本章我们主要说Starrocksde 表设计,也就是不同的表模型,他们的区别和使用
并且会说在创建表的时候,需要考虑的分区分桶,以及排序键的设置
不过在说明不同表模型之前,我们先说下Starrocks中的存储模型
StarRocks 是列式存储的,每行数据对应用户一条记录,每列数据具有相同的数据类型。所有数据行的列数相同,可以动态增删列。在物理存储中,数据会按照列进行存储,一行数据的所有列值在各自的数组中按照列顺序排列,即拥有相同的数组下标。下标则会根据用户的设置计算得来。而如果采用聚合模型,列可以分为维度列(也称为 Key 列)和指标列(也称为 Value 列)。
针对列式存储模型,我们仍可以使用索引进行加速
这里的索引是前缀索引,跟mysql中概念一样,如果查询中覆盖了索引中前缀的字段,那么可以加速查询
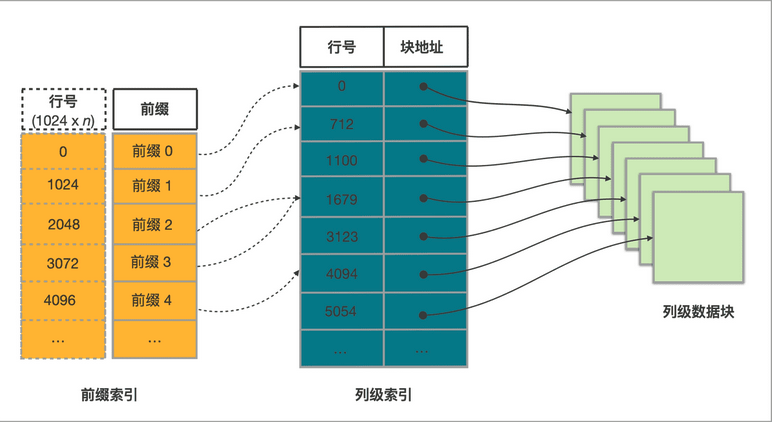
整体概念如上,自上往下说的话
表中每 1024 行数据构成一个逻辑数据块 (Data Block)。每个逻辑数据块在前缀索引表中存储一个索引项,我们根据前缀可以获取到对应的行数
根据行数找到对应的块地址
表中每列数据都按 64 KB 分块存储。数据块作为一个单位单独编码、压缩,也作为 I/O 单位,整体写回设备或者读出。
所以索引查找流程就是
|
在此基础上,Starrocks提供了不同的表模型,和不同的加速查询的机制
比如从表模型上面提供了预先聚合的能力,通过预先聚合,可以加速聚合操作。
比如在存储的时候,支持分区分桶。每个 Tablet 多副本冗余存储在 BE 上,查询时,多台 BE 可以并行地查找 Tablet,从而快速获取数据。
还支持为数据表创建物化视图。物化视图的数据组织和存储与数据表相同,但物化视图拥有自己的前缀索引
以及布隆过滤器 (Bloom Filter)、ZoneMap 索引和 位图 (Bitmap) 索引等列级别的索引技术。
那么我们先从表模型说起
整体分为了四种数据模型,分别是明细模型 (Duplicate Key Model)、聚合模型 (Aggregate Key Model)、更新模型 (Unique Key Model) 和主键模型 (Primary Key Model)。
在说四种模型中我们首先要说的概念是排序键。排序键通常为查询时过滤条件频繁使用的一个或者多个列,用以加速查询。 明细模型中,数据按照排序键 DUPLICATE KEY 排序,并且排序键不需要满足唯一性约束。 聚合模型中,数据按照排序键 AGGREGATE KEY 聚合后排序,并且排序键需要满足唯一性约束。 更新模型中,数据按照排序键 UNIQUE KEY REPLACE 后排序,并且排序键需要满足唯一性约束。 主键模型支持分别定义主键和排序键,主键 PRIMARY KEY 需要满足唯一性和非空约束,主键相同的数据进行 REPLACE。排序键是用于排序,由 ORDER BY 指定 。
在具体的表模型中,比如明细模型,是默认的建表模型。如果在建表时未指定任何模型,默认创建的是明细类型的表。
常见于分析原始数据,例如原始日志、原始操作记录等。
表的DDL如下
|
CREATE TABLE IF NOT EXISTS detail (
event_time DATETIME NOT NULL COMMENT “datetime of event”, event_type INT NOT NULL COMMENT “type of event”, user_id INT COMMENT “id of user”, device_code INT COMMENT “device code”, channel INT COMMENT “” ) DUPLICATE KEY(event_time, event_type) DISTRIBUTED BY HASH(user_id) PROPERTIES ( “replication_num” = “3” ); |
其中的DUPLICATE KEY是排序键,用于加速查询,如果未指定,则默认选择表的前三列作为排序键。
DISTRIBUTED BY HASH,用于均匀分布存储,也可以加快查询
其次是聚合模型
分为指标列和排序列,多条数据具有相同的指标列集合时,指标列会进行聚合。
适用于统计用户的访问总时长、访问总次数。
查询时候直接进行汇总类查询,比如 SUM、MAX、MIN等类型的查询
其聚合可以分为定时聚合和查询聚合
定时聚合会因为数据分批次多次导入至聚合模型中,会生成多个版本的文件,多个版本的文件定期合并成一个大版本文件时,同一排序键的数据会进行一次聚合。
查询的时候所有版本中同一排序键的数据进行聚合,然后返回查询结果。
表的DDL为
|
CREATE TABLE IF NOT EXISTS example_db.aggregate_tbl (
site_id LARGEINT NOT NULL COMMENT “id of site”, date DATE NOT NULL COMMENT “time of event”, city_code VARCHAR(20) COMMENT “city_code of user”, pv BIGINT SUM DEFAULT “0” COMMENT “total page views” ) AGGREGATE KEY(site_id, date, city_code) DISTRIBUTED BY HASH(site_id) PROPERTIES ( “replication_num” = “3” ); |
