34.如何避免Redis数据倾斜
在切片集群中,数据会按照一定的规则分布到不同的实例上保存,大抵都是Hash算法那一套,但是hash算法会不可避免的遇到一个问题,数据倾斜
常见的数据清洗有两方面,一方面关于数据量的倾斜,一方面是关于数据访问的倾斜
数据量的倾斜:因为hash算法可能导致多个key得到的hash值一致,故某些实例上的数据特别多
数据访问倾斜,每个集群上的数据量数量相似,但是存在某些热点数据,导致访问频繁
我们也是按照这两个方面,来分别讲解数据倾斜的原因及应对方案
1.数据量倾斜的成因及应对方案
数据量倾斜发生的时候,数据在切片集群上的多个实例分布不均,大量数据集中于一个或者几个实例
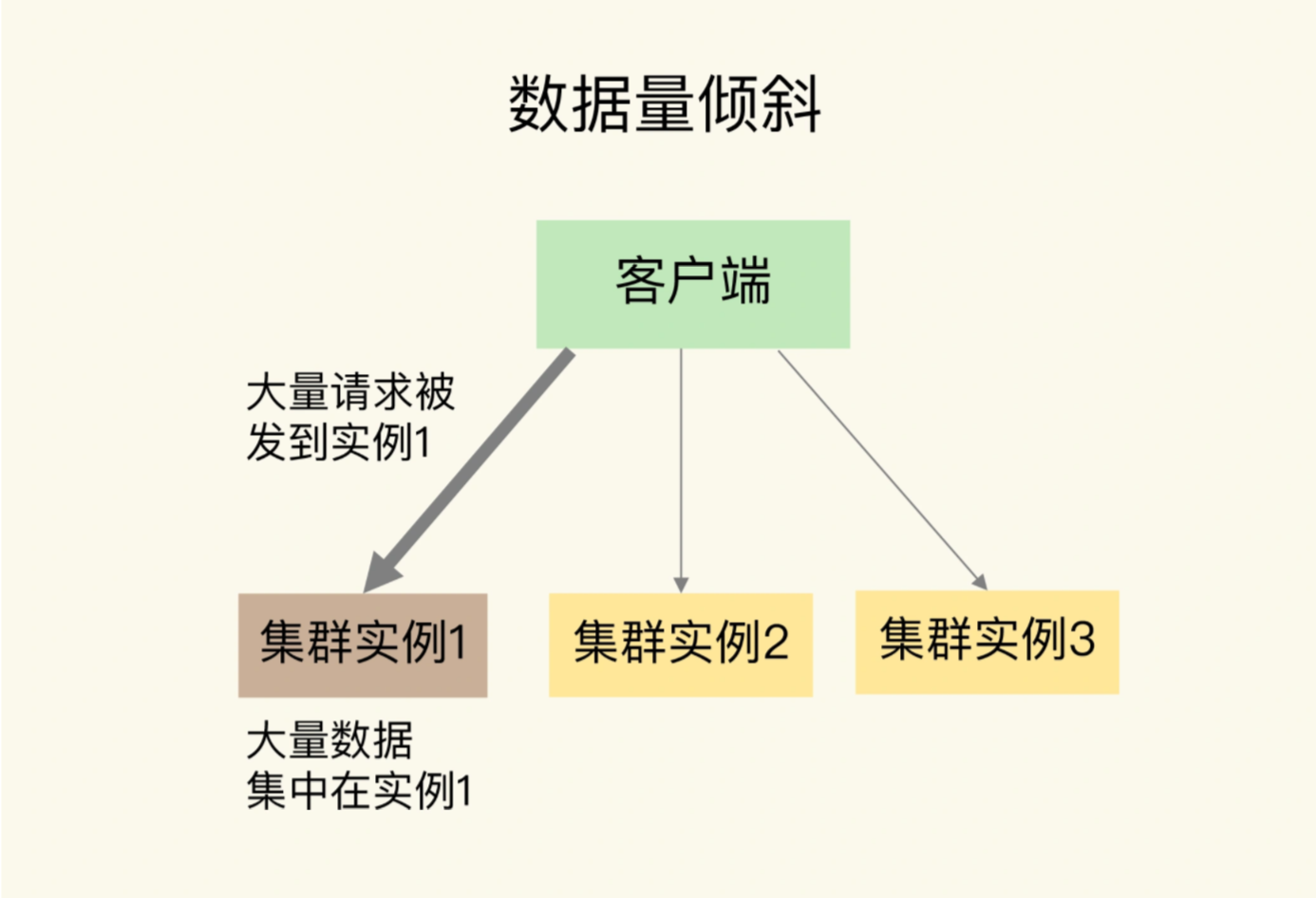
数据量倾斜如何产生的呢?分别存在以下几种原因,保存bigkey,Slot分配不均匀,以及Hash Tag
对于big key的产生原因,可能是某个实例上有bigkey,导致请求之后产生实例IO线程阻塞,如果bigkey的访问量较大,会影响到这个实例上其他请求被处理的速度
对于big key问题出现,最好的解决方案对这个bigkey进行拆分,比如一个集合类型 ,我们将其拆分为多个小的集合类型数据,分布到不同的实例上
假设Hash集合 user:info保存了100万个用户信息是一个bigkey,我们可以将其拆分一下,拆分为多个10万级别的代码,将一个bigkey化整为零,分散保存避免了bigkey
然后是Slot 分布不均匀导致倾斜,如果集群运维人员没有合理的分布Slot,导致大量的数据分配到一个Slot中,同一个Slot只会在一个实例分布,导致了大量数据被集中一个实例上,造成数据倾斜
