在业务高峰的时候,如何保证数据的可靠性
在之前说了WAL机制,得到的结论为只要redo log和binlog保证持久化到磁盘,就能保证数据能够恢复,那么,具体的写入流程是怎么样的呢
在事务执行的过程中,一个事务的binlog必须具有原子性的,也就是不可拆分的,不论这个事务多么大,也要一次写入
设计了binlog cache缓存机制
首先写入了日志到binlog cache,事务提交的时候,然后将binlog cache 写到binlog文件中
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内binlog cahce所占内存的大小,如果超过了这个参数规定的大小,就必须存到磁盘中
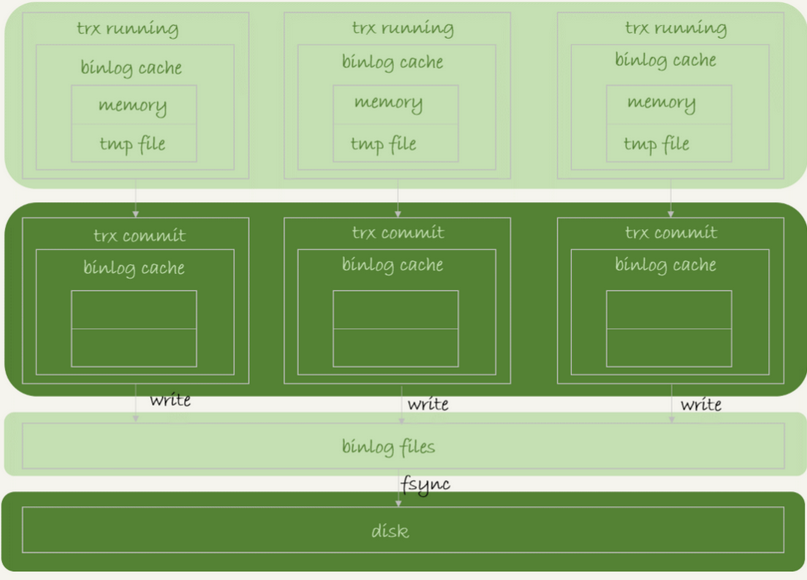
每个线程都有自己的binlog cache 但是共用同一份binlog文件
每个事务将自身写write,但是并没有持久化到磁盘中
然后到了fsync后,才将数据持久化到磁盘中去,只有fsync才算IOPS
何时write,何时fysnc呢
是由参数sync_binlog控制的
sync_binlog =0的时候,每次提交事务值write,并不fsync
sync_binlog =1的时候,每次提交事务都会fysnc
sync_binlog =N N>1时候,表示每N次提交进行一次fsync
一般来说,就是讲sync_binlog设置为100-1000中的某一个数值,但是如果主机发生异常重启,会丢失最近N事务的binlog日志
redo log的写入机制
首先,已知redo log buffer机制
同样redo log buffer也并不是每次写入事务都会持久到磁盘中
redo log buffer中的日志在事务没有提交的时候,也可能触发某些情况而持久到磁盘中
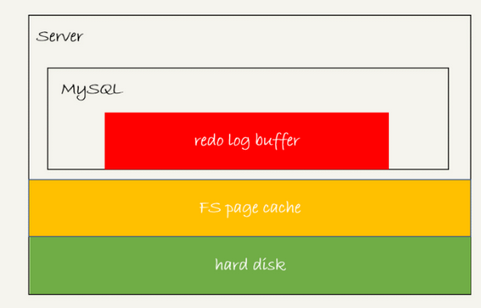
1.存在redo log buffer中,也就是内存中
2.写入到磁盘中,也就是在文件中的page cahce中,但是没有持久化和 binlog一样 只是write,没有fsync