我们指定了AGGREGATE KEY 显式定义排序键
并通过在列名后指定聚合函数,定义该列为指标列。一般为需要汇总统计的数据。
支持的聚合类型为
|
支持的聚合类型如下:
* SUM、MAX、MIN、REPLACE * HLL_UNION(仅用于 HLL列,为 HLL 独有的聚合方式)。 * BITMAP_UNION(仅用于 BITMAP 列,为 BITMAP 独有的聚合方式)。 * REPLACE_IF_NOT_NULL:这个聚合类型的含义是当且仅当新导入数据是非 NULL 值时会发生替换行为。如果新导入的数据是 NULL,那么 StarRocks 仍然会保留原值。 |
详情请见
https://docs.starrocks.io/zh-cn/latest/sql-reference/sql-statements/data-definition/CREATE%20TABLE
然后更新模型是一种特别的聚合模型,查询时返回主键相同的一组数据中的最新数据
适合于分析电商订单。在电商场景中,订单的状态经常会发生变化。
对应的DDL如下
|
CREATE TABLE IF NOT EXISTS orders (
create_time DATE NOT NULL COMMENT “create time of an order”, order_id BIGINT NOT NULL COMMENT “id of an order”, order_state INT COMMENT “state of an order”, total_price BIGINT COMMENT “price of an order” ) UNIQUE KEY(create_time, order_id) DISTRIBUTED BY HASH(order_id) PROPERTIES ( “replication_num” = “3” ); |
主键通过 UNIQUE KEY 定义。
最后是主键模型
数据导入至主键模型的表时先按照排序键排序后存储。查询时返回主键相同的一组数据中的最新数据。支持了支持谓词和索引下推。
常见于实时对接事务型数据至 StarRocks。事务型数据库中,除了插入数据外,一般还会涉及较多更新和删除数据的操作,因此事务型数据库的数据同步至 StarRocks 时,建议使用主键模型。可以考虑使用通过 Flink-CDC 等工具直接对接 TP 的 Binlog
比起更细模型的Merge-On-Read 的策略,主键模型采用了 Delete+Insert 的策略
创建表的ddl语句为
|
create table orders (
dt date NOT NULL, order_id bigint NOT NULL, user_id int NOT NULL, merchant_id int NOT NULL, good_id int NOT NULL, good_name string NOT NULL, price int NOT NULL, cnt int NOT NULL, revenue int NOT NULL, state tinyint NOT NULL ) PRIMARY KEY (dt, order_id) PARTITION BY RANGE(`dt`) ( PARTITION p20210820 VALUES [(‘2021-08-20’), (‘2021-08-21’)), PARTITION p20210821 VALUES [(‘2021-08-21’), (‘2021-08-22’)), PARTITION p20210929 VALUES [(‘2021-09-29’), (‘2021-09-30’)), PARTITION p20210930 VALUES [(‘2021-09-30’), (‘2021-10-01’)) ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( “replication_num” = “3”, “enable_persistent_index” = “true” ); |
需要注意,这个类型的表是需要先定义一个PRIMARY KEY
主键支持以下数据类型BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、VARCHAR/STRING。并且不允许为 NULL。
分区列和分桶列必须在主键中。
Order by 指定排序键,可以指定为任意列的排序组合,也是前缀主键的构建依据
在说完了四种表模型之后,我们可以看下Starrocks为加速数据查询做的优化,
首先是数据分布方式
StarRocks 支持如下两种数据分布方式:
Hash 数据分布方式:一张表为一个分区,分区按照分桶键和分桶数量进一步进行数据划分。
Range+Hash 数据分布方式:一张表拆分成多个分区,每个分区按照分桶键和分桶数量进一步进行数据划分。
