一般来说对于整个项目,或者说整个任务的层面去看待问题,但是其实具体来说,所有的异步编程,就是基于了一个分工的思路来描述问题的
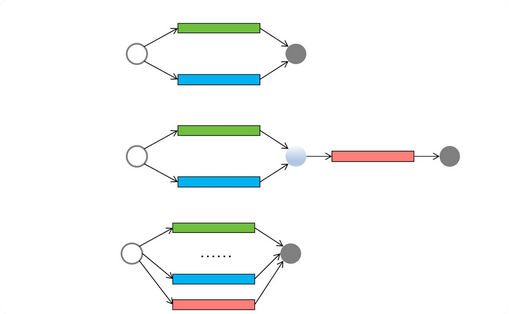
基本上,异步编程就是采用了一个分治的任务模型
分治,简单来说,就是分而治之,一个解决复杂问题的思维方式
将一个复杂的问题分为多个相似的小问题,然后把子问题进一步的进行划分,直到分不可分
分治思想在很多领域都有所应用,例如算法领域的归并 快速排序 二分查找
Java领域,提供了Fork/Join框架去支持分治任务
分治模型可以概括为两个阶段,第一各阶段是任务分解,将任务迭代的分解为了子任务,直到分不可分,第二个阶段是合并,将子任务的结果合并,获取到最终结果
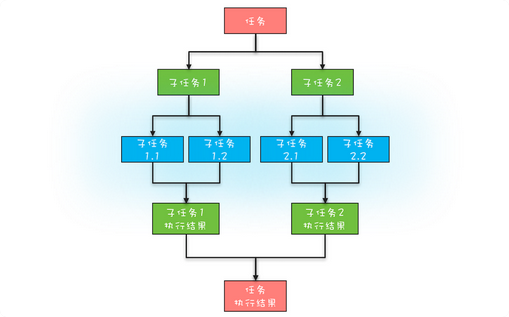
对于每个线程来说,只是规模变小了,但是算法是相同的
在Java汇总Fork/Join的具体实现是ForkJoinPool线程池和分治任务ForkjoinTask,就是普通的线程池和Runnbale接口的关系
ForkJoinTask是一个抽象类,其中分为两个核心的任务fork() 和 join()
| ForkJoinTask 有两个子类——RecursiveAction 和 RecursiveTask,它们都是用递归的方式来处理分治任务的。
这两个子类都定义了抽象方法 compute(), 不过区别是 RecursiveAction 定义的 compute() 没有返回值 而 RecursiveTask 定义的 compute() 方法是有返回值的 |
简单的操作,我们可以利用这个框架去实现计算斐波那契数列
分为了两步
分别是创建分治任务线程池和计算斐波那契数列的分治任务
分治任务需要实现compute()方法
public static void main(String[] args) {
// 创建分治任务线程池
ForkJoinPool fjp = new ForkJoinPool(4);
// 创建分治任务
Fibonacci fib = new Fibonacci(30);
// 启动分治任务
Integer result = fjp.invoke(fib);
// 输出结果
System.out.println(result);
}
// 递归任务
static class Fibonacci extends
RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n – 1);
// 创建子任务
f1.fork();
Fibonacci f2 = new Fibonacci(n – 2);
// 等待子任务结果,并合并结果
return f2.compute() + f1.join();
}
}
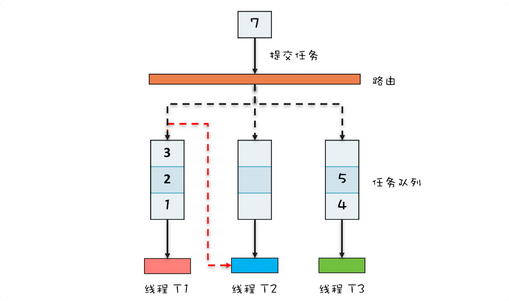
其工作原理很简单
是一个生产者-消费者的实现,内部有多个任务队列,还维护着多个工作线程去对应着队列
当我们提交一个任务时候,会创建出子任务,子任务会提交到对应的任务队列中
但是一个工作线程的任务队列空了,不会没活干了,还有一种任务窃取的机制,如果一个线程空了之后,那么他会尝试着从其他的线程的队列中拿去队列,为了保证拿取任务的线程安全
我们将整个任务队列设计为双端的,线程本身从队首拿取任务,窃取者从队尾拿取任务
那么就可以将一个文件拆分更小的文件,然后一直拆分下去,直到只有一行,然后统计这一行中单词数量,最后join进去
static void main(String[] args) {
String[] fc = {“hello world”,
“hello me”,
“hello fork”,
“hello join”,
“fork join in world”};
// 创建 ForkJoin 线程池
ForkJoinPool fjp = new ForkJoinPool(3);
// 创建任务
MR mr = new MR(fc, 0, fc.length);
// 启动任务
Map<String, Long> result = fjp.invoke(mr);
// 输出结果
result.forEach((k, v) -> System.out.println(k + “:” + v));
}
//MR 模拟类
static class MR extends RecursiveTask<Map<String, Long>> {
private String[] fc;
private int start, end;
// 构造函数
MR(String[] fc, int fr, int to) {
this.fc = fc;
this.start = fr;
this.end = to;
}
@Override
protected Map<String, Long> compute() {
if (end – start == 1) {
return calc(fc[start]);
} else {
int mid = (start + end) / 2;
MR mr1 = new MR(fc, start, mid);
mr1.fork();
MR mr2 = new MR(fc, mid, end);
// 计算子任务,并返回合并的结果
return merge(mr2.compute(), mr1.join());
}
}
// 合并结果
private Map<String, Long> merge(
Map<String, Long> r1,
Map<String, Long> r2) {
Map<String, Long> result =
new HashMap<>();
result.putAll(r1);
// 合并结果
r2.forEach((k, v) -> {
Long c = result.get(k);
if (c != null) {
result.put(k, c + v);
}else {
result.put(k, v);
}
});
return result;
}
// 统计单词数量
private Map<String, Long> calc(String line) {
Map<String, Long> result = new HashMap<>();
// 分割单词
String[] words = line.split(“\\s+”);
// 统计单词数量
for (String w : words) {
Long v = result.get(w);
if (v != null) {
result.put(w, v + 1);
}else {
result.put(w, 1L);
}
}
return result;
}
}
最后要提一嘴,其核心组件是ForkJoinPool,支持任务窃取机制,所有的线程工作量均衡,但是一般来说一个线程池同时面对CPU操作,IO操作的话
可能会导致因为一个很慢的IO操作拖累整个任务池的性能,建议采用不同的ForkJoinPool来执行不同的类型计算任务