就是SyncLoop需要处理的数据的来源
kubelete还维护着很多其他的子循环,这些小循环的名字,被称为某某Manager,比如Volume Manager,Image Manager等等
这些小循环的责任,就是通过控制器模式,完成kubelet的某些具体职责,比如Node status Manager
就是负责响应Node的状态变化,将Node的状态手机起来,并通过Heartbeat的方式上报给APIServer.比如CPU Manager,负责维护Node的CPU核的信息,以便于通过cpuset的方式请求CPU核,就够正确的管理CPU核的使用量和可用量
这个SyncLoop,如何根据Pod对象变化,操作容器的?
kubelet就是通过Watch机制,监听了自己相关的Pod对象的变化,这些Watch的过滤条件是该Pod的nodeName字段和自己相同,kubelet会将这些Pod缓存在自己的内存中
一个Pod完成了调度,和一个Node绑定起来,就会触发kubelet在控制循环中注册的Handler,从而开始判断Pod的状态,调度ADD或者UPDATE对应的处理方式
如果是ADD事件,kubelet就会为这个新的Pod生成对应的Pod Status,检测Pod所声明使用的Volume已经准备好了,然后调用下层的运行时容器的定义,创建对应的容器
如果是UPDATE事件,Kubelet就会根据Pod对象的具体变化,调用下层运行时容器的重建
然后真正调用下层容器运行时的执行过程,并不会直接调用Docker的API,而是通过一组CRI的gRPC接口
当然一开始的时候,Kubernetes是直接调用Docker的API来创建和管理容器的,Docker项目风靡全球后不久,就推出了rkt项目和Docker正面竞争,所以Kubernetes为了大一统,每一次重要功能的更新,都不得不考虑Docker和rkt项目两部分代码
由于rkt项目用户数量级别不如Docker,那么每次维护两个项目,实在是增大了维护的成本
那么我们就可以考虑到,将kubelet对容器的操作,统一的抽象为一个接口,kubelet就只需要和这个接口打交道了,作为具体的容器项目,只需要实现这个接口,把那个暴露gRPC服务就可以了
有了CRI之后,Kubernetes以及kubelet本身的架构,就是如下的示意图,
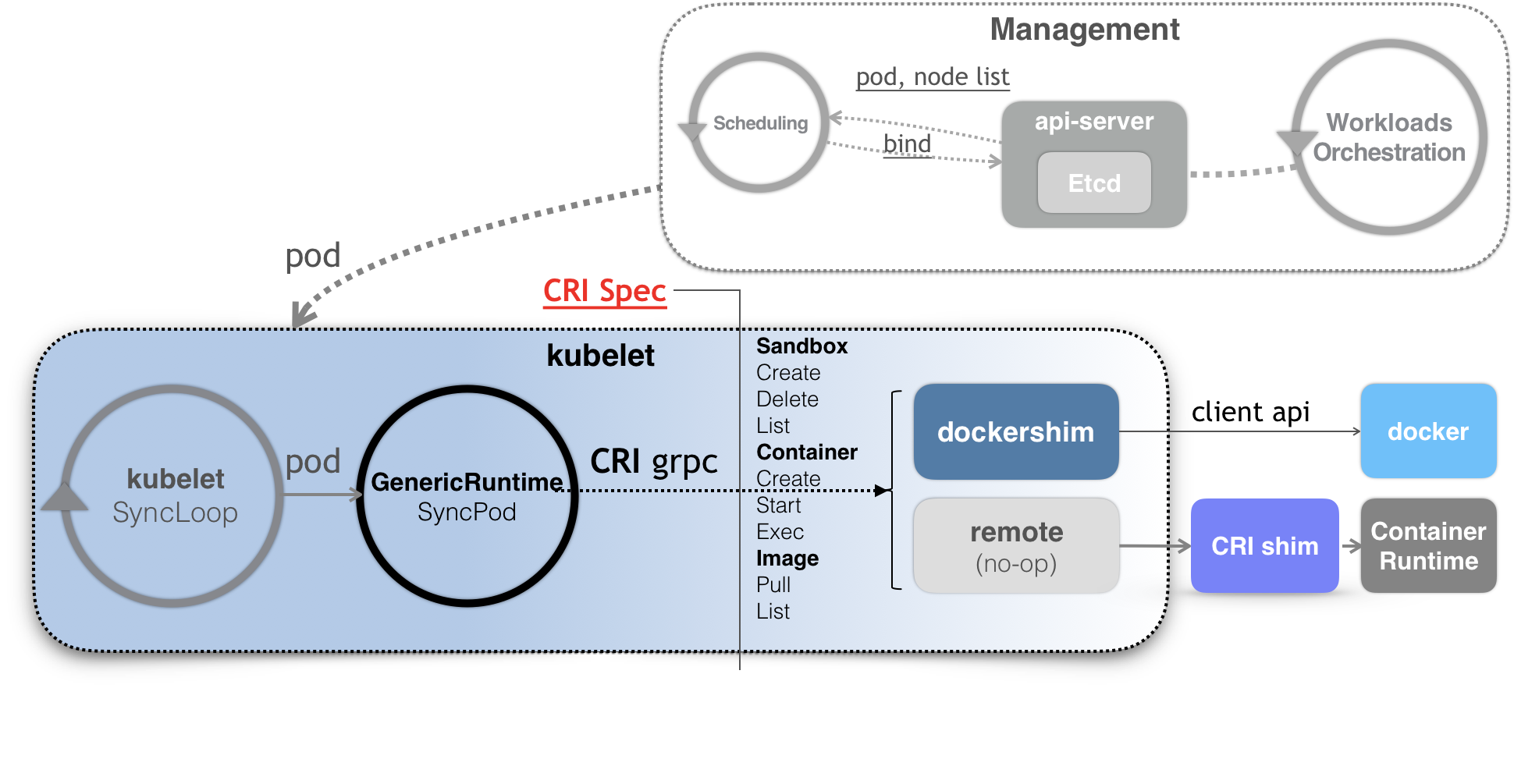
Kuberenetes通过编排能力创建了一个Pod之后,调度器就会为这个Pod选择一个具体节点运行,kubelet会通过讲解过的SyncLoop来判断执行的具体操作,比如创建一个Pod,那么此时,Kubelet就会调用一个叫做GenericRuntime的通用组件来创建Pod的CRI请求
这个CRI请求,如何响应呢?
如果运行时容器项目是Docker的话,那么负责响应的就是一个叫做Dockershim的组件,将CRI请求中的内容拿出来,然后组成合格的请求发给Docker Daemon
需要注意的是,Kubernetes中,dockershim仍然是kubelet代码中的一部分,未来必将从Kubelet中移除出来
而不是Docker的话,就需要在每个宿主机上单独安装一个响应CRI的组件,这个组件被称为CRI shim,扮演kubelet和容器项目之间的垫片,实现CRI的接口,然后翻译成对于的容器API操作
本章总结一下,就是介绍了SIG-Node的职责,以及kubelet组件的原理
那么思考一下,我们如何部署kubelet组件的呢?
使用原生部署或者容器部署吧