虽然主从复制可以保证其最终一致性,利用了MySQL强大的binlog功能
但是,只有一个最终一致性是不够的,因为读还是在从库上读
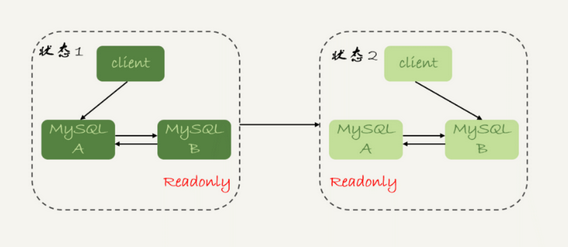
最好保证其强一致性
我们先说导致主备延迟的主要问题
1.同步延迟
主库A执行完成一个事务,写入binlog,这是T1时刻
然后传给了备库B,从库B在T2时刻接受
备库B执行完成后的时刻是T3
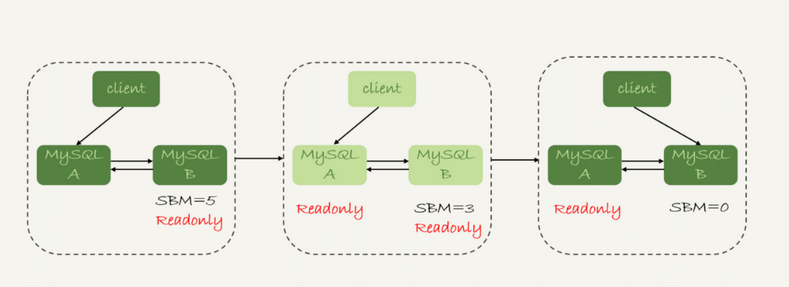
从T3到T1,这就是主备延迟,可以通过在备库上show slave status命令,来返回备库延迟了多少秒
seconds_behind_master,表示延迟了多少秒
这个值具体计算为,每个事务的binlog都有一个时间字段,记录主库上写入的时间
备库上取出正在执行的事务的时间字段的值,计算当前时间的差值,得到seconds_behind_master
备库执行完成的时间戳 – 主库执行完成的时间戳
一般来说,主库传给备库的时间很短的,主要消耗在了中转日志的消费速度上,relay log消费的速度比不上主库生产binlog的速度
主要包含
(1).备库性能差
虽然从库从库不会接收到写请求,可以使用差一点的机器,但是无论什么操作,对于IOPS的压力都是存在的
所以可以考虑设置为非双1模式
所以,在双M模式下,我们会采用多个相同配置IDE极其来进行部署
(2).备库的压力比主库的大
备库上会跑一些压力大的语句,可能会导致备库压力更大,索引,一般来采用中间件来让从库分摊读的压力
(3)大事务
因为主库会在执行完成一个大事务之后,然后将这个大事务整个的传给了备库,于是备库会有一定的延迟,比如
主库的大事务有10分钟,那么从库就可能延迟10分钟
于是删除过多的数据,就可能导致大事务带来的延迟
(4).大表的DDL
对于大表的DDL,也会导致主备延迟
那么如何解决主备延迟来方便我们主从备份呢?
1.可靠性优先的策略
1.对于备库B现在的seconds_behind_master,如果小于一个值,则可以继续切换
2.主库设置为只读状态
