我们讲解join查询的时候,说了临时表,那么就简单的说明下临时表的问题
当时为了手动验证使用join语句性能的时候,我们进行了临时表的简单使用
create temporary_table temp_t like t1;
alter table temp_t add index(b);
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
使用了一个关键字 temporary表,内存表和临时表并不是一个概念
内存表中,指的是Memory引擎的表,建表语句就是在后面加上engine=memory
临时表中,使用的引擎并不一定是内存表,其engine不仅可以是InnoDB,也可以是MyISAM
那么临时表有什么特征呢

临时表有几个特征,
1.创建表的时候,语句为为create temporary table
2.一个临时表只能被其创建的session访问,对其他线程并不可见
3.临时表可以和普通表同名
4.一个session中有同名的临时表和普通表的时候,show create语句,会先操作临时表
5.show tables并不显示临时表
由于临时表只能被创建它的session访问,所以适合线程内做一些工作
比如join,毕竟不用担心不同session间重复创建而导致建表失败
不用担心数据删除的问题,在普通表中,如果出现了异常断开或者异常重启,那么临时表会自动回收
临时表的应用
因为不会担心线程之间的冲突,从而临时表经常用在复杂查询的优化过程中,其中,分库分表的系统的跨库查询就是一个典型的使用
其意义在于,有可能,一个大表,因为过大,被拆分到了多个小表上,分布在了不同的数据库实例上
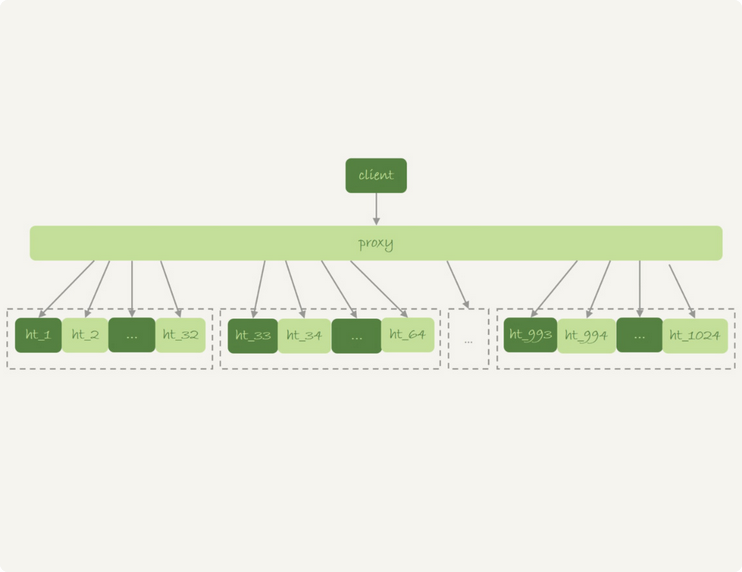
整个客户端和数据库连接之间有一个proxy中间层
在这个架构中,分区key的选择,是尽可能地减少跨库和跨表操作为依据的
然后可以根据这个分区key,尽可能的所有语句都带着这个分区key
这样,当proxy解析完SQL语句的时候,就能确定分到哪个表上做查询了
select v from ht where f=N
但是如果还有别的索引,那么可能操作语句就只能先去查找所有满足条件的行,然后做order by的操作
那么,实现思路有
1.在proxy中实现排序
这种实现好处是处理速度快,可以直接内存中参与计算,但是对中间层的要求高
很容易就出现内存不够用的情况了
2.将各个分库的数据,放在一个Mysql任意实例上的一个表中,然后在这个表上进行操作
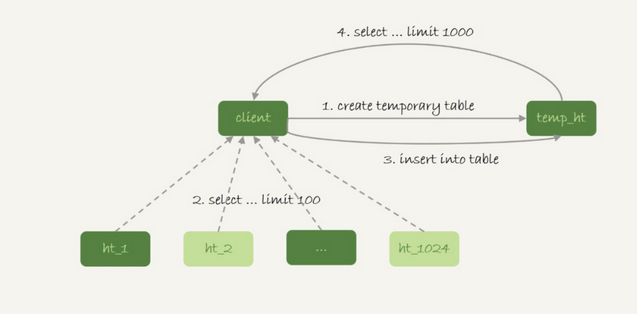
那么上面的操作可以简化为
在汇总的库上创建一个临时表temp_ht,表上包含三个字段 v k t_modified
然后在分库上执行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;
然后将分库执行的结果插入到temp_ht表中,最后执行
select v from temp_ht order by t_modeified desc limit 100;
看完上面的流程,思考一个问题
为什么临时表可以重名,不同的线程可以创建重名的临时表,怎么做到的呢
在执行
create temporary table temp_t(id int primary key)engine=innodb;
的时候,需要给这个InnoDB创建一个frm文件来进行保存表结构的数据,还会找一个地方保存表的数据
表的元数据文件放在了临时文件目录下,后缀是frm,前缀是进程id加上线程id加上id序号
对于表中的数据的存放,在不同MySQL版本中,有不同的处理方式
5.6之前,是在临时文件目录下创建一个相同的前缀,idb为后缀的文件
