分区表中为什么在实际开发中,为什么不能使用分区表呢?
分区表是什么?
为了说明分区表的组织问题,先创建一个分区表t
| CREATE TABLE `t` (
`ftime` datetime NOT NULL, `c` int(11) DEFAULT NULL, KEY (`ftime`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY RANGE (YEAR(ftime)) (PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB, PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB, PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB, PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB); insert into t values(‘2017-4-1’,1),(‘2018-4-1’,1); |
这样就在这个表上,显示的ibd文件有以下四个 t#P#p_2017.ibd t#P#p_2018.ibd t#P#p_2019.ibd t#P#p_others.ibd
但是只有一个.frm文件
数据文件有4个,但是元数据文件只有一个
对于引擎层来说,这是4个表,对于Server层来说,这是一个表,接下来我们着重的探讨下分区表的行为
1.给分区表添加间隙锁的例子
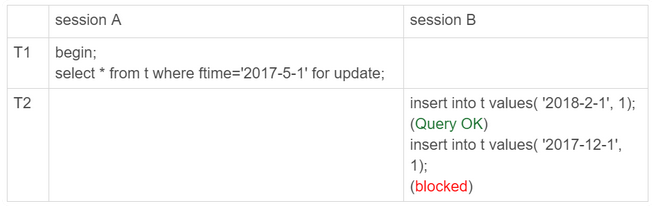
可以看出上面的加锁的实例
我们锁住了整个p2017的表,所以2017-12-1的操作失败了,但是没有锁住 2018-2-1
按常理来说,如果是一个普通表的话,那么应该锁住的范围是
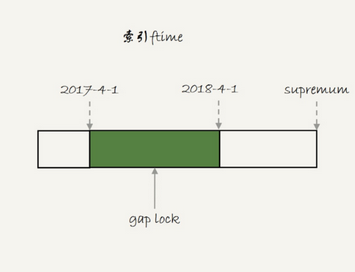
理论上2018-2-1应该可以锁住,但并没有
但是实际锁住的范围并非如此
session B的第一个insert语句是可以执行成功的,因为对于server层来说,这两个是同一个表,但是对于引擎层来说,这是两个不同的表
所以2017-4-1给p_2018表加上了锁,并没有给p_2019加上了锁,整体的加锁为
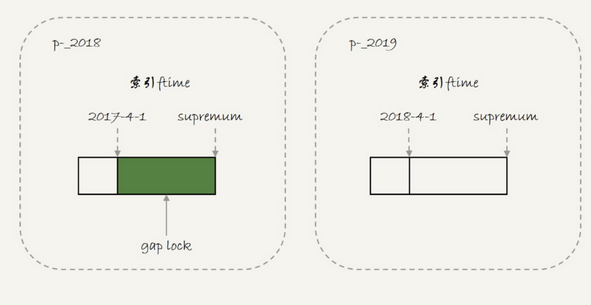
于是session B写入一条2018-2-1的时候是可以成功的,而要写入2017-12-1的记录,需要等待sessionA的间隙锁
这是分区表使用的是InnoDB引擎,如果换为MyISAM引擎呢?
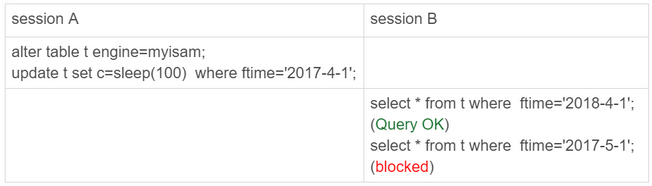
虽然MyISAM的表锁是在引擎层实现的,但是sessionA加的表锁,只加载了分区p_2017上,对于整个表的其他分区查询没有影响
这样看分区表还不错,但是分区表仍然有着一些问题
分区表的分区策略问题
每当第一次访问一个分区表的时候,MySQL都会把所有的分区访问了一遍,一个典型的报错就是,一个分区表的分区很多,超过了1000个,而MySQL默认的open_files_limit的参数是1024个,表示最多
只能打开1024个文件,从而超过导致报错问题

这个insert语句,只需要访问一个分区,导致出现了这个问题
当然为了避免这个问题,InnoDB进行了改进,从而避免了这个问题的存在,使用了innodb_open_files这个参数,就是innoDB打开文件的时候,如果超过了这个值,就会关掉一些之前打开的
也就是使用了innoDB引擎使用分区表不会出现报错的原因
整体来说
MyISAM引擎使用的分区策略,是通用分区策略,每次访问在分区server层控制,对于表文件的管理比较粗糙
InnnoDB在MySQL 5.7.9开始,引入了本地分区策略,内部管理打开分区的行为
于是MySQL从5.1.17开始,将MyISam的分区表标记为了弃用
从MySQL 8.0开始,就不允许创建MyISAM分区表了,只能创建已经实现了本地分区策略的引擎,只有InnoDB和NDB两个引擎支持了本地分区策略
而且对于server层,一个分区表就是一个整表

进行show processlist的话
可以看出虽然只是操作了p_2017这个表,但是仍然导致p_2018的alter语句被堵住了
这就是在server层来看,一个分区表共用一个MDL锁
暂时总结一下:
1.MySQL第一次打开一个分区表的时候,需要访问所有的分区
2.在server层,会认为这是一张表,共用一个MDL锁
3.引擎层则不这么认为,所以只会访问必要的分区
对于必要的分区,就是根据SQL中的where条件,结合分区的索引,来进行判断的,但是如果where中的条件没有分区的key的话 ,那么还是只能访问所有的分区了,这并非分区表的问题,而是where条件中的问题,即使是使用业务分表,where条件中没有分表的key,也需要物理上的访问其他的表
分区表适合在什么场景使用呢
分区表更适合对业务透明的事情,比如历史数据表,一个业务跑的够长,可能会根据时间来删除历史数据的需求,这是分区表可以上场了
根据时间来创建分区表
然后在需要清空的时候,使用语句alter table t drop partition来删除分区文件,比起drop 普通表,更加的快
总结一下:
本篇文章中:介绍了分区表的概念
说明了server层和引擎层对于分区表的处理方式
支持range和list hash来进行分区
分区表在和普通表比起来,必然会有着打开所有的分区的问题,和在server层上共用一个MDL锁
而且存在使用查询时候,因为没分区条件,导致需要进行全部的分区文件的扫描,当然,对于分区表不使用带有分区条件的查询,本身也是具有错误的
最后说一下,如果确定需要使用分区表的话,给分区表加索引的时候,可以如下的创建
因为分区key是最常见的,所以应该下加上(分区key,id)这个联合索引,这可以利用最佳左前缀来进行匹配,减少一个索引,而且经常有两者合用的情况
而且使用了innodb引擎,仍然需要一个单独的索引,于是可以再给id加上一个单独索引
下面就是一个常见的建表语句
create table t(
id int(11) NOT NULL AUTO_INCREMENT,
ftime datetime NOT NULL,
c int(11) DEFAULT NULL,
PRIMARY KEY (‘ftime’,’id’),
Key ‘id’ (‘id’)
)ENGINE=INNODB DEFAULT CHARSET=UTF8
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE=INNODB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE=INNODB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE=INNODB,
PARTITION p_2020 VALUES LESS THAN (2020) ENGINE=INNODB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE=INNODB,
)