3.持久化到磁盘中,也就是hard disk中
最关键的就是进行正式的刷盘
对于这一步的刷盘,有几个相关的设置
1.innoDB有一个后台线程,每隔一秒,就会把redo log buffer中的日志,调用write写到文件中的page cache,然后调用fsync持久化到磁盘中
2.redo log buffer中占有的空间,即将达到innodb_log_buffer_size中的有一半的时候,后台线程会主动写盘,但是只是写入到了page cache中,并没有调用fsync
3.设置innodb_flush_log_at_trx_commit,设置为几,也就是要在几次事务提交后,就持久化到磁盘中,然后加入事务A已经被保存了一半的事务信息,事务B提交了,顺便就将事务A保存了一半的信息刷入库中了
时序上redo log 先perpare,在写binlog,再把redolog commit
将innodb_flush_log_at_trx_commit设置为1,那么redo log 在prepare阶段就持久化一次,
我们通常说的双1配置,指的就是 sync_binlog和innodb_flush_log_at_trx_commit都设置为1,一个事务完整提交之前,就需要等待两个刷盘,一次是redo log,一次是binlog
但是如果每次都需要刷两次磁盘的话,那么磁盘能力有这么强大吗
这就是MySql带来的组提交(group commit)机制
日志逻辑具有的一个序列号,LSN,用于对应redo log的一个个写入点,LSN是单调递增,对应redo log的一个个写入点,每一个写入长度为length的redo log,LSN的值就会加上length
也就是如下面的流程
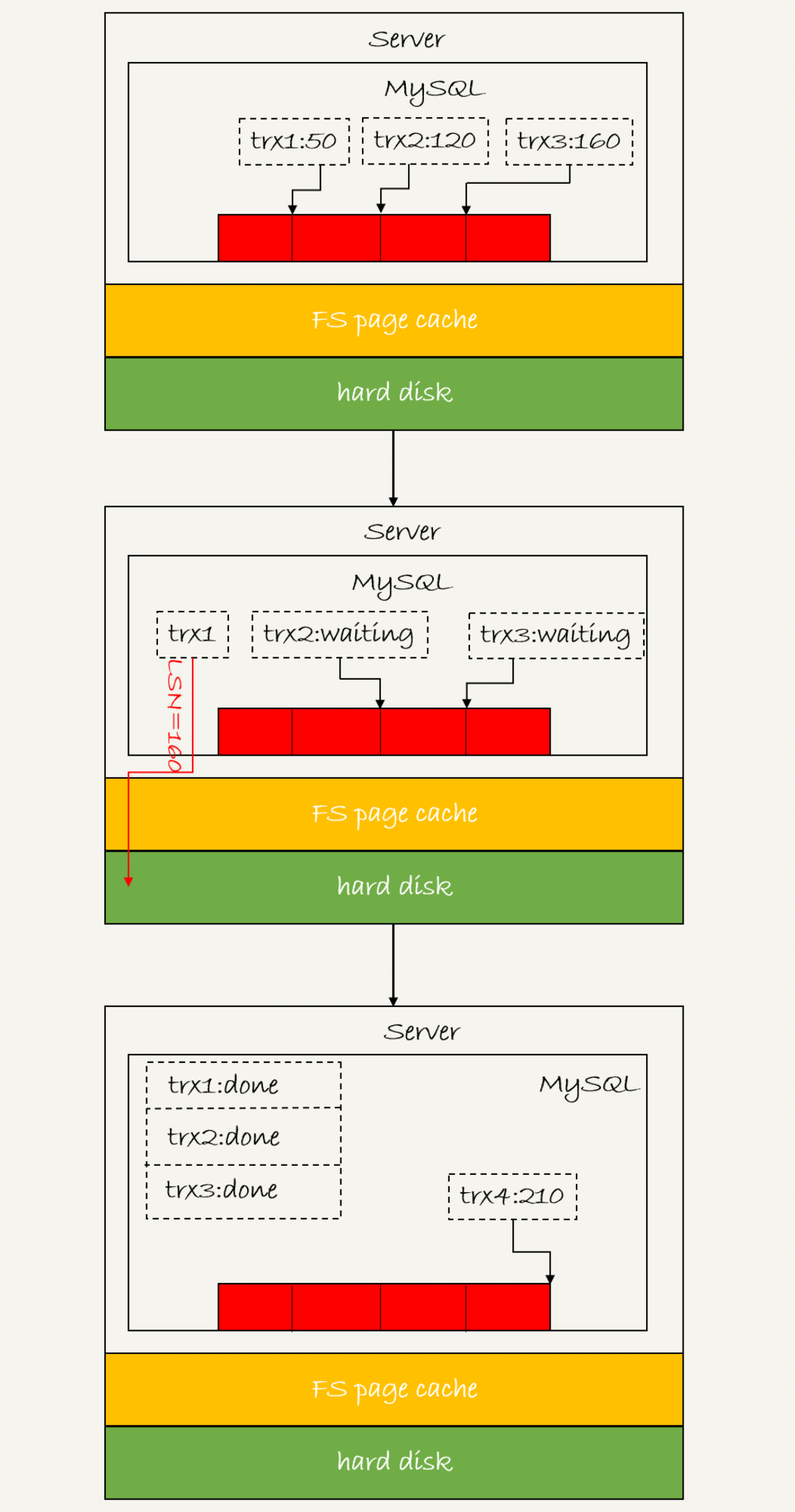
上述一次性提交的时候,LSN小于等于160的redo log,都会被redo log都会被持久化到磁盘中
一次性将所有等待的事务都返回了
第一个事务写完redo log buffer后,这个组提交越晚,组员越多,节省IOPS的效果越好
