1.join语句的写法,如何书写合适的join
使用join的时候,如果知道两个表的大小,最好使用straight_join,如果使用left join呢?
左边的表一定会是驱动表吗?
两个表中如果包含多个条件的等值查询,是都写到on里面,还是只把一个条件写到on里面,其他条件写到where中?
为了方便解析,构建了两张表a b
|
create table a(f1 int, f2 int, index(f1))engine=innodb;
create table b(f1 int, f2 int)engine=innodb; insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6); insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8); |
表 a,b中都有f1和f2,不同的是a上的f1有索引,往两个表上插入了6个记录,这样同时在表a b相同的数据有6行
然后进行两个语句的分析
select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2)
select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2)
这两个语句分别为Q1和Q2,首先是这两个语句的执行结果
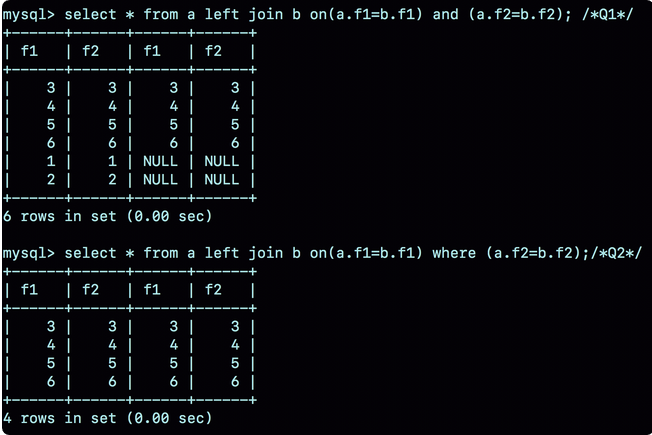
可以看出 Q1返回的数据行是6行,其中包含了b的null
Q2返回的数据是4行,其中最后的两行,由于表b中没有匹配的字段,结果集并不存在
Q1的explain为

1.将表a的内容读入join_buffer中,因为select * 那么字段 f1 f2都放在了join_buffer
2.顺序扫描表b,对于每一行数据,都进行判断join条件,也就是(a.f1=b.f1) and (a.f2=b.f2)
对于满足条件的记录,作为结果集一行返回,如果语句中有where子句,就需要先判断where部分满足条件后,再返回
3.在表b扫描后,对于没有匹配的表a的行,把剩余字段补上Null,再放入结果集中
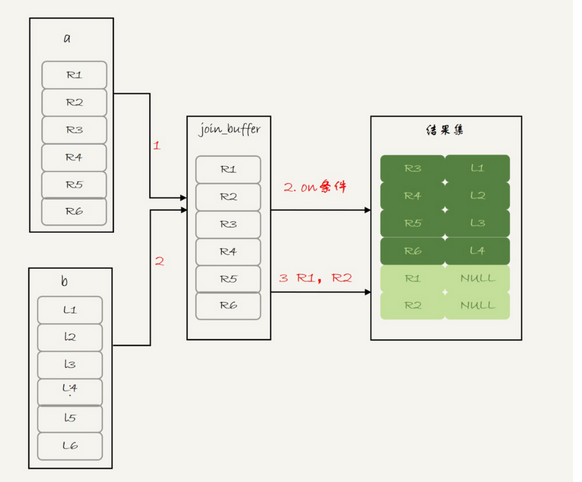
那么语句Q2的查询结果中少了最后两行,是不是没有执行步骤3呢?
Q2的explain如下

这个explain执行中,可以看出,这个表是以表b为驱动表的,,一个join语句的Extra字段扫描都没有
写的话,就是Index Nested-Loop Join算法
语句Q2的执行流程为,顺序扫描表b,每一行都用b.f1到表a中去查,匹配到记录后判断a.f2=b.f2是否满足,满足条件的话,就作为结果集的一部分去返回
为什么Q1 Q2的执行流程差距那么大呢?