简单的hash只需要指定DISTRIBUTED BY HASH(site_id);
而分区则可以利用PARRTITION BY
|
CREATE TABLE site_access(
event_day DATE, site_id INT DEFAULT ’10’, city_code VARCHAR(100), user_name VARCHAR(32) DEFAULT ”, pv BIGINT SUM DEFAULT ‘0’ ) AGGREGATE KEY(event_day, site_id, city_code, user_name) PARTITION BY RANGE(event_day) ( PARTITION p1 VALUES LESS THAN (“2020-01-31”), PARTITION p2 VALUES LESS THAN (“2020-02-29”), PARTITION p3 VALUES LESS THAN (“2020-03-31”) ) DISTRIBUTED BY HASH(site_id); |
将数据分为不同区间。针对每一个管理单元选择相应的存储策略,比如副本数、分桶数、冷热策略和存储介质等。
对于分桶,使用很简单,比如DISTRIBUTED BY HASH(site_id);
其中支持多个字段,但是创建后就不能修改,需要在创建的时候考虑尽可能的平均分布且能覆盖查询条件
而对于分区,我们可以详细说下
首先是手动创建分区
目前仅支持分区键的数据类型为日期和整数类型
|
CREATE TABLE site_access(
event_day DATE, site_id INT DEFAULT ’10’, city_code VARCHAR(100), user_name VARCHAR(32) DEFAULT ”, pv BIGINT SUM DEFAULT ‘0’ ) AGGREGATE KEY(event_day, site_id, city_code, user_name) PARTITION BY RANGE(event_day) ( PARTITION p1 VALUES LESS THAN (“2020-01-31”), PARTITION p2 VALUES LESS THAN (“2020-02-29”), PARTITION p3 VALUES LESS THAN (“2020-03-31”) ) DISTRIBUTED BY HASH(site_id); |
批量创建分区
利用规则自动创建分区,START,END分别指定开始和结束,EVERY指定增量
|
CREATE TABLE site_access (
datekey DATE, site_id INT, city_code SMALLINT, user_name VARCHAR(32), pv BIGINT DEFAULT ‘0’ ) ENGINE=olap DUPLICATE KEY(datekey, site_id, city_code, user_name) PARTITION BY RANGE (datekey) ( START (“2021-01-01”) END (“2021-01-04”) EVERY (INTERVAL 1 DAY) ) DISTRIBUTED BY HASH(site_id) PROPERTIES ( “replication_num” = “3” ); |
这样我们创建了至少三个分区,对应的语句可以为
|
PARTITION BY RANGE (datekey) (
PARTITION p20210101 VALUES [(‘2021-01-01’), (‘2021-01-02’)), PARTITION p20210102 VALUES [(‘2021-01-02’), (‘2021-01-03’)), PARTITION p20210103 VALUES [(‘2021-01-03’), (‘2021-01-04’)) ) |
甚至可以创建多个不同的分区语句
|
CREATE TABLE site_access (
datekey DATE, site_id INT, city_code SMALLINT, user_name VARCHAR(32), pv BIGINT DEFAULT ‘0’ ) ENGINE=olap DUPLICATE KEY(datekey, site_id, city_code, user_name) PARTITION BY RANGE (datekey) ( START (“2019-01-01”) END (“2021-01-01”) EVERY (INTERVAL 1 YEAR), START (“2021-01-01”) END (“2021-05-01”) EVERY (INTERVAL 1 MONTH), START (“2021-05-01”) END (“2021-05-04”) EVERY (INTERVAL 1 DAY) ) DISTRIBUTED BY HASH(site_id) PROPERTIES ( “replication_num” = “3” ); |
数字的使用更为简单
