我们说了如何通过NAT方式与物理网络
每一台物理机上面安装了Docker之后,默认分配一个127.17.0.0/16的网段,一台机器上新创建第一个容器,一般都会给127.17.0.2这个地址,当然一个机器号,但是容器里面可以部署应用
这样是单体应用,就一个进程,所有的代码逻辑都在这个进程里面,上面的模式没有问题,只能通过NAT来访问
但是,应用需要很快的部署,很快的进行高并发的请求的能力,所以单体应用已经过去了,现在都是微服务的天下,现在是集团军作战了
容器作为集装箱,保证应用不同环境下快速迁移,提高迭代的效率,但是形成容器集团军,还需要一个集团军作战的调度平台,就是Kubernetes,可以灵活将一个容器调度到任何一个机器上,并且某个应用扛不住的时候,只要在Kuberntes上修改容器的副本数,一个应用变成八个,而且都能提供服务
集团军作战有个重要的问题,就是通信,就好比A部队实时知道B部分位置变化?两者如何通信?
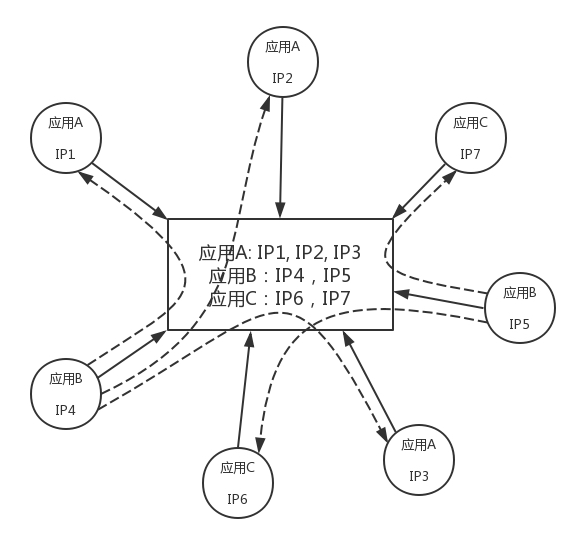
第一个问题位置变化,往往是通过注册中心管理的,这是应用自身做的,当一个应用启动的时候,将自己所在的环境的IP地址和端口,注册到注册中心中,当其他的应用请求他的时候,去寻找指挥部问在哪里就好了,当某个应用发生了变化,例如一台机器挂了,容器要迁移到别的机器,IP变化了,就需要重新注册,其他的应用请求他的时候,能够从指挥部得到新的位置
接下来,如何通信