5.7版本开始,引入了一个临时文件表空间,专门存放临时文件的数据

这个进程的进程号是1234,sessionA的线程id是4,sessionB的线程id是5,于是两个session创建的临时表,不会出现物理空间上的冲突
MySQL在维护表的时候,物理上有文件,内存上也有一套机制区别不同的表,对应的叫做table_def_key
一个普通的表的table_def_key的值是 库名+表名 的形式, 所以,一个库里面不可能存在相同的表
但是临时表,table_def_key 在表名+库名基础上,加上了server_id+thread_id
即使一个客户端里面,thead_id也不一样啊
所以在数据库执行的过程中
每次session内操作表的话,会先去遍历这个table_def_key的链表,然后有的话,就操作临时表,没有的话在操作普通的表
对于这个session关闭的时候,就会对每一个临时表,执行 DROP TEMPORARY TABLE + 表名
但是binlog中也记录了这个DROP TEMPORARY TBALE
这也是因为临时表也要主备复制的原因
| create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/
create temporary table temp_t like t_normal;/*Q2*/ insert into temp_t values(1,1);/*Q3*/ insert into t_normal select * from temp_t;/*Q4*/ |
如果不同步临时表的数据,那么备库会在执行create table t_normal表和
insert into t_normal select * from temp_t
这时候会爆出表temp_t不存在的错误
但是如果设置binlog_format的格式为row的话,那么就不会记录到binlog中,只有在binLog_format为statement/mixed的时候,才会记录临时表的操作
那么就是在binlog_format为mixed或者statement的时候,才会记录临时表的操作
还有一个问题
主备库上的同步是如何做的呢?
主库上不同的线程创建同名的临时表可以的,但是备库上如何执行的呢
这首先说一个要点,在同步binlog的时候
无论create table还是alter table都是原样的,但是drop_table命令,会被改写为
DROP TABLE `t_normal` /* generated by server */
就是直接寻找临时表去进行删除
如果binlog的格式是row的
执行语句
drop table t_normal,t_temp的话
会被重写为DROP TABLE t_normal
这是因为备库上没有t_temp
说完了这个,说一下上面的问题详解
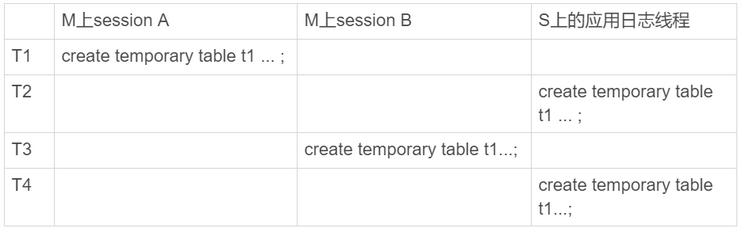
在主库上两个session都创建了临时表,都会传给备库执行
但是备库如何理解的呢,如果分配给了同一个Worker,那么会出现bug
于是MySQL在记录binlog的时候,主库执行这个语句的线程id写到binlog中
这样备库上就能做到主库线程id,并且利用其来构建临时表的table_def_key
那么 sessionA的临时表,在备库上就是库名+t1+M的serverid+sessionA的thread_id
session B的临时表,在备库上就是库名+t1+M的serverid+sessionB的thread_id
今天,主要说了临时表的用法和特性
临时表是一个比较复杂的逻辑,每个临时表示自己线程可见,在现场结束的时候的,也会被自动drop table掉
比较方便