我们理解了上面说的CAP定理,Raft算法等,只是理解了理论知识,在理论和实践之间是存着一定的鸿沟的,比如,提到编程语法或者分布式算法的论文,可能很多,但是实际书写的时候,可能就卡壳了
我们拿着不同的理论和算法,来看看具体如何在实践中实现的呢?我们首先拿着InfluxDB企业版来书写如何实现,
为何第一个显示InfluxDB呢,因为其是排名第一的时序性数据库,相比其他分布式系统,时序数据库比较复杂,我们需要分别设计两个不一样的一致性模型
对于InfluxDB,我们需要知道的是时序数据是按照时间顺序去记录系统,状态变化的数据,比如CPU的利用率,某一时间的环境温度,存储起来如下所示
| > insert cpu_usage,host=server01,location=cn-sz user=23.0,system=57.0
> select * from cpu_usage name: cpu_usage time host location system user —- —- ——– —— —- 1557834774258860710 server01 cn-sz 55 25 > |
时序性最大的特点就是数据量大,可以说是海量,监控整体来说,埋点是越多越好,能够及时发现问题复盘故障
那么,InfluxDB企业版的架构是如何的呢?
这是是由META和DATA节点2个逻辑单元组成的,而且这两个节点是2个单独的程序
两个节点是两个单独的程序,那么为何不能合到一个程序的呢?
META节点存放的是系统运行的关键元数据,比如数据库,表,保留策略,特点是一致性敏感,读写访问量不高,需要一定容错能力
DATA节点存放的是具体的时序数据,具有最终一致性,面向业务,性能越高越好,除了容错,还需要实现水平扩展,扩展集群的读写性能
对于META节点,节点数的多少代表着容错能力,一般3个节点就够了,能够容忍一个节点的故障就可以了
对于DATA节点来说,节点数的多少则代表了读写性能,一般而言,一定数量内,越多越好,节点数多,读写性能越高,节点数太多越不行,可能会出现查询效率低下
所以基于不同场景的特点,设计了2个单独程序,如果META和DATA节点合并为一个程序,因为读写的性能需要,设计了一个10节点的DATA节点集群,意味着META节点集群也是10节点,那么在Raft之中,消息就会变得很多,日志提交变慢了
我们就分别对两个节点特性设计两个不同的程序来保证
META:
因为存放的是系统运行的关键元信息,那么写操作发生后,就需要读到最新的数据,比如,创建了数据库telegraf,有的DATA读取不到这个数据库,就会导致相关的时序数据的写入失败了
所以我们需要实现强一致性,CAP中的CP模型
在InfluxDB的官方文档上,我们知道了其是通过Raft算法实现了META节点的一致性
DATA:
DATA存放的是具体的时序数据,对一致性要求不高,实现最终的一致性就可以了,但是DATA节点也同时作为接入层直接面向业务,考虑时序数据的量很大,要实现水平扩展,必须使用AP模型,因为AP模型不像是CP模式那样,一个算法就能实现了,所以,AP模型更加的复杂
首先,ap模型为了可以高可用,就需要设置自定义副本数的功能,当部分的节点出现问题的时候,系统仍然可以读写数据,正常运行
自定义副本数
可以在一个节点上定义多个副本数,从而更加的灵活,当集群支持多副本的时候,必然会出现一个节点写远程节点时候,RPC通讯失败,怎么处理这个问题呢?
