网络数据的基本单位是字节
Java NIO的字节容器就是ByteBuffer
而Netty利用ByteBuf代替了ByteBuffer
ByteBuf的优点在于
可以被用户自定义的缓冲区扩展
内置复合缓冲区实现了透明了零拷贝
容量可以按需增长
读和写的两种模式的切换不需要调用ByteBuffer的flip方法
读和写使用了不同的索引
支持方法的链式调用
支持引用计数
支持池化
内部的数据结构如下

一个数组两个索引,数组的大小可以指定,当超过指定的最大值时候会触发一个异常
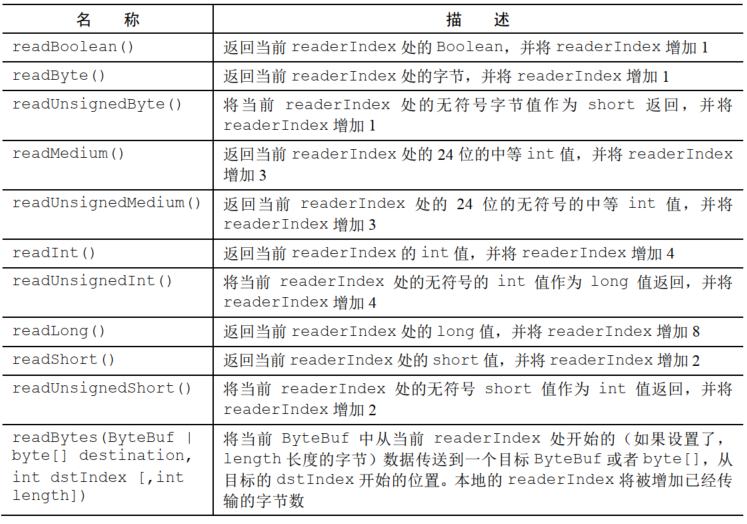
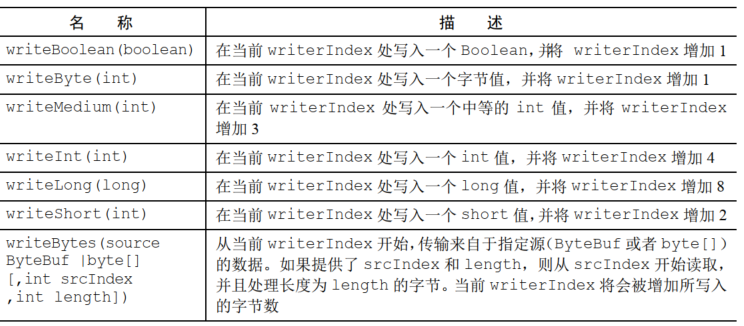
从ByteBuf读取的时候,readerIndex会递增已经读取的字节数
写入ByteBuf的时候,writerIndex会递增
read和write会推进其对应的索引
set和get则不会,会作为一个参数传入一个相对索引上执行操作
常见的NettyBuf的使用模式有
1.堆缓冲区
常用ByteBuf模式将数据存储在JVM的堆空间中,这种模式称为支撑数组,支持快速的读取和释放,代码使用如下 
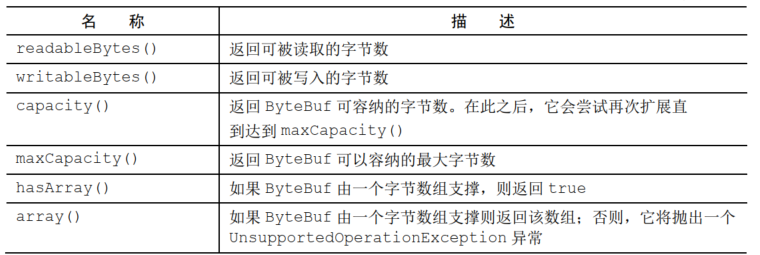
如果hasArray返回false还尝试访问支撑数组的话,则会触发一个UnsupportedOperationException
2.直接缓冲区
因为往往涉及网络交互的内存是放置在堆空间外部的,这就导致我们需要读取对应的交互内存的时候,需要将其调用到本地IO 操作之前 将缓冲区的内容复制到一个中间缓冲区,为了避免这个复制,我们就使用了直接缓冲区的代码,其缺点在于,相对于基于堆的缓冲区,释放比较昂贵,而且在访问的时候,因为数据不再堆上,所以不得不进行一次复制.
使用的代码如下

