首先从一个真正的表来看这个事情,如果有一个表为用户信息统计表,需要查询城市为杭州 并且按照姓名排序返回前1000个人的姓名和年龄
sql语句简化为如下
select city,name,age from t where city =’杭州’ order by name limit 1000;
内部执行流程为:
首先是explain来查看语句的执行流程

根据Extra 上的执行来看
使用了Using filesort 表示需要排序
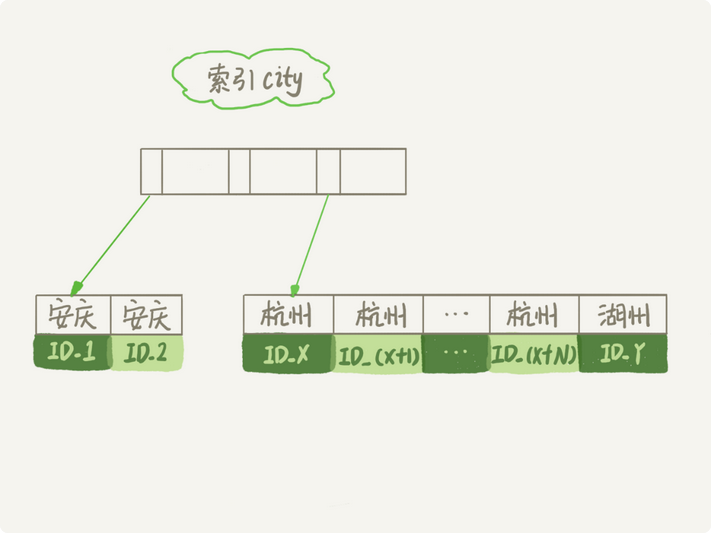
首先从索引city上查找出第一个杭州的主键,然后加入sort_buffer中,这个是Mysql为每一个线程分配的内存用来排序
然后从每个主键上取出name,city,age三个字段的值,存入sort_buffer中
重复这个流程,在取到不满足city索引的值的时候,进行对sort_buffer中的数据按照字段name做快速排序
排序完成后取1000行返回给客户端
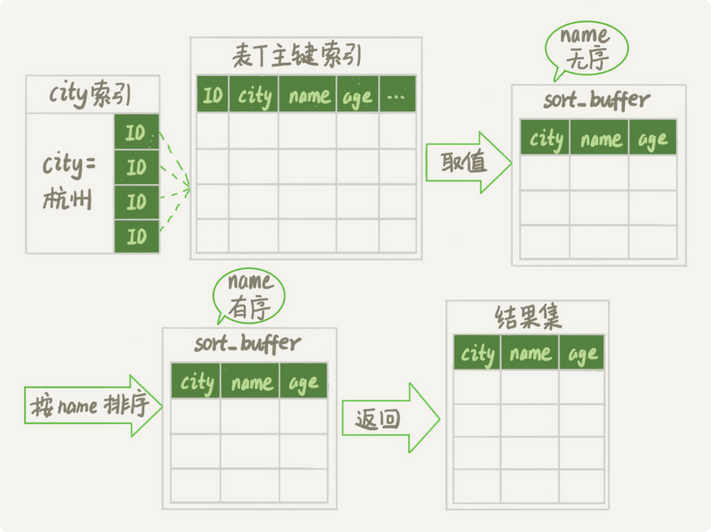
上述是整体的流程
但是每个线程的sort_buffer都是具有一定大小的,这个大小由sort_buffer_size决定,如果排序的数据量小于 sort_buffer_size
排序就在内存中完成,如果排序的数据量大于 sort_buffer_size,就需要磁盘的临时文件辅助排序
对于是否使用了临时文件
| /* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace=’enabled=on’; /* @a 保存 Innodb_rows_read 的初始值 */ select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = ‘Innodb_rows_read’; /* 执行语句 */ select city, name,age from t where city=’杭州’ order by name limit 1000; /* 查看 OPTIMIZER_TRACE 输出 */ SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G /* @b 保存 Innodb_rows_read 的当前值 */ select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = ‘Innodb_rows_read’; /* 计算 Innodb_rows_read 差值 */ select @b-@a; |
