LlamaIndex集成A2A助手
我们通过LlamaIndex来构建文档解析以及聊天Agent
和LangChain 一样,LlamaIndex也是一开始就流行的大模型开发框架之一。其更加专注于进行文档检索和搜索相关的大模型应用构建。
这里我们首先构建一个LlamaIndex的使用小Demo来看下
首先是根据本地文件夹,读取并利用LlamaIndex中的VectorStoreIndex来进行索引生成。
|
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader(“../data”).load_data() len(documents) from llama_index.core import VectorStoreIndex index = VectorStoreIndex.from_documents(documents) vars(index) |
在这个index之中,主要由三部分组成,分别为文档存储SimpleDocumentStore。 索引存储SimpleIndexStore。 向量存储SimpleVectorStore。
其中文档存储中保存了读取的文档,以Node为对象表示,节点是对原始文档进行分块处理的结果,包含文本内容和相关元数据信息。
索引存储,则是包含轻量级的索引元数据,构建索引时候进行创建的附加状态信息。存储索引结构和相关元数据信息。
向量存储,一种内存中的存储系统,以字典的形式保存嵌入,将节点ID映射到相关的嵌入中。进行高效的检索和搜索。
在整个索引中,llama_index会自动将读入的文档切分为一个个的节点,然后进行节点关联。
之后我们可以通过storage_context进行索引的保存,并查看索引文件的机构。
index.storage_context.persist(persist_dir=”saved_index”) # 保存索引
在保存的目录下,包含多个JSON文件,用于存储和相关数据
default_vector_store.json 保存默认的向量存储配置或数据。诸如用户的上传文本的向量化表示。
docstore.json 保存文档存储的元数据或者实际内容,例如文档的原始内容
graph_store.json 保存知识图谱或者关系图的数据,记录文档和向量之间的关系,往往在基于节点推理的时候用到。
image_vector_store.json:保存与图像相关的向量数据。如果系统支持多模态检索(如文本和图像混合检索),这个文件可能保存了图像嵌入(向量化表示)的数据。通过这个文件,系统可以进行基于图像内容的相似性搜索。
index_store.json 保存索引本身的结构或者云信息,存储所有已经创建索引的元数据。比如每个索引的对应文档范围,嵌入模型,参数配置等。
这里我们针对docstore.json中的数据结构信息进行展开,查看其中存储的具体内容,如图所示
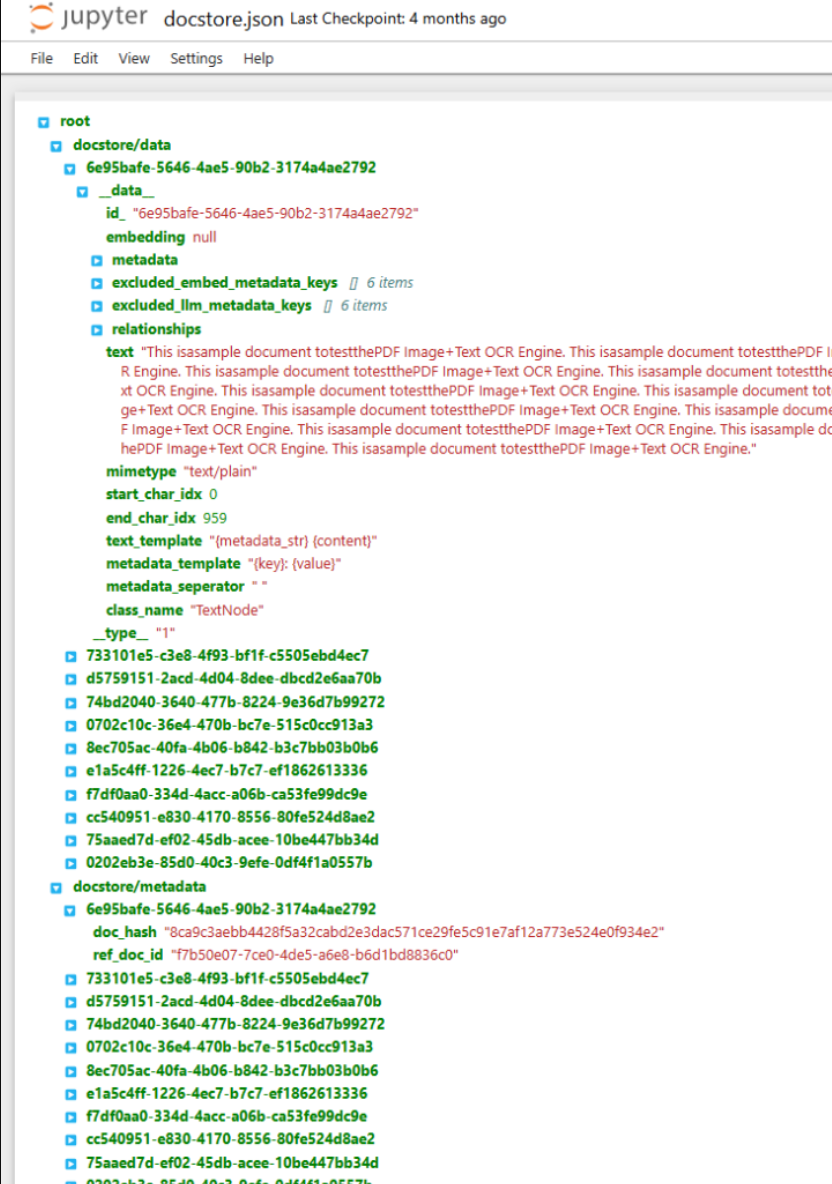
其中一方面存储了文本内容,另一方面存储了诸如relationships这样的节点之间的关系。
default_vector_store.json中还存储了一个个的文本块嵌入向量。
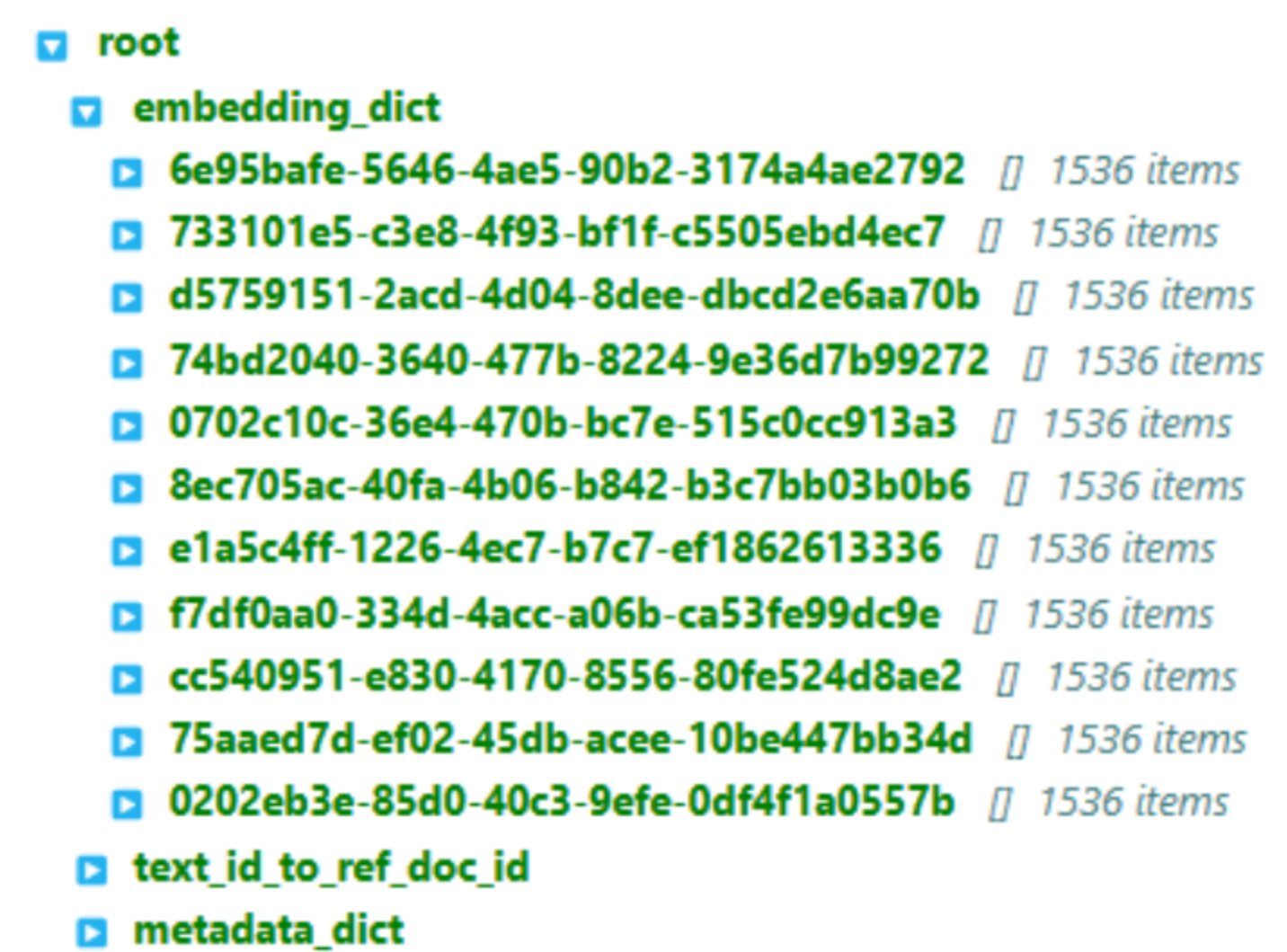
每一个均为1536维的OpenAI的嵌入向量。
这样,回来在用户输入的时候,也会讲文本输入拆分为token,然后将token统一起来计算为一个向量。
那么在LlamaIndex构建完成文档库向量索引之后,就可以进一步引入LlamaIndex的Agent和Workflow。最后实现文档加载,多轮问答这样的聊天Agent。
如果是传统LlamaIndex,一般是一问一答,而如果通过llama workflow 提供的workflow机制,则可以将多个步骤封装为事件驱动的状态流程。并进一步形成一个Agent。
那么我们看下这个Agent相关的代码
首先是route函数
|
@step
def route(self, ev: InputEvent) -> LoadDocumentEvent | ChatEvent: “””路由步骤:判断是加载文档还是聊天””” if ev.file_path or ev.base64_content: return LoadDocumentEvent( file_path=ev.file_path, file_name=ev.file_name, base64_content=ev.base64_content, msg=ev.msg ) return ChatEvent(msg=ev.msg) |
上面的step装饰器,标志着工作流的一个执行步骤,route根据是不是文件,来决定执行聊天还是上传文件。