在NAT的模式下,多个主机通信是有一定的问题的,在物理机A上应用A看到的IP是容器A的,
172.17.0.2
物理机B上的应用B看到的IP是容器B,可能也是172.17.0.2,都注册到注册中心的时候,注册中心是这样的
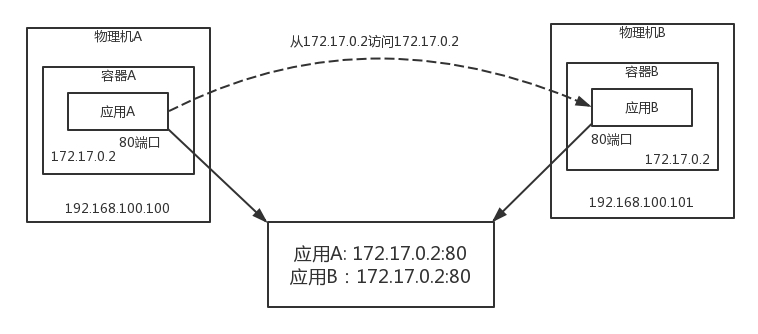
这样,就导致可能出现自己访问自己的问题
如何解决呢?可以不去注册容器内的IP地址,而是注册物理机的IP地址,端口是映射之前的物理机的端口
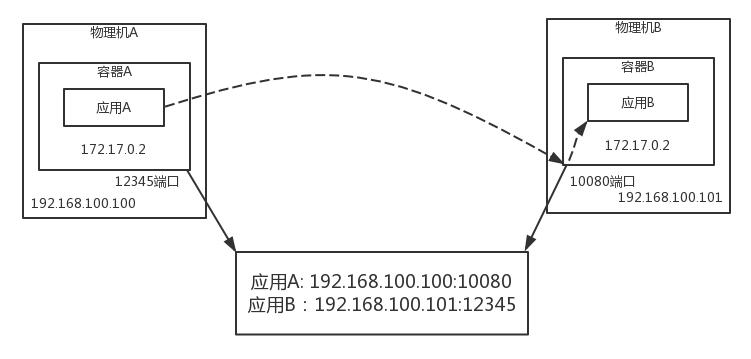
应用是存在容器内的,怎么知道物理机上的IP地址和端口呢?这一般是运维人员配置的,应用很难感知到,而且让容器内的应用意识到容器外的环境,是非常不好的设计
那么,Kubernetes作为集团军作战管理平台,提出了指导意见,说是网络模型要变平,但是没说具体实现方案,后来就出现了很多实现,Flannel就是其一
对于IP冲突的问题,如果每一个物理机都是网段172.17.0.0/16,肯定会冲突,但是整个网段实在太大了,一个物理机上不会存在那么多的容器,所以在每个物理机上,各自存在一个小网段,每个网段不同,就能保证不冲突
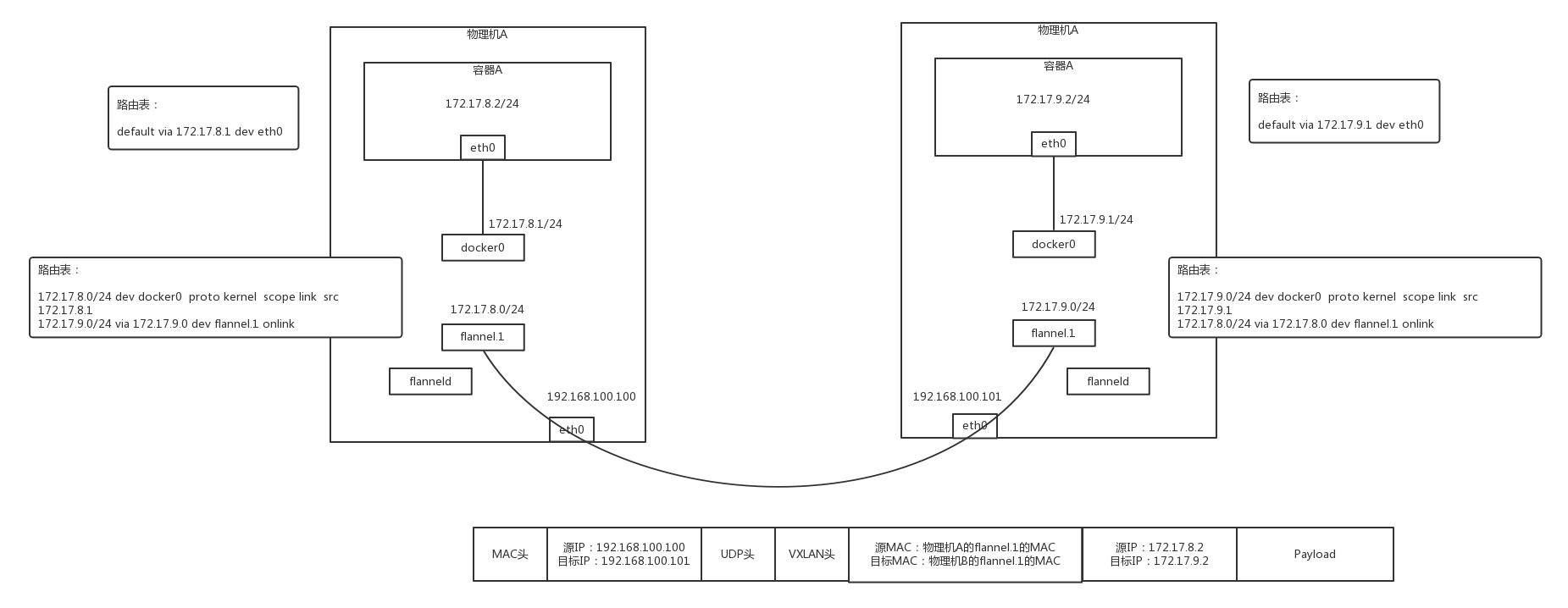
例如物理机A的网段是172.17.8.0/24 物理机B的网段是172.17.9.0/24,两个容器的网段不样,IP地址不一样,这样,就能看出哪个是本端,哪个是对端的了
那么物理机A上的容器如何访问到物理机B上的容器呢?
