在JDK 6u14后,就有G1的出现,在现在JDK9以后,已经成熟并且正式作为JDK的默认收集器而使用了
其特点在于:
1.并行和并发,G1能充分的利用CPU:多核下的硬件,利用多核CPU来减少Stop The World
此处的并发并行指的是
并行(Parallel):是指多条垃圾收集线程并行工作,用户线程仍然处于等待状态
并发(Concurrent):用户线程和垃圾收集线程同时执行,用户线程继续运行,垃圾收集程序运行于不同的Cpu
G1收集器在GC的过程中也是通过并发的方式让Java程序继续执行
2.分代回收:和其他收集器一样,分代回收的概念仍然被G1保留的了下来,虽然G1不用其他收集器配合自己来进行回收,但仍然采用不同的方式去处理新创建的对象和旧对象
3.空间整合,G1采用的是标记-整理算法实现的收集器,其不会产生内存空间碎片,有利于长期运行
4.可以预测的停顿,其做到了可以在指定长度的M毫秒时间内,进行垃圾收集
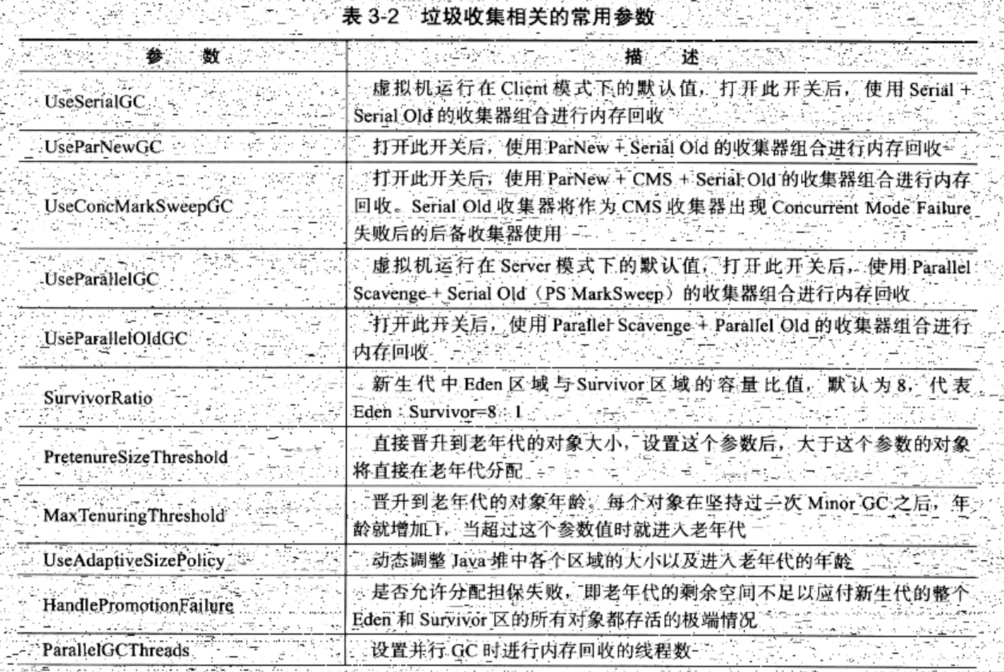
G1最大的区别就是不再将整个堆空间分为了老年代和新生代,而是将整个堆分为了大小相等的独立区域,虽然保留了老年代和新生代的概念,但是不再是将两者物理隔离了,都是一部分Region的集合
region 的大小是一致的,数值是在 1M 到 32M 字节之间的一个 2 的幂值数,JVM 会尽量划分 2048 个左右、同等大小的 region
在 G1 实现中,年代是个逻辑概念,具体体现在,一部分 region 是作为 Eden,一部分作为 Survivor,除了意料之中的 Old region,G1 会将超过 region 50% 大小的对象(在应用中,通常是 byte 或 char 数组)归类为 Humongous 对象,并放置在相应的 region 中。逻辑上,Humongous region 算是老年代的一部分,因为复制这样的大对象是很昂贵的操作,并不适合新生代 GC 的复制算法。
对于region大小的调整,可以使用如下的参数
-XX:G1HeapRegionSize=<N, 例如16>M
在新生代,G1 采用的仍然是并行的复制算法,所以同样会发生 Stop-The-World 的暂停。在老年代,大部分情况下都是并发标记,而整理(Compact)则是和新生代 GC 时捎带进行,并且不是整体性的整理,而是增量进行的。