3.判断备库上的seconds_behind_master的值,直到这个值变为0
4.备库B改为可读
5.切换到备库上
这个流程的切换过程中,有一个双只读的状态,在此期间,是比较可怕的
因为整个系统无法对任何请求作出相应
2.可用性优先策略
上来就执行4 5步骤开始执行,也就是不等主备数据同步,直接连接到备库B,那么系统就没有不可用的时间了
这就是可用性优先的策略,但是会带来数据不一致的问题
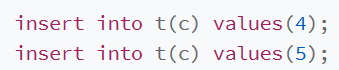
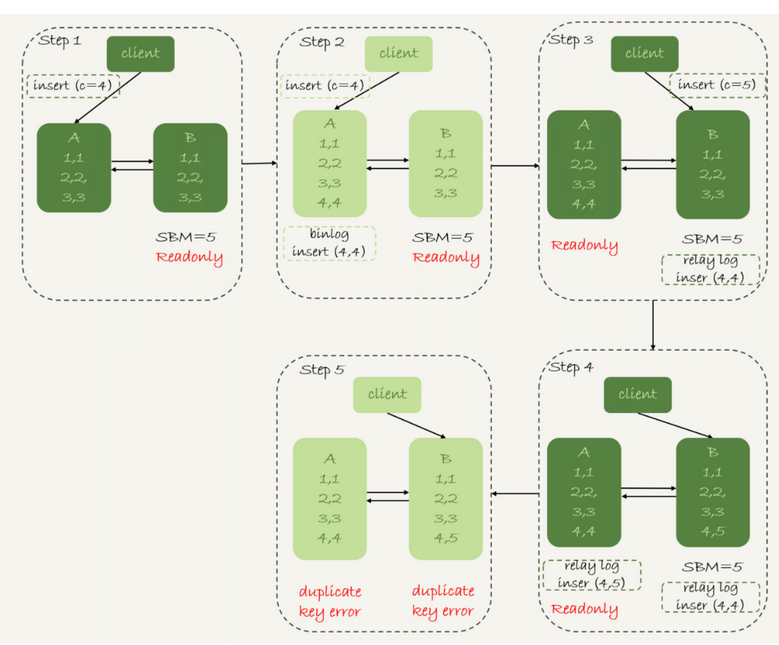
假设有一张表

这个表定义了一个自增主键id,初始化数据后,主库和备库都是3行数据,接下来插入两条语句的命令
接下来在有延迟的情况下,插入一条数据后进行主备切换
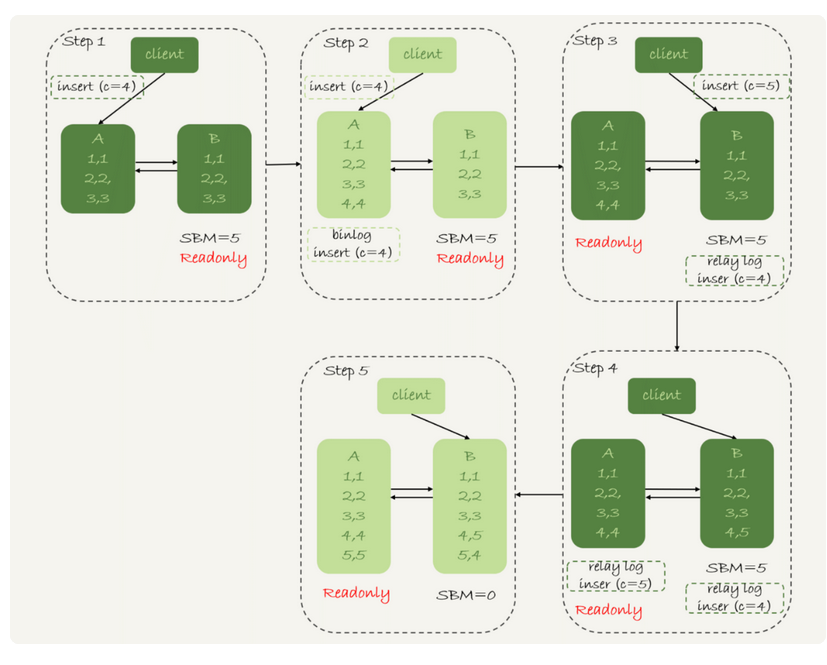
这里,我们使用了mixed来进行切换流程
那么上面的执行流程为
1.步骤2,主库A执行了insert语句,插入了一行数据(4,4),然后进行主备切换
2.主备之间具有五秒延迟,但是直接切换到了备库上
3.这就是备库上被插入了(4,5)
4.接下来收到了中转日志插入一个4,这时候就相当于插入了(5,4)
导致了主备不一致的情况
如果使用binlog为row的格式,那么不会出现的情况
因为row日志会记录新插入的行的所有的字段值,那么在不一致的情况下,会报出duplicate key error的错误
这时候只有一行数据不一致
导致两者冲突,但是row格式更容易让数据
当然会有一些极端情况需要数据的可用性更加优先
比如说日志库,业务系统依赖于日志库写入,必须保证可用性,而且不一致可以通过binlog来补回来
但是可靠性优先的情况,发生了异常
假设,主库A和从库B的主备延迟是30分钟,主库A停电,HA需要切换,在切换的时候,可以等待小于5秒,但是现在不一样了
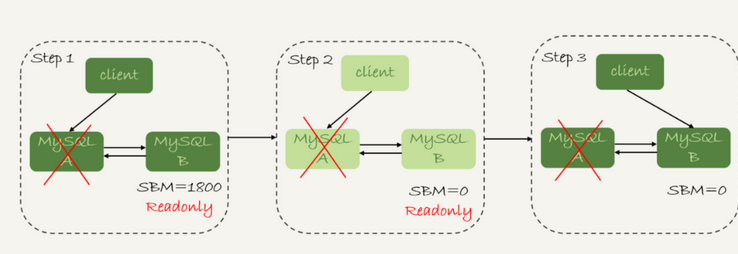
这样直接切换到了备库B,中转日志没有应用完成,客户端连上B,会发现一部分数据丢失,对于一些业务,暂时丢失数据是不能被接受的
导致备库延迟的原因