3.复合缓冲区
多个ByteBuf提供一个聚合的视图
我们可以合并多个缓冲区
比如,我们有一个消息,由两个部分组成 头部 和 主体 常见的就是HTTP请求
对于这个情况,我们可以使用CompositeByteBuf,我们暴露了通用的ByteBuf,消除了没用的赋值
如果不适用复合缓冲区

如果使用CompositeByteBuf

访问内部缓冲区的代码如下

字节级操作
我们需要说的是ByteBuf的基础读写操作
如同在普通的Java字节数组中,ByteBuf索引从零开始,到capacity() -1
访问如下

顺序访问索引
JDK的ByteBuffer只有一个索引,flip()方法可以在读模式和写模式之间进行切换
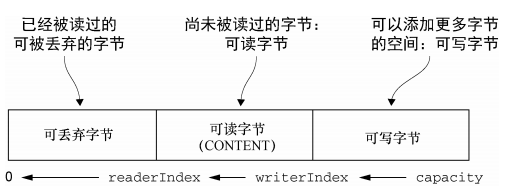
可丢弃字节
可丢弃的字节包含了已经读过的字节,通过discardReadByte()方法,丢弃他们回收空间,分段的初始值为0,存储在readerIndex中,随着read操作的执行而增加
执行了discardReadByte() 方法的结果,会导致可以丢弃字节部分的空间变为可写的了
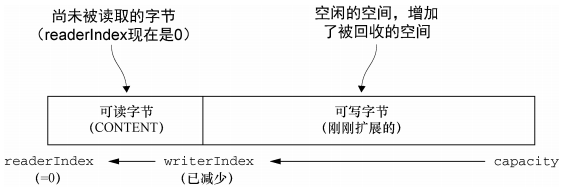
但是频繁调用,极有可能导致频繁的内存赋值,所以不建议频繁的调用
可读字节
ByteBuf的可读字节分段存储了实际的数据,新分配的,包装的复制的缓冲区的默认的readerIndex值为0,以read skip开头的操作会导致readerIndex增大
如果可读字节数已经耗尽的时候从中读取数据,将会引发一个IndexOutOfBoundsException


可写字节
拥有未定义的,可以写入的内存区域,新分配的缓冲区的writerIndex默认值是0,任何write开头的操作都会开始写数据,压榨已经写入的字节数
如果尝试写入超过目标容量的数据,会引发IndexOutOfBoundException
索引管理
JDK的InputStream可以重置索引,分别是mark和reset
可以将流的当前位置标记为指定的值,以及流重置到该位置
ByteBuf可以通过markReaderIndex(),markWriterIndex(),resetReaderIndex(),resetWriterIndex()
也可以调用 readIndex(int) writerIndex(int)将索引移动到指定位置
如果移动越界,会导致IndexOutOfBoundException
也可以调用clear()方法来将readerIndex()和writerIndex()都设为0,但并不会清楚内存中的内容
查找操作
ByteBuf中确定指定值位置的方法中,简单的就是IndexOf(),比较复杂的是通过一个ByteBufProcessor作为参数的方法达成
boolean process (byte value)
检查输入值是否是要查找的
需要ByteBufProcessor的方法,集成了不少简单遍历的方法

比如查找一个Null
forEachByte(ByteBufProcessor.FIND_NUL)