Hinted-handoff
一个节点接收写请求,然后将写请求中数据转发给其他的副本的所在的节点,在这个过程中,远程RPC通讯可能会失败的
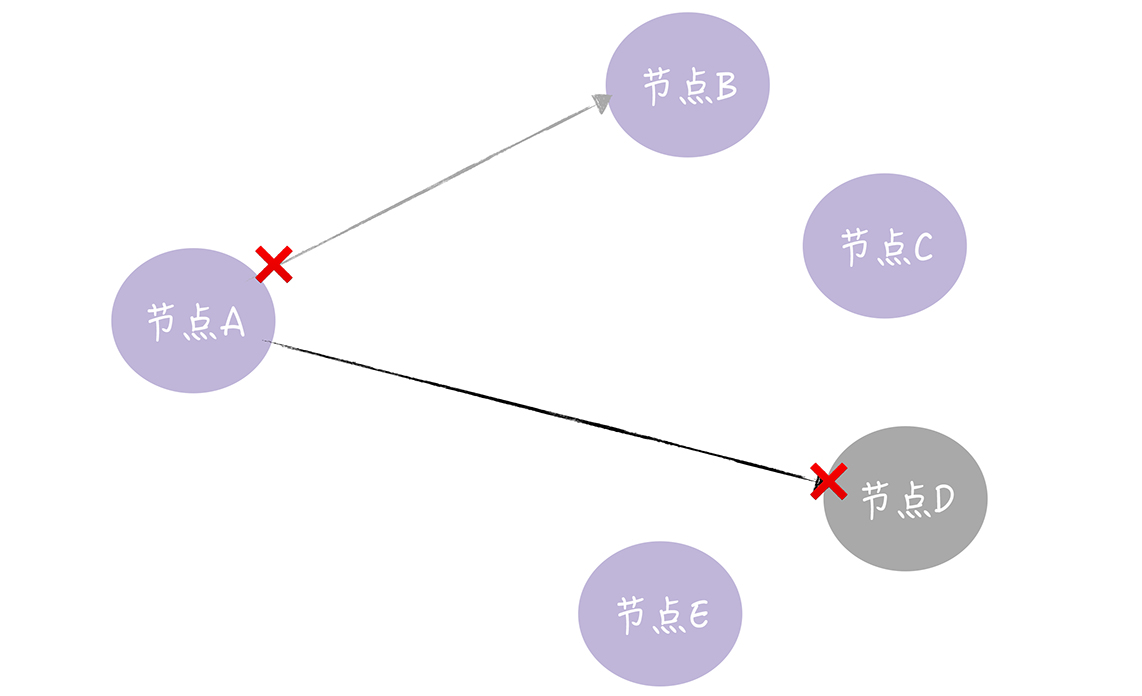
实现了Hinted-handoff,在InfluxDB企业版中,会做如下的处理
将写入失败的请求,缓存到本地磁盘上
周期性的尝试重传
配置了相关参数,然后就可以自定义这个重传方式
而且,在突发流量很多的时候,可能出现RPC的通讯失败,需要Hinted-handoff
虽然可以通过重传来处理数据不一致的问题,但是本地缓存是有上限的,可能导致长期故障,将请求的数据直接丢失了,最终的节点数据不一致的,如果实现数据的最终一致性呢?
利用反熵机制
时序数据虽然一致性不敏感,能容忍短暂的不一致性,但是查询的数据长期不一致,就必然不可行,
那么就需要实现反熵,来进行修复数据的不一致,时序数据就好比日志数据一样,创建了之后就不会修改了
所以数据副本之间的不一致,是因为数据写失败了,而在其中,存在都是合理的,缺失的则是需要修复的,所以直接对比并修复即可
NWR思想,
由于在公司官网上的仪表盘,是不能有仪表不一致的情况的,无法容忍试图不一致的,就需要可以实现强一致性的,每次读取尽可能的读取到新的数据,而不是老数据
对于NWR,同样,我们已经学过了
实现一个AP类型的系统,比实现CP的系统更加难以实现,所以我们需要深入研究场景特点,实现符合自己的分布式西永
本章中,我们主要对时序性数据库,META节点的一致性的实现,DATA节点的一致性进行了实现,以一个复杂的实际系统为例,将理论串起来,知道如何在实际场景中使用
CAP理论贯彻了全文,这个理论是一个尺子,能够帮助我们分析问题,总结归纳问题,如何妥协折中
通过Raft,可以实现强一致性的分布式系统,保证操作完成后,后续所有的读操作,读到最新的数据
通过自定义副本数,Hinted-handoff,反熵,Quorum NWR,我们来实现一个AP型的分布式系统
假设有一个场景,写请求不多,但是读请求很多,那么如何设计这个系统呢?
读多写少啊,只需要保证在每次都必须要写入到每一个节点上就可以了,然后读的时候直接去读,自然是最新的