1.备库执行日志的速度持续低于主库生成日志的速度,那么这个延迟会越来越大,备库永远都没法追上主库的节奏
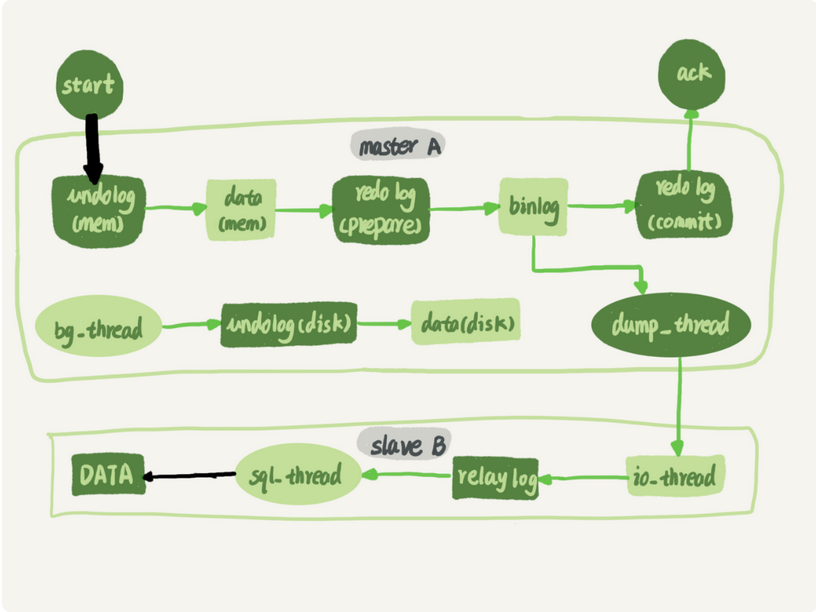
这是上面的主备复制的流程图
这里加上了两条黑色的箭头
一个是写入主库,一个是备库执行中转日志relay log
明显第一个的并行度更高
主库上,MySql上对于数据的更新有优化手段,各种锁,并且支持行锁,对于业务并发是很好支持的
但是在备库应用日志的时候,由于在5.6之前,只支持单线程复制,因此在主库并发高,TPS就会有严重的主备延迟
于是后来官方提供了多线程复制机制,就是将只有一个线程的sql_thread,拆成多个线程
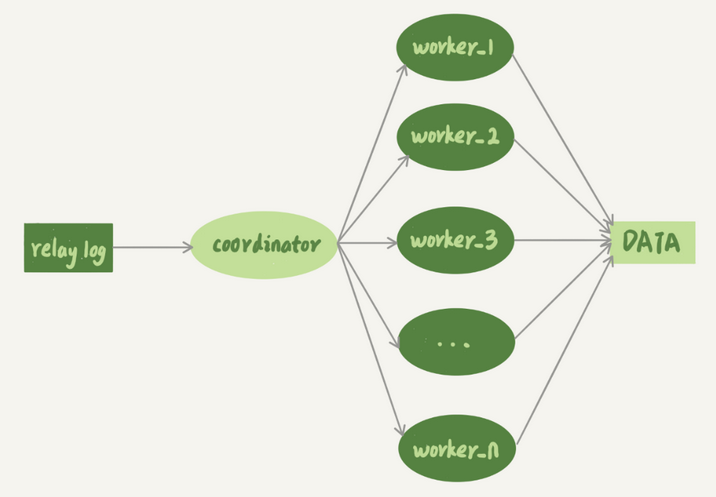
现在这个模型汇总,原本的sql_thread简化为了coordinator,其并不直接更新数据了而只是分发和中转日志,真正更新日志的是多个worker线程,而work的线程个数,由slave_parallel_workers决定的,可以设置为核的四分之一到二分之一之间
但是由于MySql必须保证数据的一致性,所以不能直接轮询的分发,因为如果对于同一行的数据的事务1,2执行顺序颠倒了,可能导致数据不一致
而且同一个事务的多个更新语句,也不能分为不同的worker来执行
所以多线程下执行sql,必须满足两个要求
1.同一事务不能拆开执行
2.更新覆盖,更新同一行的两个事务,必须分发到同一个worker中
于是有了一种思路
按表分发,如果两个事务更新不同的表,那么可以并行分发
如果是一个事务是跨表的,那么还是要放在一起考虑的
按表分发的策略
如果两个事务更新不同的表,就可以并行,保证worker之间不会更新同一个行
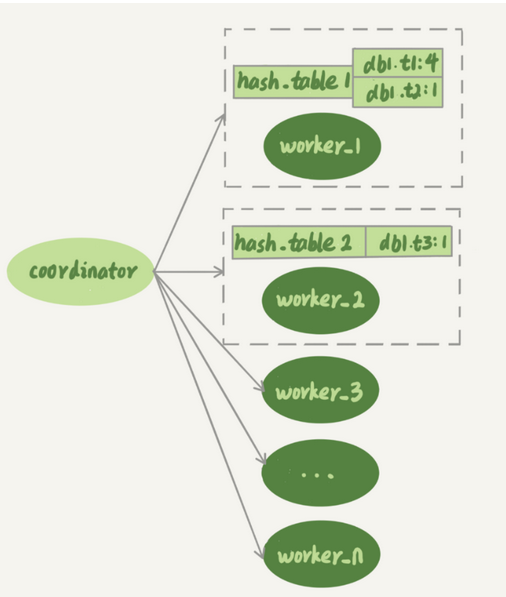
每个worker对应一个hash表,表的key是库名表名 value是一个数字
表示队列中有多少个事务涉及修改这个表
有事务分配到这个worker上,涉及的表就会加到对应的hash表中,worker完成后,这个表会从hash表中去掉