其次是加载文档对象
|
@step
async def load_document(self, ctx: Context, ev: LoadDocumentEvent) -> ChatEvent: “””文档加载步骤””” try: if ev.file_path: ctx.write_event_to_stream(LogEvent(msg=f”正在加载文档: {ev.file_path}”)) # 读取文件内容 with open(ev.file_path, ‘r’, encoding=’utf-8′) as f: content = f.read() file_name = ev.file_name or ev.file_path elif ev.base64_content: ctx.write_event_to_stream(LogEvent(msg=f”正在解析base64文档: {ev.file_name}”)) # 解码base64内容 content = base64.b64decode(ev.base64_content).decode(‘utf-8’) file_name = ev.file_name else: raise ValueError(“必须提供文件路径或base64内容”) # 创建文档对象 doc = Document( text=content, metadata={“file_name”: file_name} ) # 添加到文档列表 self.documents.append(doc) # 重新构建索引 await self._build_index(ctx) ctx.write_event_to_stream(LogEvent(msg=f”✅ 文档加载成功: {file_name}”)) except Exception as e: ctx.write_event_to_stream(LogEvent(msg=f”❌ 文档加载失败: {str(e)}”)) return ChatEvent(msg=ev.msg) |
|
@step
async def chat(self, ctx: Context, ev: ChatEvent) -> ChatResponseEvent: “””聊天步骤””” try: # 添加用户消息到历史 self.chat_history.append({“role”: “user”, “content”: ev.msg}) if not self.index: response_content = “抱歉,还没有加载任何文档。请先加载一个文档。” self.chat_history.append({“role”: “assistant”, “content”: response_content}) return ChatResponseEvent( response=response_content, citations={}, has_documents=False ) # 创建查询引擎 query_engine = self.index.as_query_engine( similarity_top_k=3, response_mode=”compact” ) # 执行查询 ctx.write_event_to_stream(LogEvent(msg=”正在查询文档…”)) response = query_engine.query(ev.msg) # 提取引用信息 citations = {} if hasattr(response, ‘source_nodes’) and response.source_nodes: for i, node in enumerate(response.source_nodes, 1): citations[i] = { “content”: node.text[:200] + “…” if len(node.text) > 200 else node.text, “metadata”: node.metadata } response_content = str(response) # 添加助手回复到历史 self.chat_history.append({“role”: “assistant”, “content”: response_content}) return ChatResponseEvent( response=response_content, citations=citations, has_documents=True ) except Exception as e: error_msg = f”查询过程中出现错误: {str(e)}” self.chat_history.append({“role”: “assistant”, “content”: error_msg}) return ChatResponseEvent( response=error_msg, citations={}, has_documents=bool(self.index) ) |