故,二阶段的实际提交就是
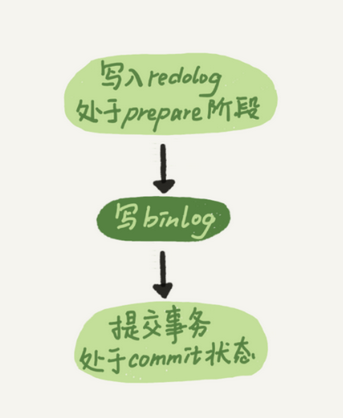
这个两阶段提交的实际提交方式就是
binlog从binglog cache中写入磁盘中的binlog 文件中,然后调用fysnc 持久化
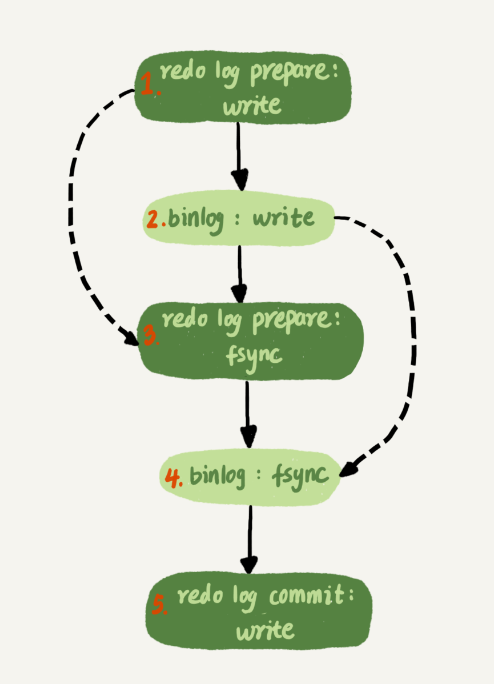
实际上的两阶段提交流程就是如上,
那么可以总结得出,write 和 fsync的,间隔时间越长,越能节省IOPS
但是binlog fysnc执行的很快,所以binlog的组提交的效果一直不是那么好,可以通过设置binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count来实现
1.binlog_group_commit_sync_delay表示了延迟多少微秒后才调用fsync
2.binlog_group_commit_sync_no_delay_count表示了累计多少次后才会调用fsync
这是一个或的关系,只要有一个满足了条件就会调用fsync
WAL配合顺序写和组提交机制,降低了IOPS的消耗
如果出现了磁盘刷盘的瓶颈,解决方案有三种
1.设置binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count来减少写盘次数
2,将sync_binlog设置大于1的值,但是掉电会丢binlog日志
3.将innodb_flush_log_at_trx_commit设置为2两次提交后,但是掉电后也会丢数据
那么有些问题可以迎刃而解了
1.执行了update的语句,为何去看ibd文件内容,没有改变呢
就可能只是写入到了内存中,还没有write到磁盘中
2.binlog cache中每个线程自己维护,redo log buffer是全局共用的
binlog是不能被打断的,redo log buffer则可不一样
一般来说,也是将数据库设置为双一设置
在什么时候设置为非双一
业务高峰期,如果有预支的高峰期,会改为非双一
备库延迟,让备库赶上主库
备库恢复主库副本
批量导入数据的时候