Java的执行引擎在执行Java代码的时有解释执行和编译执行
那么首先说下如何使解释执行的
Java语言在创建初期,一会被人称为解释执行的语言,但是再后来发展,为了优化性能,也推出了可以直接生成本地代码的编译器,入GCJ,于是直接称呼为解释执行就不太合适了
但现在来说,机器没有智能到一定程度,都需要从程序代码转换为虚拟机能够执行的指令集,具体的编译过程可以参考如下的图
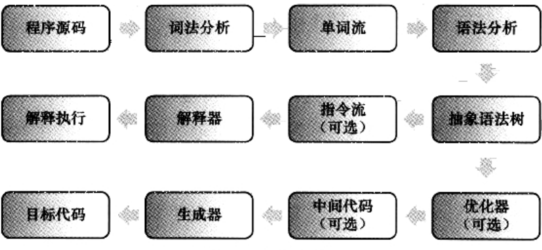
中间的那条线是Java的解释执行的流程,下面的线则是传统编译原理中程序代码到目标机器代码的生成过程
最上面的一条线,则是大家通用的解析过程
在Java语言,就是先对程序源码进行词法上的分析和语法的分析处理,将源码转换为抽象语法树,这些是在Java虚拟机之外执行的,最后解释器在虚拟机内部执行的
但像是C语言,就是选择的最下面一条道路,并且将目标代码等都独立在了执行引擎之外趋势线
也可以选择其中一部分的步骤生成一个半独立的编译器,就像是JavaScript
在Java形成抽象语法书之后,需要进行输出为指令流,基本上就是基于栈的指令集架构,当然顺便一提,还是有基于寄存器的指令集的,比如主流PC中依赖CPU寄存器执行的指令集架构
两者区别在于
使用栈的指令集是
使用基于CPU寄存器的指令,可能是
这个指令集的意思为
mov将其初始化为1,然后利用add指令将值加一
基于栈的指令集的最大优点在于可移植,寄存器由硬件直接提供,就怕遇到没有寄存器的硬件,现在可以将不同平台的虚拟机自行决定将一些访问频率非常高的数据放在寄存器中加速性能
现在来说使用栈的指令唯一的缺点就是速度会慢一点,因为完成相同功能所需要的的指令数量比寄存器所需要的多,因为出栈和入栈都需要相对应的指令

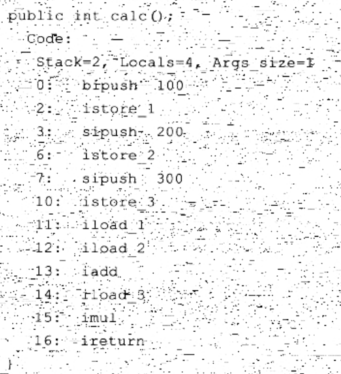
下面拿着上面的代码解释下解释器的执行流程
上面的指令在编译之后产生的字节码指令如下
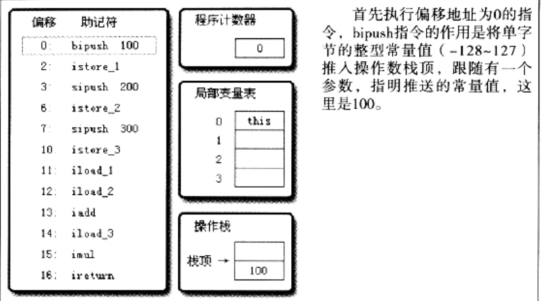
压入了100的常量值
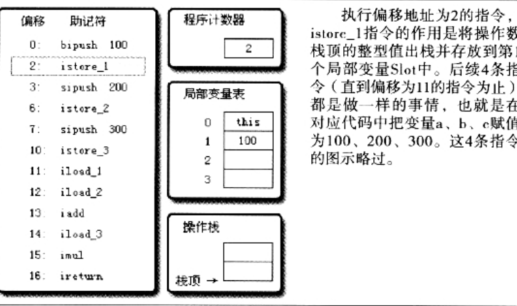
分别压入了100 200 300,并在局部变量表中声明了这几个变量
接下来,首先是a+b,那么会将a进行出栈操作
然后对b进行出栈
操作栈里填入了200和100
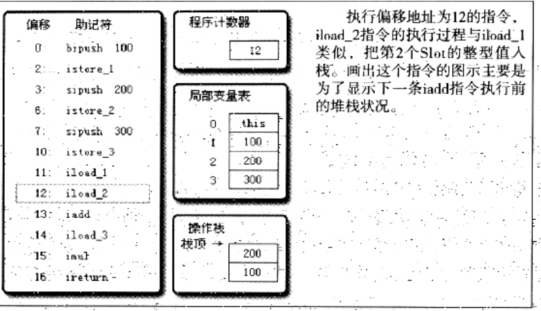
进行了add操作

然后进行了乘法计算
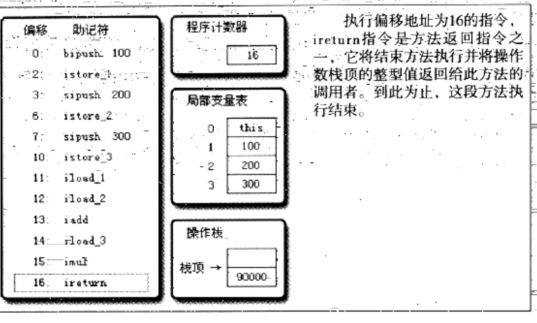
最后进行了返回工作
完成整个代码的执行
当然上面只是简单的代码执行,实际很多情况和上面概念有差距,在HotSpot虚拟机中,很多fast开头的非标准字节码指令就可以提升解释执行性能