之前,我们说了top vmstat pidstat等工具,排查高CPU使用率的问题,然后使用perf top工具
定位了内部的函数,但是还有些情况下,系统的CPU使用率很高的时候,不一定能找到相对应的高CPU使用率的进程
我们拿着一个案例来进行查看
我们使用Docker来进行相对应的校验工作
并使用ab进行测试
我们将一台服务器作为web服务器,模拟性能问题,另一台作为Web服务器的客户端,来给Web服务增加压力请求
然后两个终端,分别登录一下
第一个终端,运行Nginx和PHP应用
然后第二个终端,进行ab测试,查看对应的响应工作
我们测试一下Nginx的性能,利用的就是上面的ab命令
ab -c 100 -n 1000 http://192.168.0.10:10000/
ab的输出可以看到,Nginx的每秒平均请求数,只有87多一点,性能有点差的,那么,哪里出现了问题?
我们使用top和pidstat进行观察一下
这样,我们在第二个终端,继续ab压力测试,方便观察
ab -c 5 -t 600 http://192.168.0.10:10000
第一个终端运行top,观察起CPU相关情况
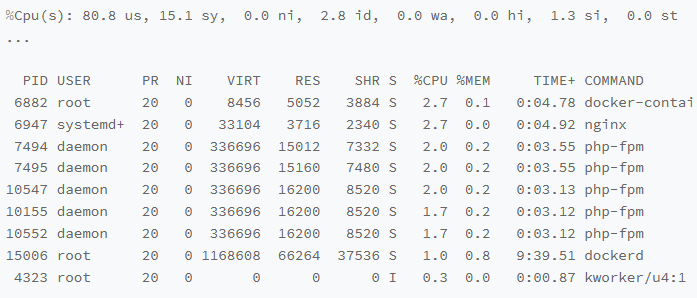
top看出来,最高的CPU使用率只有2.7%
那么看起来并不是很高,那么看系统CPU使用率这一行,会发现系统整体CPU使用率是很高的,用户使用率us达到了80%,那么按照这个思路,我们要猜测对应的用户进程是否出现了问题
分析一下进程列表,并没有发现有可疑的进程
docker进程只有2.7并不高
Nginx和php-fpm也并不高,只有2%的CPU使用率
后面的进程占用比更加的小了
那么,明明用户CPU使用率都已经80%了,可是挨个的分析了进程列表,高CPU使用率的进程并没有看见,看来top并不好使,那么是否可以利用其他的工具来进行查看CPU进程呢?
比如pidstat?
利用pidstat来进行查看终端,获取到对应的数据
pidstat 1
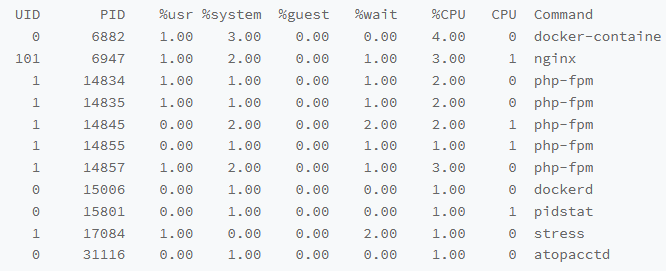
这样,获取到了对应的CPU使用率
最高的Dokcer和Nginx也只有 4%和3%
所有进程的CPU加起来,都不过21%,那么user的使用率是如何达到80%的?
为此,我们再次查看对应的top信息
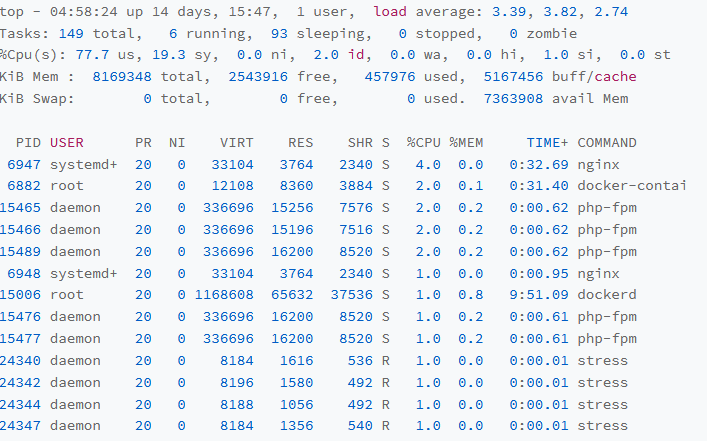
看一下top的task信息,原本只有5个进程,但是却有6个进程,而且实际上Running状态的进程,是几个Stress进程,这几个Stress进程是不是我们可以入手的情况
我们利用pidstat进行分析
pidstat -p制定进程的PID,从上面的top结果中,找到这几个进程的PID,比如,一个24344
pidstat -p 24344
![]()
输出为空,这是pidstat出现问题了吗,
这样我们再使用ps来进行交叉校验一下
ps aux | grep 24344
发现还是没有输出,是不是这个进程已经不存在了?