对应这个问题,我们可以通过运维规范,分配前就避免把过多的Slot分配到同一个实例,如果分配过了,就考虑将Slot迁移到其他的实例,避免数据倾斜
不同集群上查看Slot分配情况方法不一样,如果是Redis Cluster就用 CLUSTER SLOTS 如果是Codis就可以使用codis dashboard上查看
比如我们执行CLUSTER SLOTS 查看SLOT分配情况,命令返回结果如下
| 127.0.0.1:6379> cluster slots
1) 1) (integer) 0 2) (integer) 4095 3) 1) “192.168.10.3” 2) (integer) 6379 2) 1) (integer) 12288 2) (integer) 16383 3) 1) “192.168.10.5” 2) (integer) 6379 |
如果需要重新分配,可以使用迁移命令,将这些Slot迁移到其他的实例,Redis Cluster的迁移命令如下
CLUSTER SETSLOT,使用不同的选项进行三种设置,分别是设置Slot要嵌入的目标实例,Slot迁出的实例,Slot所属的实例
CLUSTER GETKEYSINSLOT 获取某个Slot中的一定数量的key
MIGRATE 将一个key从源实例迁移到目标实例
假如要把Slot 300从源实例迁移到目标实例,如何做呢?
首先,我们先要目标实例5上执行下面的命令,Slot300的源实例设置为实例3,要从实例3上迁入Slot300
CLUSTER SETSLOT 300 IMPORTING 3