因为优化器基于Q2这个查询语义做了优化
首先说,MySQL中Null如果和任何值进行等值判断和不等值判断,结果都是Null,这里要包括 select Null = Null
那么Q2语句中,where a.f2=b.f2就表示,查询结果中,不会包含b.f2为Null的行,这个left join的语义就表示 找到这儿两个表相同的 f1,f2对应相同的行,对于表a中有,表b中没有的行,就放弃
这样,这个left join的语义和join一样的
实际上,优化器把这个left join改为了join语句,因为表a的f1上有索引,就把表b作为了驱动表,就可以用上了NLJ算法,在执行explain之后,在执行show warnings,就能看到实际的语句

实际上用的就是join语句,而非left join
如果需要left join的语义,就不能把被驱动表的字段放在where中做等值或者不等值判断,必须都写在on中
但是如果是join语句呢
select * from a join b on(a.f1=b.f1)and (a.f2=b.f2)
select * from a join b on(a.f1=b.f1)where (a.f2=b.f2)
然后看一下explain和show warnings的方法
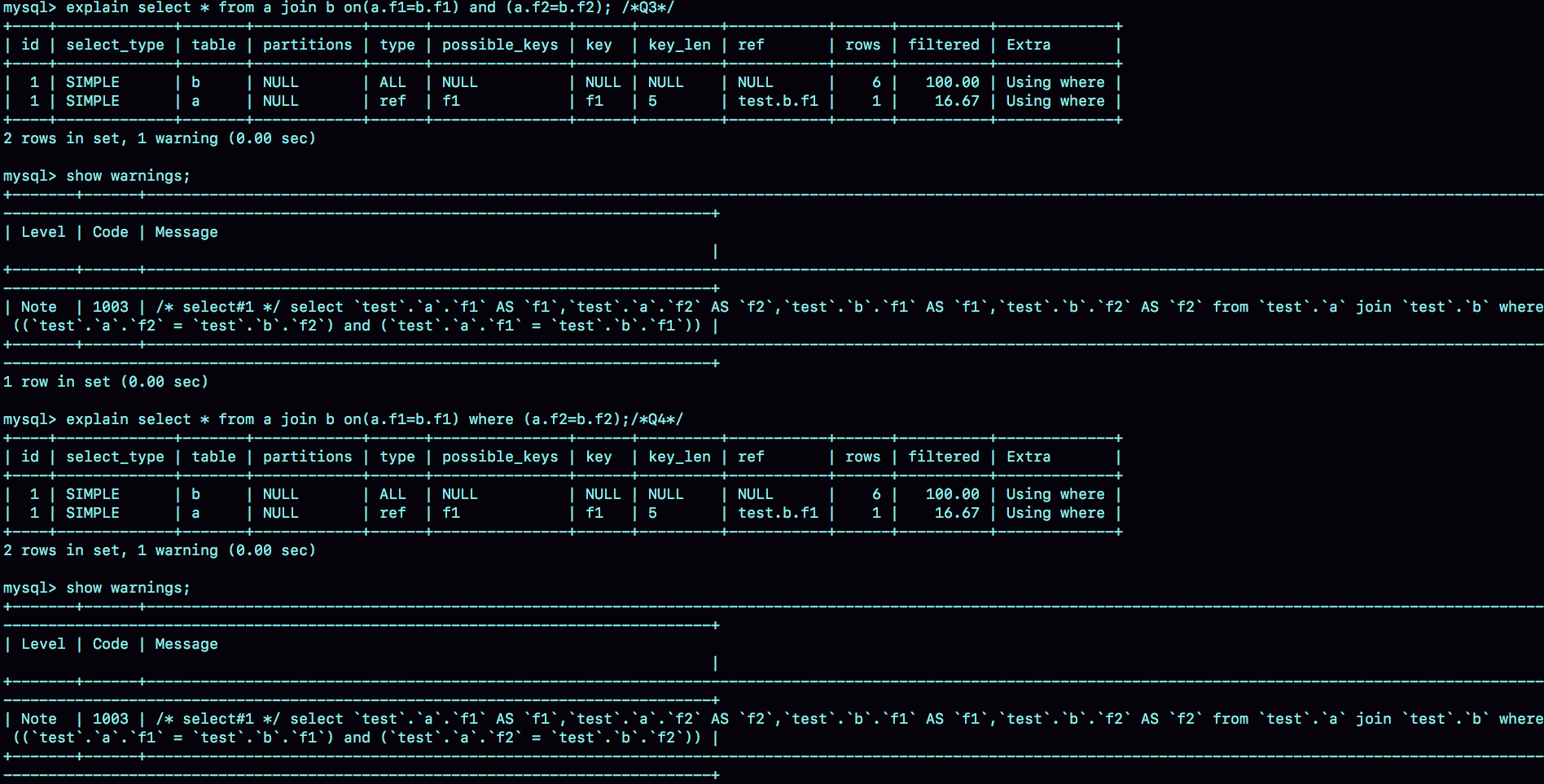
都会选择b作为驱动表,去选择有索引的a表作为被驱动表,
两个语句都被改写为了
select * from a join b where (a.f1=b.f1) and (a.f2=b.f2)
这种情况下,放在on或者where中没有任何区别了
问题2:Simple Nested Loop Join的性能问题
虽然BNL和Simple Nested Loop Join都是需要判断N*M次数据
而且都从文件中读取数据到内存中遍历,为什么BNL的性能较好呢
这是因为BNL会首先顺序去读驱动表中的每一行数据,读入到join_buffer中,顺序遍历被驱动表的所有行,每一行数据进行匹配,成功后作为结果集的一部分返回
Simple Nested Loop Join则只是每次去读驱动表中的一行数据,到被驱动表上做全表匹配,匹配成功后作为结果集的一部分返回
