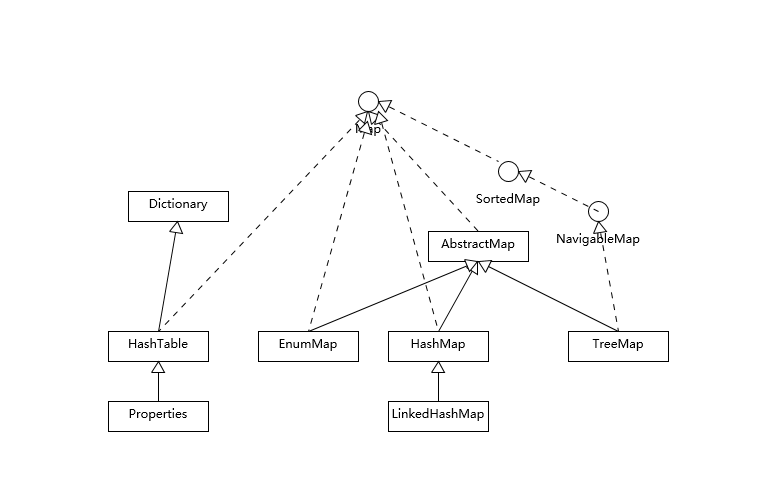
这三者都是常见的Map实现,都是键值对存储的容器类型
HashTable是同步容器,但是不支持null,而且简单的防止并发,所以不推荐使用
HashMap是更加广泛的哈希表行为,和HashTable一致,但不是同步的,但性能更好
TreeMap是一个基于红黑树提供的顺序访问Map,可以做到O(log(n))
对于HashMap并发环境下的无限循环占用CPU的问题则是可以通过使用其他数据类型来避免的
下面是关于Map的相关类图
HashMap依赖于其Hash码的有效性,所以最好保证HashCode的有效性
LinkedHashMap则可以保证插入顺序
是因为在内部为键值对维护了一个双向链表,保证了访问顺序,利用这个数据结构,可以做一些诸如使用次数低淘汰的机制
HashMap相关源码的分析
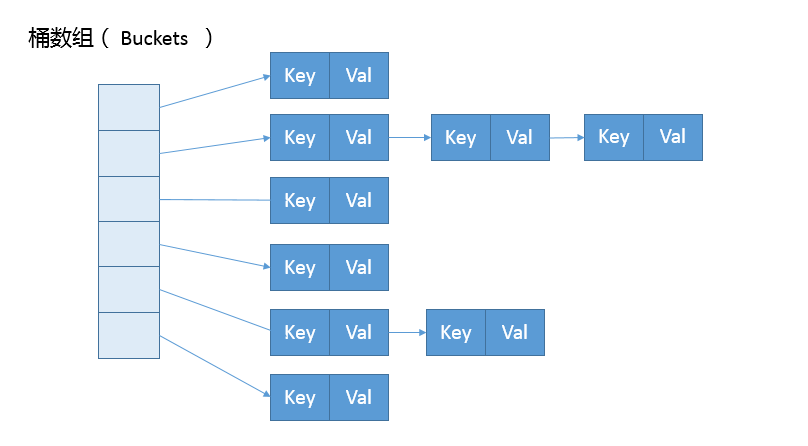
HashMap的数据结构
容量和负载系统
树化
HashMap的内部结构是一个数组和链表的结合体,数组内每个下标都是一个桶,哈希值为数组的下标,哈希值相同的键值对,则在链表内以链表的形式存储,链表大小超过阈值,则会被改造为树形结构
而初始化的时候,是一种懒加载机制
而真正初始化则是在putVal方法中

如果表格是null,resize则是初始化其,tab=resize()可以看出
如果容量超过负载树,则进行扩容
而在放入的过程中,则是会进行一个hash运算,而哈希值的源头并不是key本身的hashCode,而是Map内部自身的hash方法,而且将高维数据移到了低位进行异或运算
避免检查哈希值的低位
再说下resize()
其中会进行扩容
最大上线是2的30次方
其中扩容的阈值是(负载因子*容量)
而且往往是倍数调整
扩容后还需将数组中的老元素放在新的数组中,也是扩容的主要开销
扩容有助于避免空桶太多或者一个桶中数量太多

然后树化的改造也很清晰,就是bin的数量大于TREEIFY_THRESHOLD进行树化改造
不然就是简单的扩容
如果不进行树化改造,就会导致只有一个链表,而链表的查询效率低下
会导致存取性能降低
这样就会有服务器性能大量被消耗再次