然后在实例3上,将Slot 300的目标实例设置为5,表示Slot 300要迁入实例5,如下所示
CLUSTER SETSLOT 300 MIGRATING 5
然后获取100个key,因为Slot的key数量比较多,需要多次执行下面的命令,分批次获得迁移key
CLUSTER GETKEYSINSLOT 300 100
之后开始迁移key,重复执行MIGRATE,进行key迁移
MIGRATE 192.168.10.5 6379 key1 0 timeout
还可以使用KEYS选项,一次性的迁移多个key,提升迁移的效率
对于Codis来说,我们可以执行如下的命令进行数据的迁移,将dashboard组件链接地址设置为ADDR,然后将Slot 300迁移到编号为6的codis server group上
codis-admin –dashboard=ADDR -slot-action –create –sid=300 -gid=6
最后是关于Hash Tag导致的倾斜
HashTag是在键值对中的一对花括号{},将key的一部分括起来,计算key的CRC16的值
举个例子,假设key是user:profile:3231,利用花括号进行包裹,key就变成了user:profile:{3231},客户端计算key的CRC16的值得时候,只会计算3231的CRC16的值
这样做的好处,利用hash tag,可以确保想要的key会被映射到一个Slot中,同时分配到一个实例上
下面就是使用Hash Tag之后,数据被映射到相同Slot的情况,可以看一下

上面就是加上Hash Tag的Slot分片