在chat过程中,调用了as_query_engine() 方法,将索引转型为一个可用于问答的查询引擎。
基于这个Agent,我们可以非常容易得将其嵌入到A2A架构中,每次上传文件,触发load_document流程。
那么在A2A实现过程中,我们进一步将其封装为可部署可调度的智能体Agent,接入A2A协议架构,实现一个支持多轮问答,引用追溯,流式相应的工作流程。
Agent架构以Workflow类为基础进行构建,使用LlamaIndex的step装饰器将各个处理阶段模块化。
首先是init相关代码
|
class ParseAndChat(Workflow):
def __init__( self, timeout: float | None = None, verbose: bool = False, **workflow_kwargs: Any, ): super().__init__(timeout=timeout, verbose=verbose, **workflow_kwargs) self._sllm = GoogleGenAI( model=’gemini-2.0-flash’, api_key=os.getenv(‘GOOGLE_API_KEY’) ).as_structured_llm(ChatResponse) self._parser = LlamaParse(api_key=os.getenv(‘LLAMA_CLOUD_API_KEY’)) self._system_prompt_template = “””\ 你是一个有用的助手,可以回答关于文档的问题,提供引用,并进行对话。 这是带有行号的文档: <document_text> {document_text} </document_text> 当引用文档内容时: 1. 你的内联引用应该从[1]开始,每个额外的内联引用递增1 2. 每个引用编号应该对应文档中的特定行 3. 如果一个内联引用覆盖多个连续行,请尽量优先使用单个内联引用来覆盖所需的行号 4. 如果一个引用需要覆盖多个不连续的行,可以使用[2, 3, 4]这样的引用格式 5. 例如,如果响应包含”The transformer architecture… [1].”和”Attention mechanisms… [2].”,这些分别来自第10-12行和第45-46行,那么:citations = [[10, 11, 12], [45, 46]] 6. 始终从[1]开始你的引用,每个额外的内联引用递增1。不要使用行号作为内联引用编号,否则我会失去工作。 “”” |
在整个Agent之中,利用Event来进行传递的,诸如
InputEvent:用户输入/文件上传
ParseEvent:触发文档解析
ChatEvent:提交用户查询
ChatResponseEvent:包含引用的结构化响应
这里其中route函数就会返回两种Event
|
@step
def route(self, ev: InputEvent) -> ParseEvent | ChatEvent: if ev.attachment: return ParseEvent( attachment=ev.attachment, file_name=ev.file_name, msg=ev.msg ) return ChatEvent(msg=ev.msg) |
利用函数声明接受的Event类型来进行传递
其次是文档解析,利用了LlamaParse
将其解析为了Markdown并对后续进行支持。
后续在chat阶段,就会阅读上文解析的文档,并加入到相关大模型的调用中,并进行相关的引用解析,传递给下文
|
@step
async def chat(self, ctx: Context, event: ChatEvent) -> ChatResponseEvent: current_messages = await ctx.get(‘messages’, default=[]) current_messages.append(ChatMessage(role=’user’, content=event.msg)) ctx.write_event_to_stream( LogEvent( msg=f’正在与{len(current_messages)}条初始消息进行对话。’ ) ) document_text = await ctx.get(‘document_text’, default=”) if document_text: ctx.write_event_to_stream( LogEvent(msg=’正在插入系统提示…’) ) input_messages = [ ChatMessage( role=’system’, content=self._system_prompt_template.format( document_text=document_text ), ), *current_messages, ] else: input_messages = current_messages response = await self._sllm.achat(input_messages) response_obj: ChatResponse = response.raw ctx.write_event_to_stream( LogEvent(msg=’收到LLM响应,正在解析引用…’) ) current_messages.append( ChatMessage(role=’assistant’, content=response_obj.response) ) await ctx.set(‘messages’, current_messages) # 从文档文本中解析引用 citations = {} if document_text: for citation in response_obj.citations: line_numbers = citation.line_numbers for line_number in line_numbers: start_idx = document_text.find( f”<line idx='{line_number}’>” ) end_idx = document_text.find( f”<line idx='{line_number + 1}’>” ) citation_text = ( document_text[ start_idx + len(f”<line idx='{line_number}’>”) : end_idx ] .replace(‘</line>’, ”) .strip() ) if citation.citation_number not in citations: citations[citation.citation_number] = [] citations[citation.citation_number].append(citation_text) return ChatResponseEvent( response=response_obj.response, citations=citations ) |
说完了这个简单的Agent,我们看下Task Manger之中,是如何使用这个Agent的
首先在TaskManager之中的 _run_streaming_agent
|
async def _run_streaming_agent(self, request: SendTaskStreamingRequest):
task_send_params: TaskSendParams = request.params task_id = task_send_params.id session_id = task_send_params.sessionId input_event = self._get_input_event(task_send_params) try: ctx = None handler = None # 检查我们是否有此会话的保存上下文状态 print(f’任务数量: {len(self.tasks)}’, flush=True) print(f’上下文状态数量: {len(self.ctx_states)}’, flush=True) saved_ctx_state = self.ctx_states.get(session_id, None) if saved_ctx_state is not None: # 使用现有上下文恢复 logger.info(f’使用保存的上下文恢复会话 {session_id}’) ctx = Context.from_dict(self.agent, saved_ctx_state) handler = self.agent.run( start_event=input_event, ctx=ctx, ) else: # 新会话! logger.info(f’启动新会话 {session_id}’) handler = self.agent.run( start_event=input_event, ) # 