PARTITION BY RANGE (datekey) (
START (“1”) END (“5”) EVERY (1)
)
自增1,开始为1,结束为5
甚至还有自动创建分区的表,您只需要在包含时间函数的分区表达式中,指定一个 DATE 或者 DATETIME 类型的分区列,以及指定分区粒度(年、月、日或小时),就可以自动在数据录入的时候进行分区
上限默认为 4096,由 FE 配置参数 max_automatic_partition_number 决定
现在支持两种语法
|
PARTITION BY date_trunc(<time_unit>,<partition_column_name>)
… [PROPERTIES(“partition_live_number” = “xxx”)]; |
|
PARTITION BY time_slice(<partition_column_name>,INTERVAL N <time_unit>[, boundary]))
… [PROPERTIES(“partition_live_number” = “xxx”)]; |
示例为
PARTITION BY date_trunc(‘day’, event_day)
PARTITION BY time_slice(event_day, INTERVAL 7 day)
对于其中参数partition_live_number则是指定保留最近多少数量的分区。最近是指分区按时间的先后顺序进行排序,
需要注意,暂时不支持使用 Spark Load 导入数据至自动创建分区的表。
而且,批量创建和自动创建有些冲突,如果想要并存,只能使用函数data_trunc, 且粒度相同,语法INTERVAL仅为1
除此外还有动态分区,不过这一个仅仅适用于一些数据计算的场景,有兴趣大家可以去链接中看下
https://docs.starrocks.io/zh-cn/latest/table_design/dynamic_partitioning
分区也支持对应的增加和删除
ALTER TABLE site_access
ADD PARTITION p4 VALUES LESS THAN (“2020-04-30”)
DISTRIBUTED BY HASH(site_id);
ALTER TABLE site_access
DROP PARTITION p1;
在starrocks的数据存储时候,还支持使用不同的压缩算法,LZ4、Zstandard(或 zstd)、zlib 和 Snappy。默认是LZ4
其压缩率和压缩/解压缩性能上有所不同,一般压缩率是zlib > Zstandard > LZ4 > Snappy
不过一般压缩率越高,性能越差,我们为了更快的实时性能分析,往往会考虑最差的压缩率来获取最高的查询性能
|
CREATE TABLE `data_compression` (
`id` INT(11) NOT NULL COMMENT “”, `name` CHAR(200) NULL COMMENT “” ) ENGINE=OLAP UNIQUE KEY(`id`) COMMENT “OLAP” DISTRIBUTED BY HASH(`id`) PROPERTIES ( “compression” = “ZSTD” ); |
最后,我们说下前缀索引是怎么来的
我们往往没有在DDL中指定前缀索引,那么是怎么来的,一般来说,其实就是排序键,而排序键,在不同表模型的指定语句不一样
在明细模型中,排序列就是通过 DUPLICATE KEY 关键字指定的列。
在聚合模型中,排序列就是通过 AGGREGATE KEY 关键字指定的列。
在更新模型中,排序列就是通过 UNIQUE KEY 关键字指定的列。
在主键模型中,解耦了主键列和排序列,排序列通过 ORDER BY 关键字指定,主键列通过 PRIMARY KEY 关键字指定。
而在明细,聚合,更新模型中,对于列的指定还有约束
要求必须要从第一个列开始定义,并且要连续,还要顺序和表定义顺序一致
一个表有site_id、city_code、user_id 和 pv 四列
|
正确的排序列
site_id 和 city_code site_id、city_code 和 user_id 错误的排序列 city_code 和 site_id city_code 和 user_id site_id、city_code 和 pv |
主键模型可以跳脱这个限制
|
CREATE TABLE site_access_primary
( site_id INT DEFAULT ’10’, city_code SMALLINT, user_id INT, pv BIGINT DEFAULT ‘0’ ) PRIMARY KEY(site_id) DISTRIBUTED BY HASH(site_id) ORDER BY(site_id,city_code); |
Starrocks对前缀索引做了一些限制
前缀索引列的数量不能超过 3。
前缀索引项的长度不能超过 36 字节。
前缀索引中不能包含 FLOAT 或 DOUBLE 类型的列。
前缀索引中 VARCHAR 类型的列只能出现一次,并且处在末尾位置。