主备架构必然存在着一种情况,就是主库会在紧急的情况下,将进行主备切换
主备切换会有两种情况,一种是主动切换,一种是被动切换
被动切换由HA系统发起,那么什么时候会发起这个切换呢,换而言之,什么时候算这个数据库出现问题了呢
1.Select 1进行判断
Select 1进行判断,只能判断这个库的进程还在,并不能说明这个库没有问题.
比如说,如下的情况

假设我们把innodb_thread_concurrency这个参数设置为3,说明只能有三个线程同时运行
这个情况就是select 1能够正常使用 ,但是查询库的任何操作都不能进行了
这说明select 1并不能检测出表是否正常
在InnoDB中,innodb_thread_concurrency参数默认值为0,表示不限制并发线程,但是还是设置上去好,设置一个64~128的值
这个参数能够设置最高的并发查询线程,而且对于等待的线程,MySql并不会将其归为并发线程中
如果设置为并发线程,
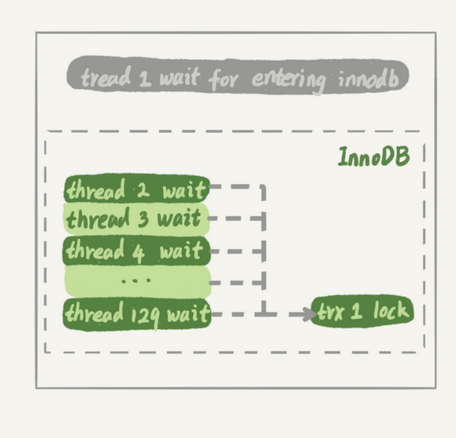
就是线程1执行begin 后,没有做其他事情,其他的线程都等待这个事务锁住的线程,导致其他线程占用了并发线程又什么活都不干,导致这个线程放不开,其他线程进不去
我们调整一下判断的方法:
创建一个表,比如叫health表,然后只放一条数据,定期查询这个表
可以查看并发线程过多导致数据库不可以用的情况
但是,只放一条数据去用于查询,在磁盘空间已经满了的情况下,是可以继续读取数据,但是不能提交或者更新了
于是这个语句需要变化,改为update,然后每次更新其中的时间字段
update mysql.health_check set t_modified=now();
但是备库上检测就不那么好做了,因为主备不可能分开对同一行进行更新,可能出现问题,导致主备同步停止
于是可以改为insert
insert into mysql.health_check(id,t_modified)values(@@server_id,now()) on duplicate key update t_modified=now()
规定了server_id不同,于是保证了双方插入的不同,
但是这只能判断是否可用,没法判断数据库慢的问题
因为这个update语句占用的IO资源很少
在服务器的IO资源分配上,会让每个请求都有机会获得IO资源,这时候update所需资源少就执行了,于是系统判断正常
于是这种情况仍然可能不靠谱
于是可以改为内部统计的方式
MySql内部统计了每一次IO的请求时间
MySQL在performance_schema库,就在file_summary_by_event_name表里统计了每次IO请求的时间
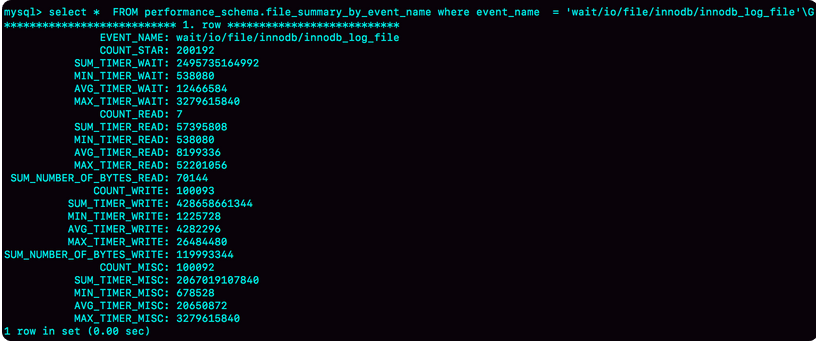
上面的wait/io/file/innodb/innodb_log_file
说明了redo_log的写入时间,第一列说明了EVENT_NAME表示的统计类型
接下来三组数据,显示了redo log的操作的时间统计
第一组表名了IO类型的统计,说明了总和最小值 平均值 最大值
第二组 读操作的统计
第三组 写操作的统计
每一次操作数据库,performace_shcema都统计这些信息
虽然统计这些信息会造成额外的性能下降,但是只多消耗10%
设置这些监控,可以使用如下语句
update setup_instruments set ENABLED=’YES,Timed=’YES’ where name like ‘%wait/io/file/innodb/innodb_log_file%’;
那么可以通过MAX_Time_WAIT来判断数据库是否出现了问题,设置IO请求超过了200毫秒,就认为出现了异常
mysql> select event_name,MAX_TIMER_WAIT FROM performance_schema.file_summary_by_event_name where event_name in (‘wait/io/file/innodb/innodb_log_file’,’wait/io/file/sql/binlog’) and MAX_TIMER_WAIT>200*1000000000;