图中的图表示hash_table_1 表示,现在 worker_1 的“待执行事务队列”里,有 4 个事务涉及到 db1.t1 表,有 1 个事务涉及到 db2.t2 表;hash_table_2 表示,现在 worker_2 中有一个事务会更新到表 t3 的数据。
假设现在有一个新的事务T,修改的行涉及到表 t1 和 t3
整体的分配就是
由于涉及到修改表t1,那么worker_1队列在事物修改标题时候,事务T和队列1中某个事务发生冲突
然后遍历发现worker2也冲突
然后就进入等待
如果worker2已经不冲突,只和worker1有冲突了,那么就会分配给worker1
总结下来说
如果和所有worker都不冲突,分配给最闲的
如果和多于一个worker冲突,那么会进入等待,直到只剩一个冲突
如果只和一个冲突,会分配给这个存在冲突的worker
这个表对于某个表的热点特别大的时候,就不好办了
按行分配的策略
按照行级锁的原则,只要不是同一行,就不会出出现冲突,但是binlog的格式必须是row
在按表分配的基础之上,把hash表的key改为了库名+表名+唯一键的值
但是如果还会出现唯一索引的冲突问题,然后可能导致主键索引在备库更新时候出现了冲突
于是事务中还是会出现库名 表名 主键 唯一键
于是按行分发的策略会消耗更多的计算资源
而且会要求这个表的binlog格式必须是row,而且具有主键
最重要的是不能有外键
在使用了按行分配的情况下
会很消耗内存,比如一个语句要删除100万行数据,就需要记录100万行
消耗CPU,解析binlog,计算hash值
所以并不能单独使用
MySql5.6版本的并行复制
在MySql5.6版本中,支持了按照库来并行,如果一个MySql有多个DB,并且多个DB压力均衡
而且支持任何binlog
但是如果所有的表都在一个库里就不能行了,可以创建不同的DB,将相同热度的表均已分配到不同DB中,才能使用这个策略
MariaDB的并行复制
利用了redo log的group commit优化,而MariaDB的并行复制策略就是利用了这个特性
能够在同一组提交的事务,不会修改同一行
所以利用这个特性,进行一组的复制
一组里一起提交的事务,有一个相同的commit_id,下一组就是commit_id+1
