我们基于Flink实现一个流计算任务,来看一下流计算的例子,说明一下流计算框架的实现原理
流计算,流计算,必然是对于实时产生的数据进行实时的统计分析,非常适用于流计算
上面中,有两个实时,一个是数据是实时产生的,以及统计分析的过程是实时进行的,对于这种场景,可以考虑使用流计算框架
流计算框架一般内置了很多算子,直接使用即可,比如TimeWindow,GroupBy,Sum,Count
非常适合做实时的统计分析
比如每分钟统计不同IP的请求次数
统计下单量和浏览量
那么我们写一个在Flink中执行的Job
Flink实现一个统计任务,NGINX的access,log,每5分钟按照IP地址统计WEB请求的次数,统计任务是一个典型的按照Key分类汇总的统计任务,汇总还是按照一定的周期来进行进行的,那么我们就按照这个例子来实现
我们假设log的发送服务已经存在,我们不关心,给出的数据格式如下
| $nc localhost 9999
14:37:11 192.168.1.3 14:37:11 192.168.1.2 14:37:12 192.168.1.4 14:37:14 192.168.1.2 14:37:14 192.168.1.4 14:37:14 192.168.1.3 … |
那么我们使用Scala和Flink来实现这个流计算任务
| object SocketWindowIpCount {
def main(args: Array[String]) : Unit = { // 获取运行时环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 按照EventTime来统计 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 设置并行度 env.setParallelism(4) // 定义输入:从Socket端口中获取数据输入 val hostname: String = “localhost” val port: Int = 9999 // Task 1 val input: DataStream[String] = env.socketTextStream(hostname, port, ‘\n’) // 数据转换:将非结构化的以空格分隔的文本转成结构化数据IpAndCount // Task 2 input .map { line => line.split(“\\s”) } .map { wordArray => IpAndCount(new SimpleDateFormat(“HH:mm:ss”).parse(wordArray(0)), wordArray(1), 1) } // 计算:每5秒钟按照ip对count求和 .assignAscendingTimestamps(_.date.getTime) // 告诉Flink时间从哪个字段中获取 .keyBy(“ip”) // 按照ip地址统计 // Task 3 .window(TumblingEventTimeWindows.of(Time.seconds(5))) // 每5秒钟统计一次 .sum(“count”) // 对count字段求和 // 输出:转换格式,打印到控制台上 .map { aggData => new SimpleDateFormat(“HH:mm:ss”).format(aggData.date) + ” ” + aggData.ip + ” ” + aggData.count } .print() env.execute(“Socket Window IpCount”) } /** 中间数据结构 */ case class IpAndCount(date: Date, ip: String, count: Long) } |