通过Overlay方式?
这时候,Flannel使用了UDP实现了Overlay网络
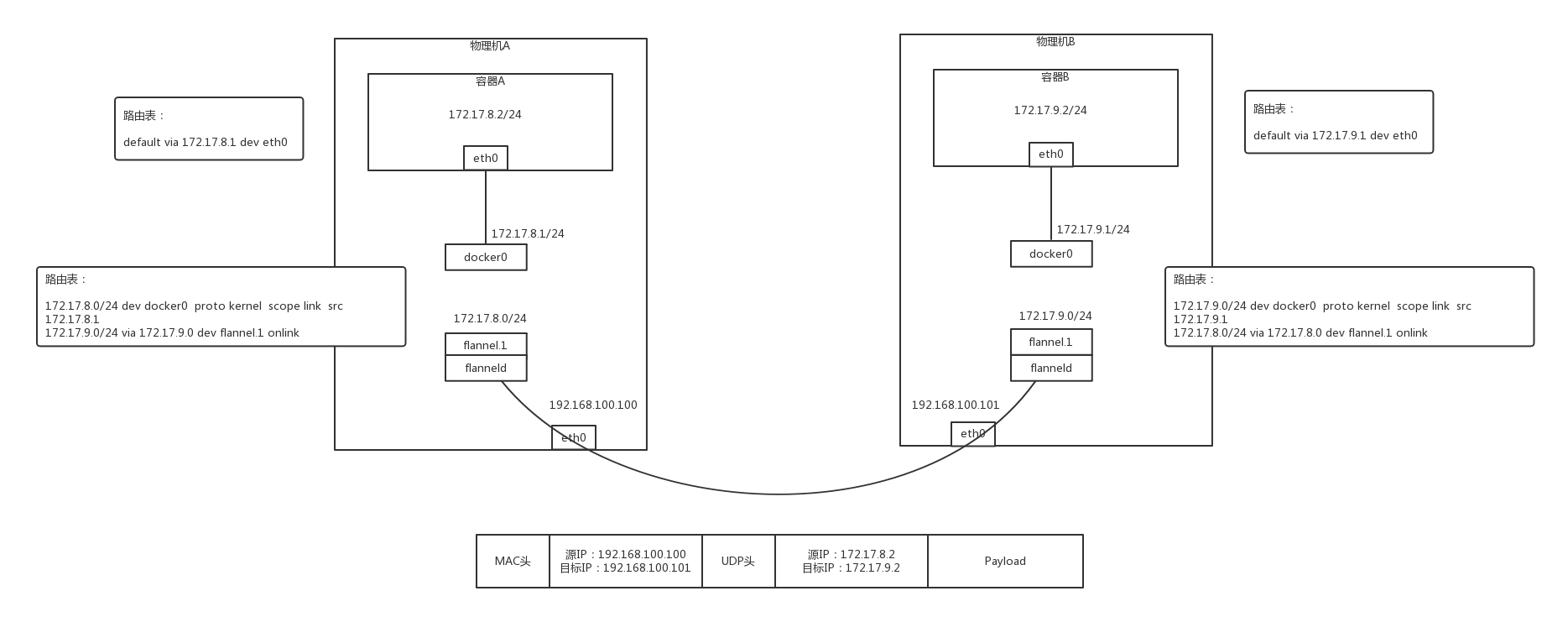
从容器A到容器B,在容器A内部可以看到自己的IP是172.17.8.2/24,里面设置了默认路由规则 default via 172.17.8.1 dev eth0
如果要访问 172.17.9.2,就会发往这个默认的网关,172.17.8.1,就是docker0网桥的IP地址,整个物理机上的容器都可以连接到这个网桥上
在物理机上,查看路由策略,会有一条172.17.0.0/24 via 172.17.0.0 dev flannel
即为172.17.0.0这个网段的所有的包,都走flannel.1这个网卡
这个网卡怎么出来的呢?每个物理机上,都跑一个flanneld进程,这个进程打开/dev/net/tun字符设备的时候,就出现了这个网卡
类似qemu-kvm,打开这个字符设备的时候,物理机上会出现一个网卡,所有发给这个网卡上的网络包会被都会qemu-kvm接收进来,变为二进制串,但是flanneld不需要,只需要被直接读进去,进行处理
物理机A上的flanneld会将网络包封装在UDP里面,然后外层加上物理机A和物理机B的IP地址,发给物理机B的flanneld
为何是UDP呢?因为不想在flanneld之间建立两个连接,UDP没有连接的概念,可以任意的发送
物理机B上的flanneld收到包之后,解开UDP的包,将里面的网络包拿出来,从物理机的flannel.1网卡发出去
物理机B上,有路由规则 172.17.9.0/24 dev docker0 protp kernel scope link src 172.17.9.1
然后将包发给了docker0,docker0将包转给容器B,通信成功
对于这种跨物理机的通信,还可以借鉴虚拟机的成熟方案,VXLAN,Flannel可以整合VXLAN
使用了VXLAN,就不用打开一个TUN设备了,而是建立一个VXLAN的VTEP,如何建立呢?可以通过netlink通知内核建立一个VTEP的网卡flannel.1,而netlink,就是在用户态和内核态通信的机制