最后使用top再校验一次
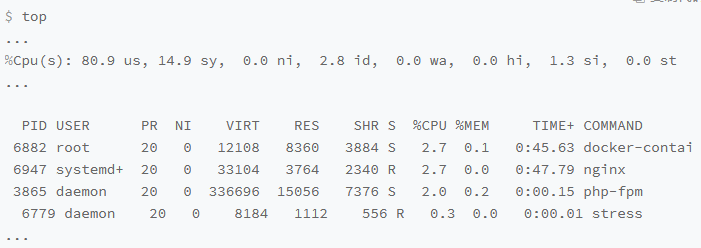
发现的确没有这个进程了,但是问题还在,user的使用率还是高达80%
但是stress换了一个马甲,变为了6779
进程的PID在变,这说明什么?要么是进程不断地重启,要么就是新的进程
重启的话,说明进程不断的崩溃,说明进程配置有问题?
新的进程说明是短命令进程,利用exec进行调用的
至于stress,是一个常用的压力测试工具,我们也说过
我们需要查看这个stress的父进程关系
常见的查找法,可以利用pstress进行显示进程之间的关系

说明父进程是php-fpm,进程数量不止一个
找到了父进程之后,就可以进入app的内部分析了
查看对应的源码

对应的app/index.php的源码
这样,源码中的每个请求都会调用一个stress命令,模拟IO压力,这就是使用率的根源
但是stress模拟的是IO压力,但是iowait没有升高,升高的却是用户CPU,这是为什么呢?
我们修改源码将stress命令打印出来
查看信息,发现错误信息
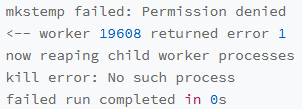
这是因为大量的stress在启动初始化的时候失败,导致的用户CPU使用率升高
再次确认这个猜测
我们再次使用perf 来记性查看和记录
我们使用第一个终端运行perf record -g命令,然后等待一段时间后进行退出
运行perf report解读报告
对应的内核栈基本如下所示
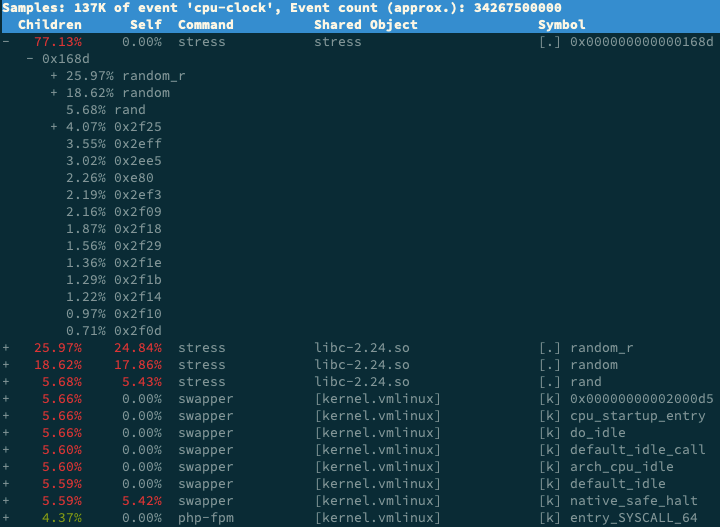
stress占用了所有CPU时钟事件的77%,stress调用栈中最高的就是random函数了,这是CPU使用率的元凶,优化就相对简单了,删除stress的调用即可
那么,对于这种stress这种短时进程的话,有没有什么更加方便的工具呢?可以参考使用execsnoop进行
execsnoop监控上述的案例,会直接得到stress进程的父进程和命令行工具,以及大量的stress不断的启动
execsnoop使用了ftarce,是一种动态追踪的技术,后续会讲到
对于可能存在的CPU升高,但是不好查看原因的,要首先考虑
应用中直接调用其他二进制陈故乡,这些程序运行时间比较短,通过top等工具也不容易发现
应用本身不断的崩溃重启,占用过多的CPU
对于这种问题,可以使用pstree或者execsnoop找到父进程,进行排查