每次系统变慢的时候,我们首先会进行top命令或者uptime命令的执行
执行后显示的结果如下
$ uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88
上面的输出含义
前几行,分别是当前时间,系统运行时间,正在登录用户数
后面几个数字,分别是1分钟,5分钟,15分钟的平均负载
Load Average
后面几个数字呢,分别是1分钟 5分钟 15分钟的平均负载
平均负载,这个词对于很多人来说,可能熟悉又陌生,那么什么是平均负载
平均负载在直接理解上,是单位时间的CPU使用率,上面的0.63,代表CPU使用率是63%
但是实际上,平均负载是指的单位时间内系统处于可运行状态和不可中断状态的平均进程数,就是平均活跃进程数,它和CPU的使用率没有直接关系
对应的可运行状态和不可中断状态,可运行状态,就是使用CPU和等待CPU的进程,也就是ps命令看到的,处于R状态的进程
不可中断进程正处于内核态关键流程中的进程,流程不可打断,常见的等待硬件设备的I/O响应,就是ps命令的D状态的进程
当一个进程向磁盘读写数据时,为了保证数据的一致性,得到磁盘回复前,不能被其他进程或者中断打断的,不然可能出现磁盘和进程数据不一致的问题
不可中断状态就是系统对进程和硬件设备的一种保护机制
平均负载就是平均活跃进程数,平均活跃进程数,就是单位时间内的活跃进程数,实际上是活跃进程数的指数衰减平均是
既然平均的是活跃进程数,那么最完美的情况就是每个CPU上都运行的一个进程,如果平均负载是2
如果在2个CPU的系统,意味着所有CPU都刚好被完全占用
4个CPU的系统上,有50%的CPU空闲
1个CPU的系统中,意味着一半的进程竞争不到CPU
平均负载为多好最好呢?
平均负载最理解的情况是等于CPU个数,评判平均负载的时候,首先要知道系统有多少个CPU,可以利用top或者cat /proc/cpuinfo中读取
有了CPU个数,平均负载比CPU个数大的时候,系统就出现了过载
那么上面uptime的命令中可以获得,系统负载趋势的数据来源,我们可以更加全面的了解目前的负载状况
利用1 5 15分钟三个值进行比较,如果基本相同,相差不大,就说明负载均衡
如果1分钟的值小于15分钟,就说1分钟内的负载在减小,15分钟内有很大的负载
1分钟内的值远大于15分钟的值,就说明1分钟的负载在增加,可能是临时,也可能在持续增加下去
需要继续观察
我们在一个单CPU系统上看到平均负载为1.73 0.60 7.98
那么过去1分钟内,系统有73%的超载,15分钟内,698%的超载,负载在逐渐降低
生产环境中,平均负载有多高需要关注下呢?
一般来说,高于70%,就需要关注分析了
负载一旦过高还不关注,就会导致进程响应过慢,影响服务的正常功能
当然,如果要求严格,超过50%也可能需要进行负载排查调查了
我们最后说明一下平均负载和CPU使用率
平均负载代表的是活跃进程数包含了正在使用CPU的进程以及等待CPU和等待IO的进程
而常见的CPU负载出状况,可以分为三类,分别是
CPU密集型进程,基本上平均负载和CPU使用一致
IO密集型,IO等待导致平均负载升高,但是CPU使用率并不一定很高
大量等待CPU的进程调度会导致平均负载升高,CPU使用率也会很高
我们利用工具可以来模拟负载升高的情况
常见有 iostat mpstat pidstat,找到平均负载升高的根源
安装完成后进行相关的测试
stress是一个Linux系统的压力测试工具,用异常进程来模拟平均负载升高的场景
sysstat包含常用的Linux性能工具,分析系统性能
mpstat是一个常用多核CPU性能分析工具,实时查看每个CPU的性能指标,以及所有CPU的平均指标
pidstat是一个常用进程分析工具,实时查看进程的cpu 内存 IO 等指标
利用对应的命令,我们可以模拟不同的场景
1.CPU密集型的进程
终端运行stress命令,模拟一个CPU使用率100%的场景
stress –cpu 1 –timeout 600
第二个终端运行uptime查看对应的负载变化情况
第三个中断运行mpstat查看CPU使用率的变化情况
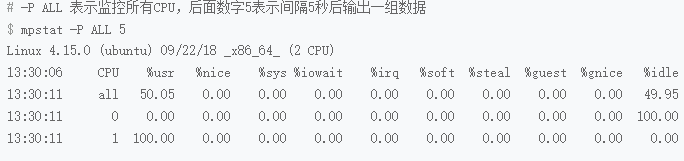
uptime可以看到,平均负载会慢慢的增加到1.00
但是iowait只有0,平均负载的升高正是由于CPU使用率为100%
对应的IO密集型进程
使用stress,可以模拟IO压力,不同的进行sync
stress -i 1 –timeout 600
第二个终端运行uptime查看平均负载的变化情况
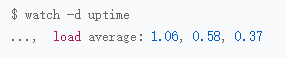
第三个终端mpstat查看CPU使用率变化
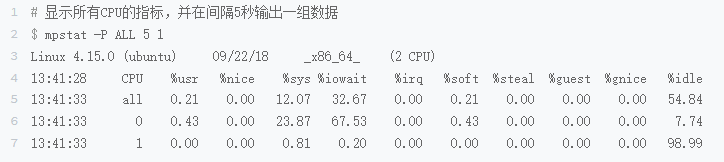
1分钟的平均负载会慢慢增加到1.06,其中一个CPU的使用达到了23,87,iowait达到了 67.53%
这就是stress导致的iowait增加
最后我们模拟一下大量进程的场景
当系统的运行进程超过CPU运行能力的时候,会出现等待CPU的进程
比如使用的是stress,模拟的是8个进程
但是只有两个CPU,比8个进程要少,所以CPU处于严重过载的状态,平均负载达到了7.9
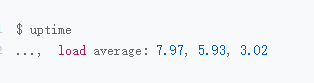
可以看出8个进程抢两个CPU,每个进程等待CPU的时间高达75%
总结一下
我们看一下平均负载的理解,就是反映整体的负载情况,只看平均负载本身,并不能直接发现,哪里出现了瓶颈
平均负载高可能是CPU密集型进程导致的
但是也可能是IO繁忙导致的
负载高的时候,可以使用mpstat pidstat等工具,辅助分析负载的来源
对于平均负载,常见的工具还有
htop进行查看
atop也可以进行查看