也可以从 number_of_tmp_files来看到是否使用了临时文件
从上述的流程可以看出有一个问题,就是会将原表的数据取出来放到一个sort_buffer中,一是占用内存空间,二是如果sort_buffer比较小,会分为多个临时文件执行,排序性能能并不高
MySql提供了额外的算法,启用其的方式为
利用多次回表,减少内存占用
利用SET max_length_for_sort_data = 16;来让mysql认为数据过长
新的算法中,只放入了sort_buffer的字段,只有需要排序的字段,这样就因为不满足查找的要求而必须要回表
整体的流程如下
1.初始化sort_buffer 放入name和id
2,从索引city中取出满足id为杭州的主键id
3.从主键索引中取出name 和 id
4.执行23 直到条件不满足city = ‘杭州’为止
5.按照name字段进行排序
6.再按照排序后的结果,从主键id取出前1000行,然后取出需要的字段返回客户端
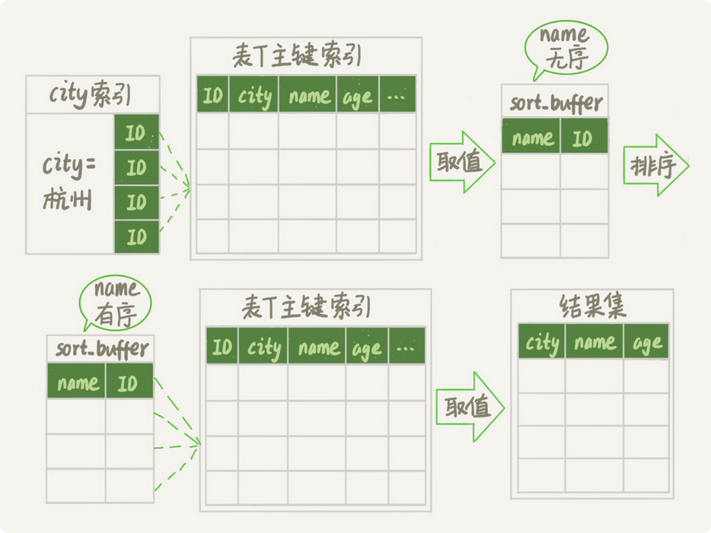
这就是row id排序
两者进行一下比较
为何采用了rowid,是因为MySQL担心排序内存比较小,会影响排序效率,采用了rowid排序算法
可以去排序更多的行
然后在Mysql认为内存足够的时候,会选择全字段排序,然后将字段都放到了sort_buffer中,减少了一次的回表操作
然后,在MySql中,因为row id需要多回表,所以并不会优先选择
最后,为了一劳永逸
如果从city中取出来后,name已经是有序的,那么就不需要排序了吧
这就可以,在t表上创建一个city和name的联合索引
alter table t add index city_user_age(city,name);
这就满足了从city索引中取出了满足杭州的city,name就是有序的
整体的查询过程完成后
1.从联合索引中找到第一个满足city的主键id
2.从主键id索引中取出整行,取出所需要的三个字段的值,然后直接返回
3.依次循环,知道查完1000行,或者city条件不被满足了
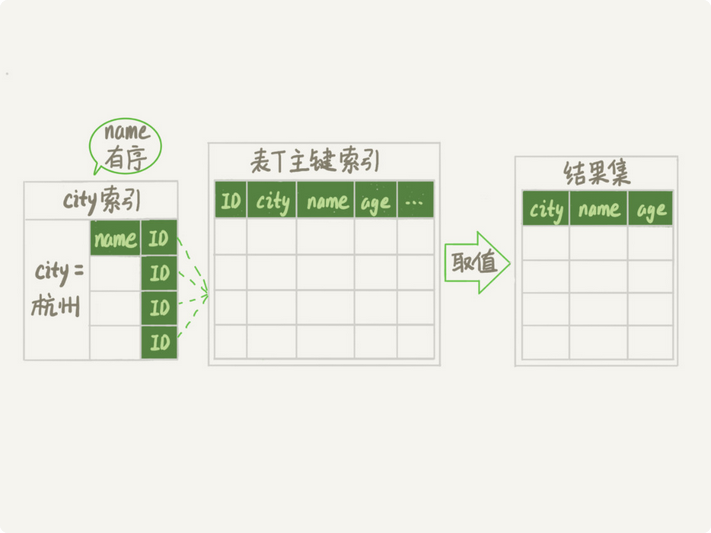
整个流程不需要临时表,也不需要排序

上面的索引中Extra中使用了Using index,表示使用了覆盖索引,性能更快
对于排序的选择,必须综合并且均衡的去选择排序方式