其常见于事务操作和返回查询的场景,因为Redis Cluster和Codis中本身不支持跨实例的事务操作和范围查询,业务应用需求时候,可以使用Hash Tag,将所有操作的数据映射到一个实例上,保证事务和范围查询
使用Hash Tag的潜在问题,就大量的数据被集中在一个实例上,导致数据倾斜,集群中的负载不均衡,如何应对呢?简单的方式就是进行相对应的取舍
2.数据访问倾斜的成因
发生数据访问倾斜的根本原因,就是实例上存在热点数据,一旦热点数据存在于某个实例中,那么这个实例访问量就会远高于其他的实例,面临巨大的访问压力
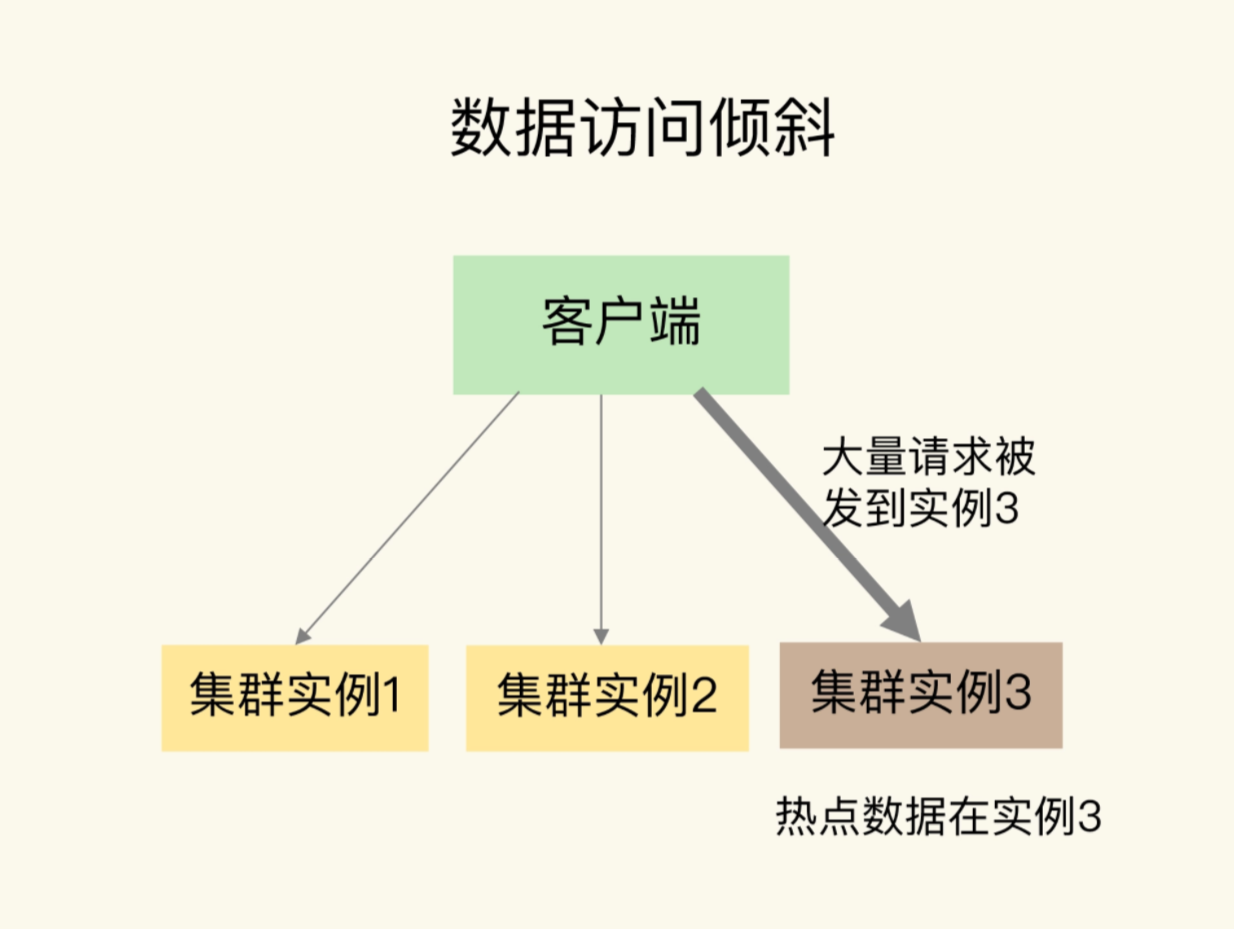
对于此的应对方式,由于热点数据往往是一个或者几个固定数据,且读多写少,我们可以采用热点数据多副本的方式来应对
将热点数据复制多分,每个副本的key前面加上一个随机前缀,这样其和其他副本的数据不会被映射到同一个Slot,这样访问的时候,加上对应的前缀,也可以保证热点数据的分摊
那么总结一下本章
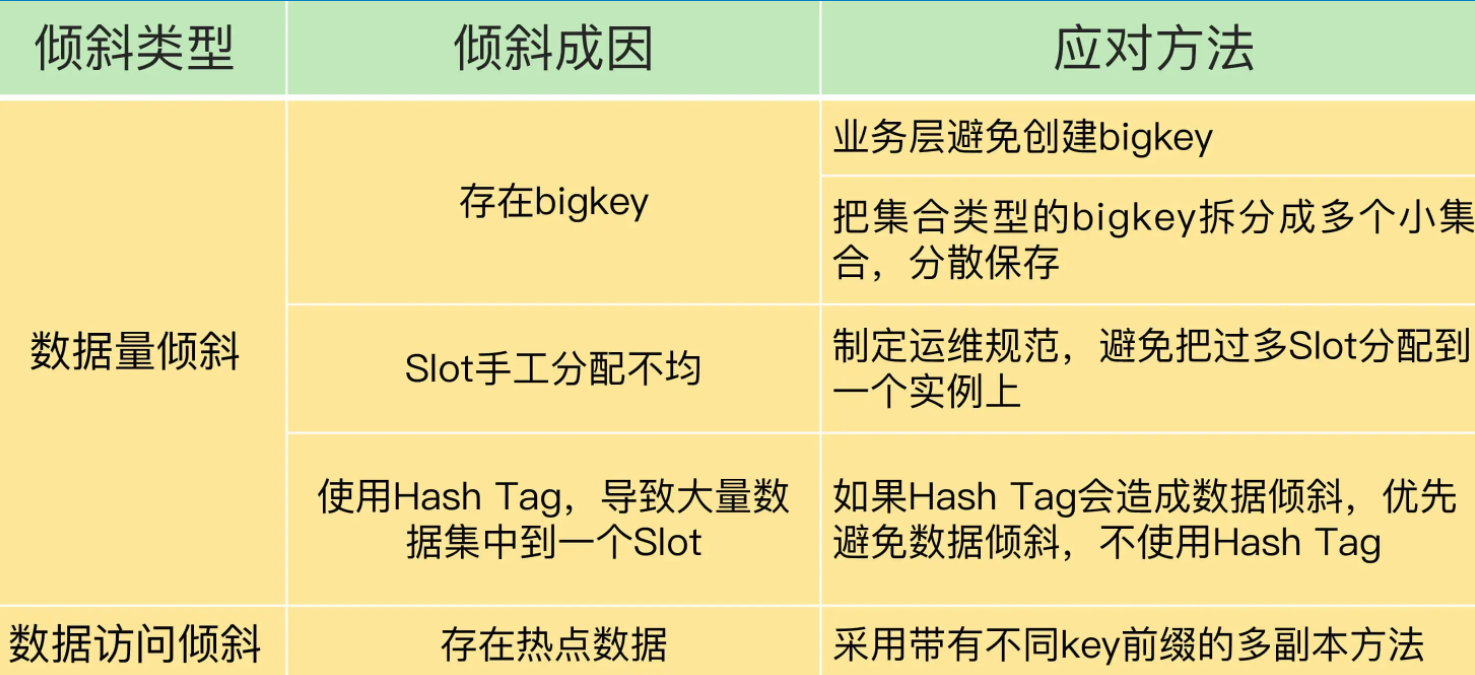
我们说了数据倾斜的两种可能性,数据量倾斜和数据访问倾斜
数据量倾斜的原因主要有三个,数据中有bigkey,导致实例数据量增加
Slot手工分配不均,导致某个或者某些的实例上有大量数据
使用了Hash Tag,数据集中在某些实例上
数据访问倾斜的主要原因是有热点数据的存在,导致大量访问请求到了热点数据所在的实例上
对应的解决方案,总结如下表
最后一个小建议,在构建切片集群的时候,尽量使用大小配置相同的实例,避免因为实例资源不均匀导致不同实例上分配不同弄数量的Slot