在对被驱动表做全表扫描的时候,如果没有Buffer Pool中,则需要进行读取,再对被驱动表做全表扫描的时候,如果没有在Buffer Pool中就等待着部分数据从磁盘读入
从磁盘读入数据到内存,需要时间,而且可能会影响正常的业务Buffer Pool的命中率
join_buffer中由于存储的是数组,所以遍历的成本更低
问题3,distinct和group by性能
对于不需执行聚合函数,只是进行去重的话,使用group by还是distinct呢
可以问题,可以拿两个语句来试验
select a from t group by a order by null;
select distinct a from t;
一般来说,应用group by的场景,都是在select的部分加上一个聚合函数
在没有聚合函数 count(a)的时候,那么两个执行语句的语义是一致的,都是按照字段a来分组,相同的a只返回一行
两个执行顺序为
1.创建一个临时表,临时表有一个字段a,在创建表的时候在字段a上加上唯一索引
2.遍历表t,依次取出数据到临时表上,如果有唯一键冲突,就跳过,不然就插入
3.遍历完成,返回临时表
问题4:备库自增主键是否会冲突
在binlog为statement的时候,语句A获取到了id=1,语句B获取到了id=2,但是语句B先提交了,接着语句A提交了,这样如果写binlog的话,会不会备库上重放binlog时候发生语句B的id为1,语句A的id为2
这个问题之可能出现在statement情况下,因为在row格式下,会记录每一行的每一个字段数据
而且这个问题在statement中也不会,因为在binlog,对于主键id自增的字段,是这样的

在执行语句之前,有一个
set insert_id =1
这个语句的意思,说明,这个线程需要自增值的时候,使用1
于是每次执行的时候,都会先设置一下主键id值,来固定使用
问题5.使用add column after column_name 和 add_column来进行增加字段的时候
两者单纯看性能的话,差别不大
但是并不建议加after column_name;
尽可能的加在最后一行
因为原本有些分支支持快速加列,也就是说加载最后一列的话,瞬间就能完成,而加在column_name的话,就无法使用这些优化
而且使用after column_name是无法用上备库做DDL,切换,再给备库做DDL