对于 G1 来说:
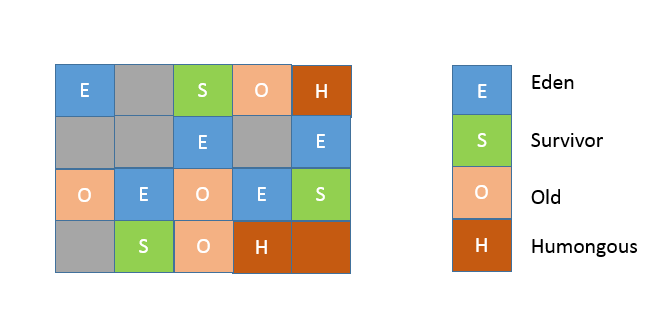
Minor GC 仍然存在,虽然具体过程会有区别,会涉及 Remembered Set 等相关处理。老年代回收,则是依靠 Mixed GC。
并发标记结束后,JVM 就有足够的信息进行垃圾收集,Mixed GC 不仅同时会清理 Eden、Survivor 区域,而且还会清理部分 Old 区域。可以通过设置下面的参数,指定触发阈值,并且设定最多被包含在一次 Mixed GC 中的 region 比例。
–XX:G1MixedGCLiveThresholdPercent
–XX:G1OldCSetRegionThresholdPercent
整体的运行过程如下
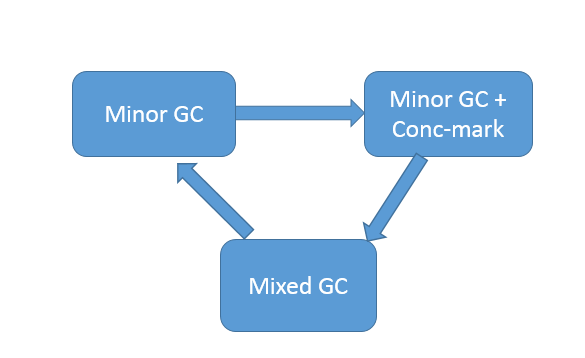
然后就是 Remembered Set
用于记录和维护 region 之间对象的引用关系。为什么需要这么做呢?试想,新生代 GC 是复制算法,也就是说,类似对象从 Eden 或者 Survivor 到 to 区域的“移动”,其实是“复制”,本质上是一个新的对象。在这个过程中,需要必须保证老年代到新生代的跨区引用仍然有效。下面的示意图说明了相关设计。
在流程基本还是
初始标记
并发标记
最终标记
筛选回收
的框架之上
还有一些关于G1的独特行为变化
关于Humongous,作为老年代的一部分,通常认为它会在并发标记结束后才进行回收,但是在新版 G1 中,Humongous 对象回收采取了更加激进的策略。
Humongous 对象数量有限,所以能够快速的知道是否有老年代对象引用它,可以维护一个是否有老年代引用的标识位,那么在 Young GC 时就可以知道,是否可以回收
那么总结一下收集器
CMS GC伴随着时代的发展,已经被废弃了
在GC的发展中,还出现了一些特殊的GC方式
Epsilson GC,不进行垃圾收集的GC,专注于性能测试
ZGC,Oracle 开源出来的一个超级GC的实现,惊讶的扩展能力,支持T bytes级别的堆大小,延迟不超过10ms,现只支持Linux 64位平台