伴随着AlphaGO的走红和TensorFlow项目的异军突起,一场名为AI的技术革命从学术界蔓延到了工业界
当然,机器学习或者人工智能,并不是啥新鲜玩意,不过带给Kubernetes的,就是在Kubernetes集群上运行TensorFlow等机器学习框架需要的训练和服务任务,除了前面说的Job,Operator等离线作业管理需要用到的编排概念之外,还有就是对GPU等硬件加速设备管理的支持
对于云上的用户,在GPU的支持上,基本的诉求很简单,只要在Pod的YAML中,声明某个容器需要的GPU个数,那么Kubernetes创建的容器就应该出现对应的GPU设备,以及对应的驱动目录
以NVDIA的GPU设备为例,容器被创建后,这个容器中会出现GPU设备概念和GPU的驱动目录
不过,Kubernetes并没有为GPU在Pod的API对象设置一个资源类型字段,而是使用了一个名为Extended Resource ER的特殊字段来负责传递GPU的信息,如下
| apiVersion: v1
kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: – name: cuda-vector-add image: “k8s.gcr.io/cuda-vector-add:v0.1” resources: limits: nvidia.com/gpu: 1 |
我们在resources字段中,定义了字段名为nvidia.com/gpu,值是1,这个Pod声明要使用一个NVDIA类型的GPU
而在kube-scheduler中,并不关心这个字段的具体含义,而是在计算的时候,直接减去或者加上对应的数值,Extended Resource,就是Kubernetes为用户设置的一种对自定义资源的支持
在Kube-scheduler里面,并不关心这个字段具体含义,只会在计算的时候,一律将调度器里保存的类型的可用量,直接减去Pod声明的数值
当然,为了可以计算,宿主机节点本身,需要能够向API Server汇报这个类型资源的可用数量,在Kubernetes中,各个类型的资源可用量,就是Node中Status字段可用内容,
| apiVersion: v1
kind: Node metadata: name: node-1 … Status: Capacity: cpu: 2 memory: 2049008Ki |
我们定义了Status中的cpu数量为2个
我们还需要定义对应的Node节点中的GPU数据,我们需要使用PATCH API来对这个Node对象进行更新操作
PATCH操作完成后,就可以看到Node的Status变为了如下
| apiVersion: v1
kind: Node … Status: Capacity: cpu: 2 memory: 2049008Ki nvidia.com/gpu: 1 |
这样,缓存中也会更新了缓存中记录的GPU类型的数量为1
在Kubernetes的GPU支持方案中,我们不需要做关于Extended Resource的配置操作,对所有硬件加速管理的功能,都是交给了叫做Device Plugin的插件进行负责的,这其中,就包括了对这个硬件的Extended Resource进行汇报的逻辑
Kubernetes的Device Plugin机制,可以显示为如下所示的示意图
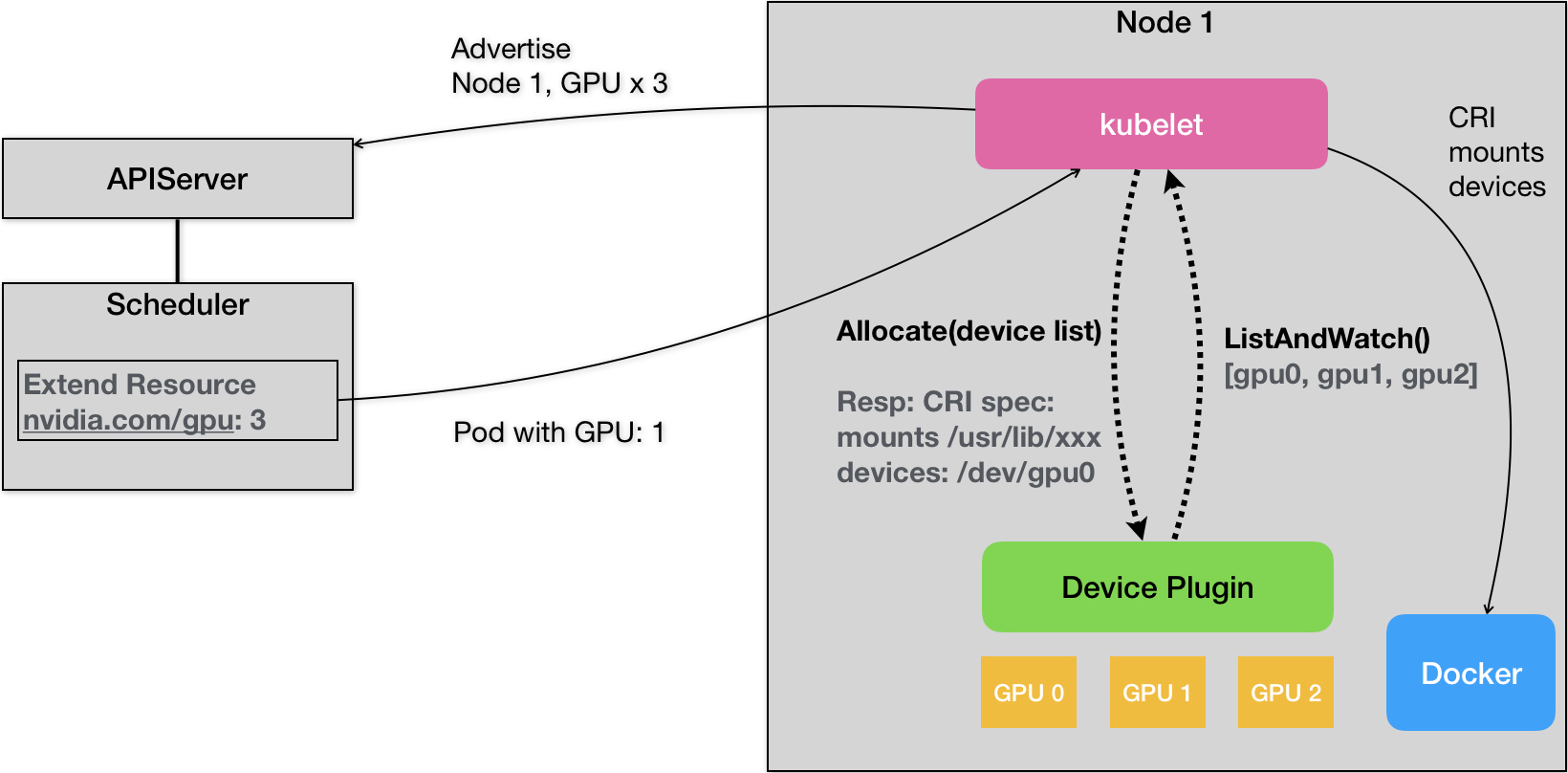
对于每一个硬件设备,都需要和对应的Device Plugin进行管理,这些Device Plugin,都会通过GRPC的方式,和kubelet连接起来,以NVDIA GPU为例,对应的插件叫做,NVDIA GPU DEVICE plugin
这个Device plugin会通过一个ListAndWatch的API,定期向kubelet汇报这个Node上的GPU列表,在例子中,一共有三个GPU,这样,Kubelet中就会获取到这会有三个GPU列表,但是ListAndWatch上报的信息,只有本机的GPU ID list,并没有GPU设备本身的信息.