派生缓冲区
方便你创建一个额外的ByteBuf来读取内容
可用的方法有
duplicate()
slice()
order(ByteOrder)
Unpooled.unmodifiableBuffer(…)
readSlice()
这都会返回一个新的ByteBuf实例,有自己的读写索引
如果需要没有任何引用关系,请使用copy()方法
读写操作
有两种读/写操作
get() set() 不会影响到索引
read() 和 write() 从给定的索引开始,进行修改
常见的API如下
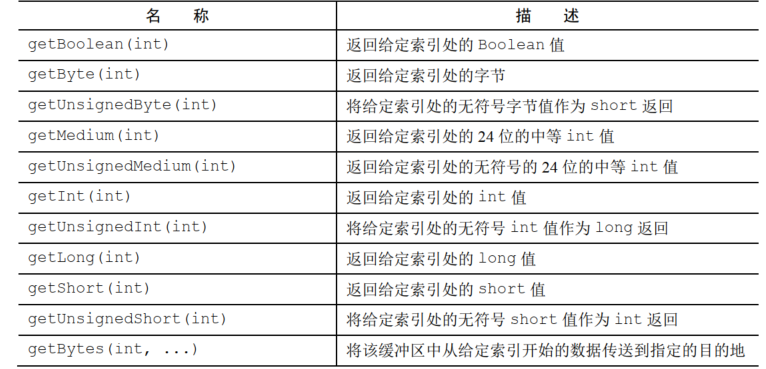
对应set也是如下API
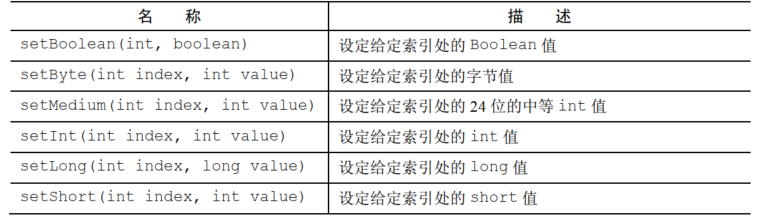
read和write的API类似
还有些特殊的API

ByteBufHolder相关接口
ByteBufHolder有几种访问底层数据和引用计数的方法

ByteBuf的分配
Netty利用ByteBufAllocator实现了ByteBuf的池化
那么ByteBufAllocator的API如下这些
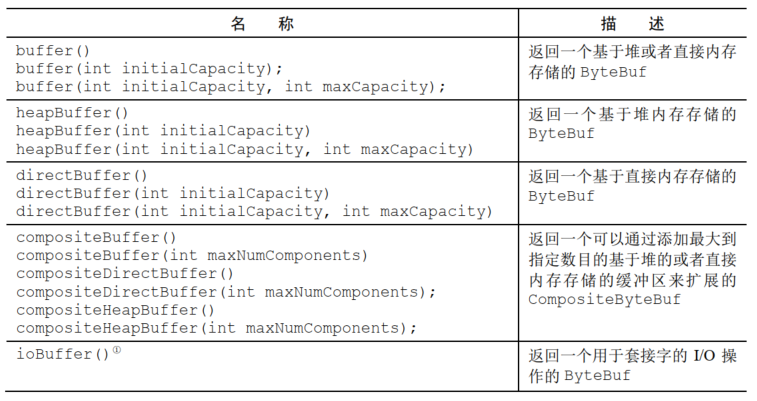
对于这个ByteBufAllocator的获取方式,可以通过ChannelHandlerContext 获取一个ByteBufAllocator的引用

Netty提供了两个ByteBufAllocator的实现,PooledByteBufAllocator和UnpooledByteBufAllocator
前者利用jemalloc来分配内存,后者不进行池化,直接返回新实例
Netty默认使用PooledByteBufAllocator
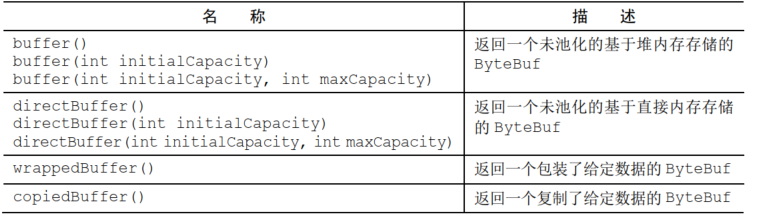
Unpooled 静态方法创建ByteBuf
简单的工具类
ByteBufUtil类
提供了用于操作ByteBuf的静态类
最有价值的方法就是hexdump() 十六进制的方式打印ByteBuf的内容
引用计数
确保对象是否可以被引用计数
Netty实现了这个技术,即接口 ReferenceCounted
引用计数对于池化实现是必要的,降低了内存分配的开销
引用计数的想法不难,我们只要保证引用计数大于0,就能保证对象不会被释放
其中的refCnt() 接口获取引用计数
至于释放,直接调用
release()
如果试图访问一个已经被释放的对象,会导致IllegalReferenceCountException