然后网络包从物理机A上的容器A发给物理机B上的容器B的时候,在容器A的里面通过默认路由到达物理机A的docker 0网卡,然后通过默认路由走到了flannel.1,这时候就是一个VXLAN的VTEP了,可以对网络包进行封装
内部的MAC这样写,原为物理机A的flannel.1的mac,目标为物理机B的flannel.1的MAC地址,外面加上VXLAN的头
外层的IP这样写,原为物理机A的IP,目标为物理机B的IP地址,外面加上物理机的MAC地址
这样就能通过VXLAN将一个包转发到另一个机器,从物理机B的flannel.1上解包,变成内部的网络包,通过物理机B上的路由转发到docker0,转发到容器B里面,通信成功
本章总结:
基于NAT的容器网络模型在微服务的架构下,可能存在的两个问题,一个是IP重叠,一个是端口冲突,通过Overlay的网络机制来保证跨节点的连通性
Flannel是跨节点的网络方案之一,提供的Overlay的方案主要有两种,一种是在UDP下封装,一种是VXLAN的封装,VXLAN更加好点
课后思考:
1.通过Flannel的网络模型可以实现容器和容器直接跨主机的相互访问,容器内部访问外部的服务怎么融合呢?
2.Overlay的网络毕竟做了一次网络虚拟化,有没有更加性能高的方案呢?
Flannel的backend除了UDP和VXLAN之外,还有一个模式就是host-gw,通过主机路由的方式,将请求发给容器外部的应用,但是有个约束,就是宿主机和其他物理机要在一个Vlan或者局域网之中
或者,在容器的Pod内到外部网络是通过docker引擎在iptables的POSTROUTING中的MASQUERADE规则实现的,将容器的地址伪装为了node IP出去,在回来的时候将包nat回容器的地址
如果是一个固定的域名套给了外部的服务,需要用到Kubernetes的headless service的ExternalName,可以将某个外部的地址赋值给一个Service的名称,当容器访问这个名字 的时候,访问到一个虚拟的IP.在容器所在的节点上,由iptables规则映射到外部的IP地址