故当一个Pod想要使用GPU的时候,只需要在本文一开始给出的例子一样,在Pod的limits字段声明 nvidia.com/gpu: 1,那么接下来,Kubernetes就会在缓存中,寻找GPU数量满足条件的Node,将缓存的GPU数量减一后进行绑定.
调度成功后的Pod信息,就会被kubelet拿来做容器操作,当kubelet发现Pod需要一个GPU,就会向Dervice Plugin发起一个Allocate()请求,请求的参数,正是分配给容器的设备ID列表
然后Device Plugin收到了Allocate请求后,就会根据kubelet传来的设备ID,从Device Plugin找到这些设备对应的设备路径和驱动目录,在NVIDIA Device Plugin的实现里,定期访问nvida docke插件,获取本机上的GPU信息
而被GPU的设备目录和驱动目录信息都会推给kubelet,kubelet就完成了一个容器分配GPU的操作,接下来,kubelet就会将这些信息给与创建容器的CRI请求,发给Docker,让Docker完成挂载
这样就是为一个Pod分配一个GPU的流程
对于其他类型硬件来说,想要在Kubernetes所管理的容器使用这些硬件的话,需要遵循上述Device Plugin的流程来实现如下的Allocate和ListAndWatch API:
| service DevicePlugin {
// ListAndWatch returns a stream of List of Devices // Whenever a Device state change or a Device disappears, ListAndWatch // returns the new list rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {} // Allocate is called during container creation so that the Device // Plugin can run device specific operations and instruct Kubelet // of the steps to make the Device available in the container rpc Allocate(AllocateRequest) returns (AllocateResponse) {} } |
Kubernetes实现了很多的硬件插件,比如FPGA等
我们在本片中说了Kubernetes对于GPU的管理方式,以及使用的Device Plugin机制,Device Plugin的设计,长期是以Google Cloud用户需求为主导的,所以还是有一定区别的
GPU等硬件设备的调度,交给了kubelet,但是kubelet只是从自己的Node中,根据设备数目去定义使用,如果GPU的使用调度上要求比较复杂,如果设备是异构的,不能简单的使用数目去定义的时候,如果想要使用指定的GPU的话,简单的Device Plugin就不能处理了
在很多场景下,我们希望在调度器进行调度的时候,可以根据整个集群中的某种硬件设备的全局分布,做出最佳的调度
此外,上述Device Plugin的设计,也使得Kubernetes中,缺少一种能够对Device进行描述的API对象,如果硬件对象很复杂并且Pod很关心,那么Device Plugin是没有办法支持的
Device Plugin的设计和实现中,Google 的工程师也不愿意添加一些扩展性的参数,导致无法很好地自定义
那么如何对这些Device Plugin进行改动呢?
现在的设计是否已经够用了吗
现在的资源必然不够用,因为只能按照整数类型的分配,导致很多时候,不能共享资源
无法做到按需修改api