流式传输更新 async for event in handler.stream_events(): if isinstance(event, LogEvent): # 将日志事件作为中间消息发送 content = event.msg parts = [{‘type’: ‘text’, ‘text’: content}] task_status = TaskStatus( state=TaskState.WORKING, message=Message(role=’agent’, parts=parts), ) latest_task = await self.update_store( task_id, task_status, None ) await self.send_task_notification(latest_task) # 发送状态更新事件 task_update_event = TaskStatusUpdateEvent( id=task_id, status=task_status, final=False ) await self.enqueue_events_for_sse( task_id, task_update_event ) # 如果我们到达这里而没有遇到返回,等待最终响应 final_response = await handler if isinstance(final_response, ChatResponseEvent): content = final_response.response parts = [{‘type’: ‘text’, ‘text’: content}] metadata = ( final_response.citations if hasattr(final_response, ‘citations’) else None ) if metadata is not None: # 确保元数据是字符串键的字典 metadata = {str(k): v for k, v in metadata.items()} # 保存上下文状态以恢复当前会话 self.ctx_states[session_id] = handler.ctx.to_dict() artifact = Artifact( parts=parts, index=0, append=False, metadata=metadata ) task_status = TaskStatus(state=TaskState.COMPLETED) latest_task = await self.update_store( task_id, task_status, [artifact] ) await self.send_task_notification(latest_task) # 发送工件更新 task_artifact_update_event = TaskArtifactUpdateEvent( id=task_id, artifact=artifact ) await self.enqueue_events_for_sse( task_id, task_artifact_update_event ) # 发送最终状态更新 task_update_event = TaskStatusUpdateEvent( id=task_id, status=task_status, final=True ) await self.enqueue_events_for_sse(task_id, task_update_event) except Exception as e: logger.error(f’流式响应时发生错误: {e}’) logger.error(traceback.format_exc()) # 向客户端报告错误 await self.enqueue_events_for_sse( task_id, InternalError( message=f’流式响应时发生错误: {e}’ ), ) # 在错误情况下清理上下文 if session_id in self.ctx_states: del self.ctx_states[session_id] |
在其中,一方面支持上下文的恢复机制
状态检查:检查是否存在保存的上下文。上下文重建:从字典重建完整的上下文对象。无缝切换:新会话和恢复会话的无缝处理。
另一方面支持流式的返回机制,可以让任务在执行的中间状态不断地推流进行返回。
并且在有错误的时候,清除上下文并返回。
总结一下,我们首先说了下LlamaIndex的使用,利用其构建了一个支持文件上传,向量索引,多轮对话的智能Agent。并将其最终融入到了A2A之中。