commit_id直接写到binlog里面
穿到备库应用,相同commit_id的事务分发到过个worker执行
执行之后去取下一批
但是备库上的并发执行和主库还是有一定的距离的
主库上可以
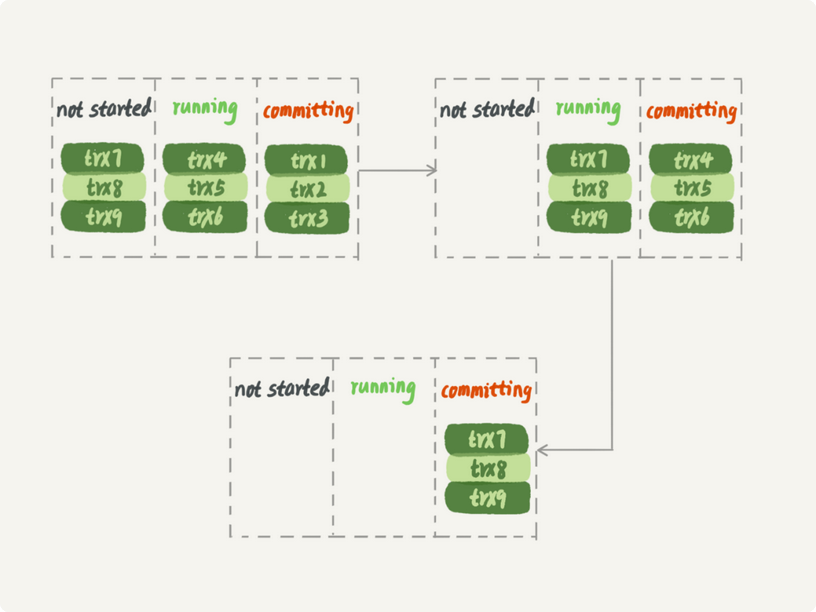
从库上只可以
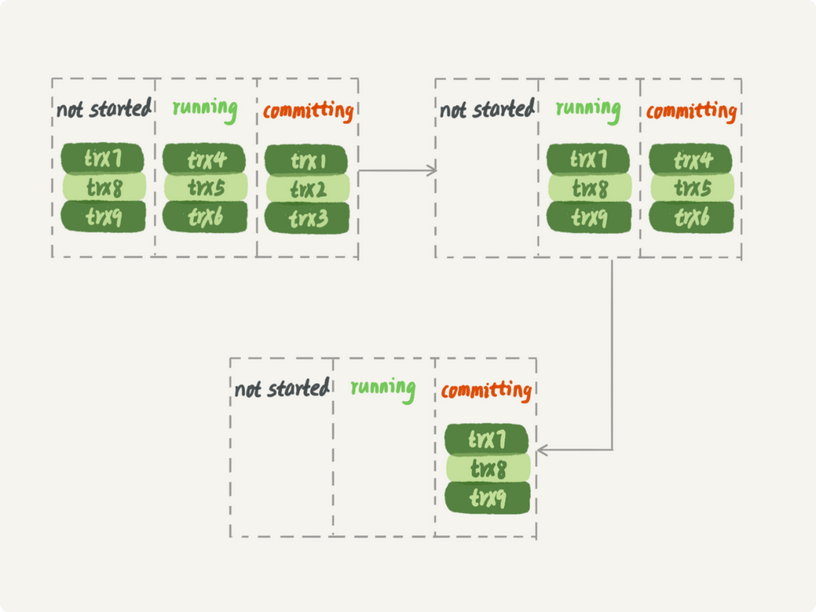
可以看出,要等第一组的事务执行完成后,第二组事务才能开始执行,不过仍然是一个很漂亮的创新
后来MySql5.7也提供了commit_id复制
可以设置slave-parallel-type来控制并行复制策略
1.配置为DATABASE,表示使用MySQL5.6版本的按库并行
2.LGICAL_CLOCK,按照类型MariaDB策略,不过MySQL5.7这个策略,针对并行进行了优化
MariaDB是策略核心是所有commit的事务已经不会发生冲突

但是可以在redolog commit之前就进行动手脚呢,也就是redo log prepare阶段
只要能够到达 redo log prepare 阶段,就表示事务已经通过锁冲突的检验了。
于是在处于perpare状态的事务,和处于commit状态的事务,在备库执行的时候,是可以并行的
后来又提供了binlog-transaction-dependency-tracking参数,可选值有以下三种
1.Commit_ORDER 即为上面的进入prepare可以并行的策略
2.WRITESET,对于事务设计的每一行进行计算hash值,这个 hash 值是通过“库名 + 表名 + 索引名 + 值”计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert 语句对应的 writeset 就要多增加一个 hash 值。
组成集合 writeset。如果两个事务没有操作相同的行,也就是说它们的 writeset 没有交集,就可以并行。
3.WRITESET_SESSION 在上面的基础上,保证了主库上同一线程执行的两个事务,备库上也要保证先后顺序