即使不专职于性能工程师,但是对于日常工作的需要,对于工程师职业的进阶之路,是必不可少的
首先是对于服务变慢的定义
服务是突然变慢还是长时间运行后变慢的
慢的定义是什么?是对于请求的反应延时加大吗
首先,问题可能来自于Java服务本身,也可能是服务器本身导致的,我们首先检查应用本身的错误日志
对于分布式应用,一般都有着系统的日志,性能等监控系统,一些Java诊断工具也可以使用,比如JFR,可以监视应用是否出现某些异常
利用工具来排查是否拥有某些异常
如果工具没有没有检测出异常
那么就检测系统级别的资源情况,监控CPU 内存 等资源是否被其他进程占用
监控Java服务本身,比如GC 日志中是否观察到Full GC等恶劣情况,是否Minor GC变长了,利用jstat等工具,去进行内存的信息统计,利用jstack可以检查是否出现了死锁
如果还不能确定具体的问题,对应用进行Profiling吧,但是具有一定的侵入性,所以不建议在生产系
统使用
然后判断问题是否解决,如果不行,循环上述流程
虽然,一般很少有全面的性能问题诊断的机会,但是能表现出一个整体的印象,展示出一个思路,也是一种能力的体现
对于系统的学习,可以参考Charlie Hunt的Java Performance 或者 Scott Oaks的 Java Performance:The Difinitive Guide
我们常见的调优可以分为两类
自下而上,从CPU硬件底层开始调优,指令级别的优化,这需要非常专业的性能工程师来做,具有专业的工具
自上而下,从应用的顶层开始,逐步深入到不同的模块,找到可能的解决方案,最常见的性能分析
那么我们就从上而下,进行对应的调优思路解析
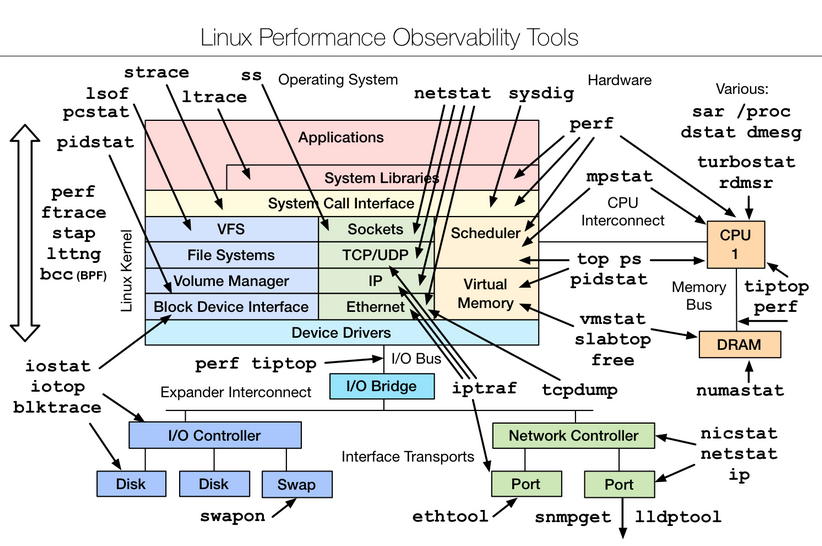
我们首先看查看内存和IO
对于CPU,首先就用top命令查看负载状态
我们可以先用top命令获取相应 pid ,然后利用jstack 获取线程栈,进行对应的ID即可
或者使用vjtools中的vjtop查看Java线程
我们也可以利用vmstat之类,上下文切换的数量
vmstat -1 -10
每秒上下文的切换很高,比系统中断高很多,就表明很可能因为不合理的多线程的调度所导致,利用pidstat等手段,进行具体的定位,不进一步展开
除了CPU 内存 和IO重要的注意事项
利用 free之类查看内存使用
进一步判断swap使用情况,top命令输出中有着Virt作为虚拟内存使用量,物理内存和swap求和,反推swap使用,JVM不希望发生大量的swap使用
对于IO问题,磁盘IO或者是网络IO,例如,利用iostat可以判断磁盘健康状况
对于JVM,我们可以利用JMV JConsole等工具进行运行时的监控
利用各种工具,在运行时进行堆转储分析,获取各个角度的统计数据
GC日志来判断Full GC MinorGC 引用堆积
对于应用Profiling,可以利用一些侵入的手段,进行收集运行时的细节
建议使用JFR配合JMC来做Profiling,从Hostsopt VM底层收集信息,进行优化,开销很低,低于2%
我们在运行的时候启动对一个的JFR,写入文件
Jcmd <pid> JFR.start duration=120s filename=myrecording.jfr
然后JMC进行打开.jfr文件,查看方法 异常 线程 IO 等细节