Hive复习
- Hive中外部表和内部表的区别
内部表是存储在Hive自身,外部表则是由HDFS管理
存储位置也不一样
在删除的时候,对于内部表,则是全部删除,对于外部表,则是只删除元数据信息
- Hive的索引
Hive中并不是很适合索引,因为索引需要额外的空间存储,所以早期是存在索引的,但是在后期,已经使用物化视图取代了索引了。
- ORC,Parquet等列式存储的优点。
Parquet 则是支持嵌套的数据结构,就跟Java中的变量表中一样,可以根据复杂类型的定义不断解析为基本定义
而且Parquet文件是自解析的,每个文件都包含这个文件的数据和元数据信息
ORC也是一样,也是自描述的,其元数据信息和数据信息都保存在文件中
ORC使用了更加精准的索引信息,可以在读取的时候根据位移量选择某一row进行读取
ORC还默认使用ZLIB进行压缩,因此占用的存储空间也更小
- Hive中,或者说常见数据仓库中的存储模型
最常见的是星型模型
也就是以一个事实表为中心,扩展出不同纬度的纬度表
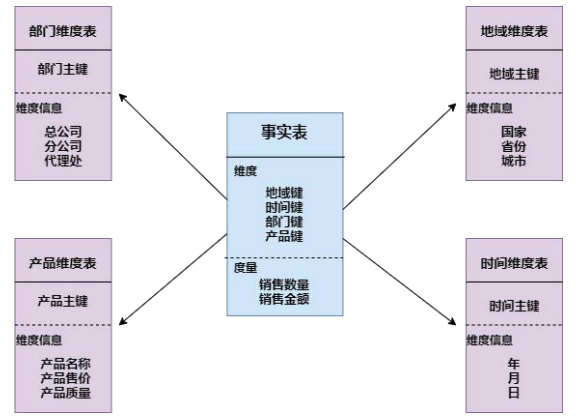
以事实表为核心,其他的纬度表成星状散列
然后事实表中存储维度表的主键。
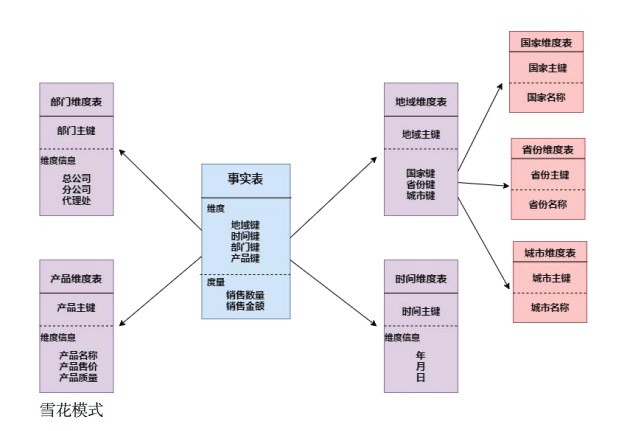
然后是雪花模型,也就是以一个事实表为中心,不断的用维度表向外扩散
在之后是最常见的星座模型
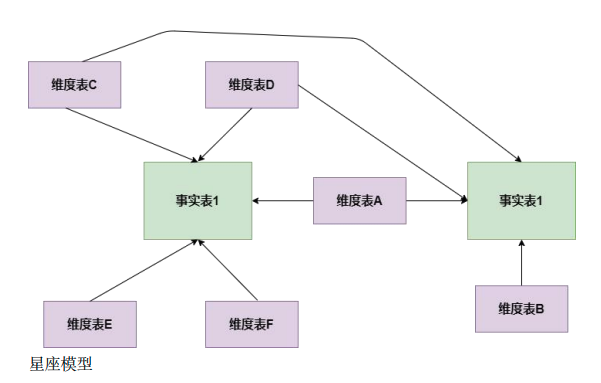
基于多张事实表,在其之间共享维度信息,这也是当前数据仓库中最为常见的建模方式
- Hive中需要数据仓库分层吗,为什么
很常见,需要进行大量的预处理,加快用户的查询速度,直接展示聚合好的数据指标更能提升用户的使用体验
而且可以分层管理,将多层的清理概念拆分,拆分的相对简单。
- Hive可以解析JSON串吗
如果是以字符串的形式存储在Hive中的,可以使用相关函数解析
如果需要导入前拆分,可以利用第三方库
- Order by语法和sort by语法
Order by 全局排序,所以需要较长的计算时间,以及只有一个reducer
而sort by,则保证局部有序,所以就是每个reducer的输出有序,但不保证全局有序
- Hive 小文件过多怎么解决
Hive 自带了一个concatenate命令,可以用于合并
不过其支持的文件类型比较少, 而且并不能制定合并后的文件数量
而且多次执行也会根据文件的大小而达到最终的限制
或者减少Reduce数量,毕竟reduce 的数量决定了输出的文件个数,可以调整reduce数量来控制生成的文件数量。
关于reduce的数量,可以根据直接设置来限制reduce的数量,也可以通过在查询的时候通过函数进行设置。
通过archive将小文件将小文件进行归档,从而减少namenode的内存访问的同时,控制小文件的归档
- Hive中不同引擎的区别
常见的引擎有 Mr tez spark 三者的区别在于
MR 是一种多job 串联的方式,基于磁盘,中间会多次落盘,所以适合处理数据量极其大的数据
Spark 引擎则是会在Shuffle的时候进行落盘,但是次数并不多,适合处理天级别数据量的数据
Tez则是完全基于内存,如果随意使用,小心OOM,适合数据量小,快速出结果的场景。
- Hive的调优方法
常见的方法有数据压缩,参数调优,join时的顺序调整
对于数据压缩,可以考虑在存储的时候使用orc或者parquet进行存储,方便读取,使用snappy进行压缩,这样在保留读写能力的基础上,可以降低网络传输量
其次是参数优化,首先可以调整并行季度
或者调整jvm参数
最后是sql的优化,比如在join的时候,可以进行顺序调整,将小表放在内存中执行