在上面代码中,我们首先获取了流计算的运行时环境,就是这个env对象,对env对象做一些初始设置
代码中,我们设置了socketTextStream(hostname,port,’\n’)代表了主机名,端口号,分隔符
因为我们的数据流是DataStream[String] 代表了数据流,其中每条数据都是string
会告诉Flink,数据流是一个Socket服务
然后,我们尝试做一些数据转换,将字符串转换为结构化的数据IpAndCount
然后是计算部分,分别是
1,时间从date字段获取
2.按照IP进行汇总
3.每5秒一次
4.对count字段求和
定义一个计算任务的代码并不困难,于是Flink,Spark无论哪个流计算任务,定义一个流计算的过程就是,定义输入,计算逻辑,定义输出
数据如何来,如何计算,结果到哪里
而且在流计算中,我们上面的书写实际上只相当于书写了一段sql,实际上Flink会将上面的声明,利用自己的引擎,转换为一个额外的jar包,也就是Flink在解析了之后动态生成的代码
然后Job的执行流程
Flink在运行时的架构图如下
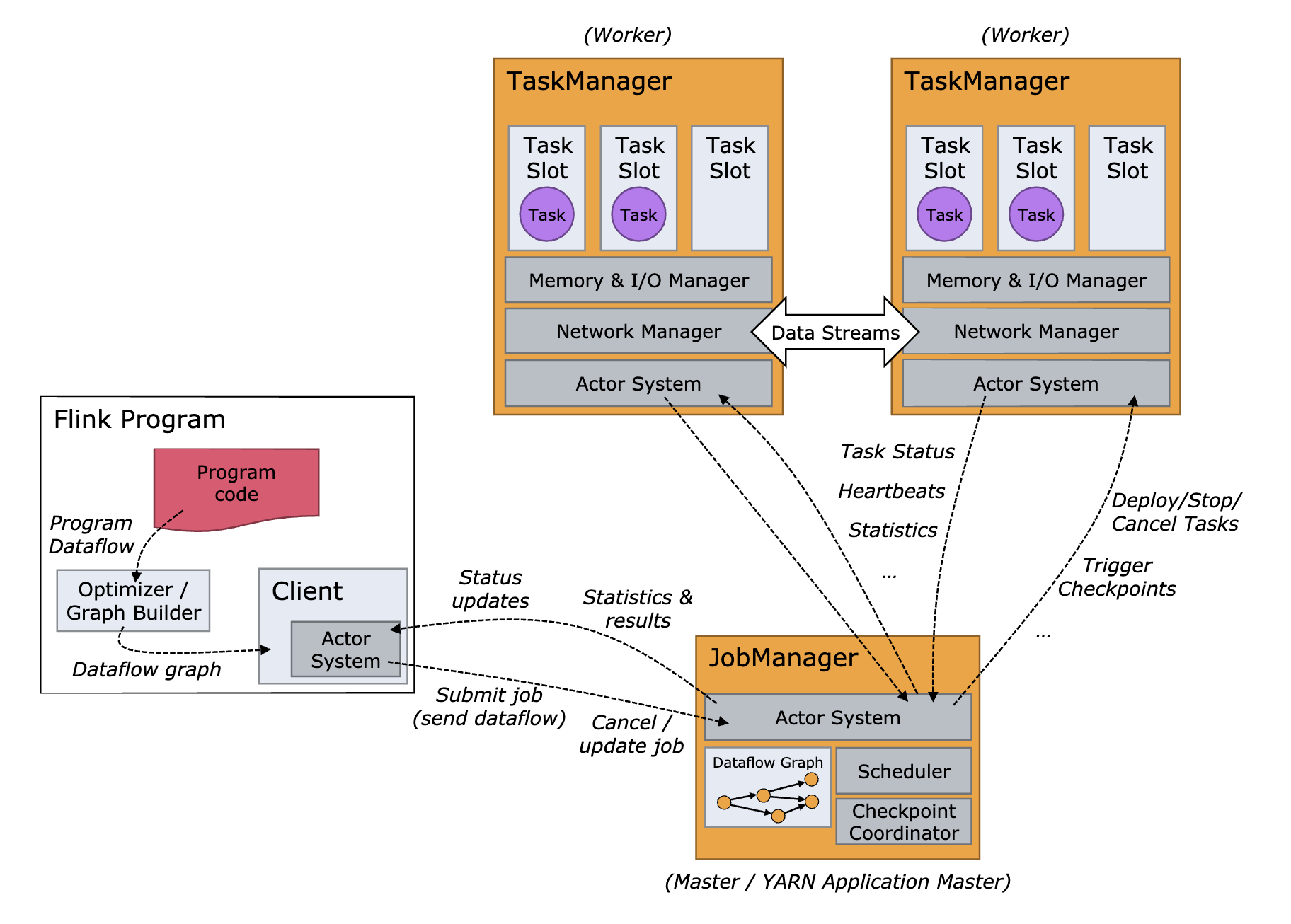
我们将Flink项目中的节点分为两种
集群中大部分的节点都是TaskManager节点,每个节点都是一个java进程,负责执行计算任务,另外就是JobManager节点,负责管理和协调所有的计算节点和计算任务,客户端和Web控制台也是通过JobManager来提交和管理任务的
Flink客户端提交任务给JobManager之后,任务会被Flink解析,生成一个有向无环图,DAG
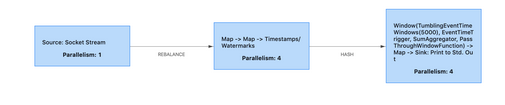
图上每个点都是一个Task,每个Task都是一个执行单元,运行在某个TaskManager
就好比电流流过电路图,或者说一个责任链,数据从source task进入,一个节点一个节点的经过,每个Task进行了一部分的操作,直到最后一个Sink Task流出DAG,完成了流计算
对应的图中Task,我们一次来说明,第一个Task我们连接了日志服务接收日志数据
第二个Task进行了两个map的变化,将文本数据转换为了结构化的数据,并添加了水印
第三个Task执行了剩余的计算任务,按照时间进行汇总,打印到控制台上
然后在Flink集群中执行,每个Task都标注了一个Parallelism并行度,这个并行度说明了可以被多少个线程并发先执行,第一个是1,说明只有一个拉取的Task,第二个是4,说明Task在被Flink运行的时候有4个线程都在执行这个Task,每个线程都是一个SubTask 子任务,如果Flink集群节点数足够多,4个SubTask可能运行在不同的TaskManager节点上
然后我们第二第三个Task之间的箭头,上面标注的是HASH,第二个Task的处理逻辑最后会按照IP进行一个HASH分流,第三个Task因为并行度也是4,在统计的时候,需要将相同IP的数据发送到一个SubTask上,这样每个SubTask中,每个数据,只要在对应的IP汇总记录上累加就可以了
最后第三个Task中,4个SubTask进行数据汇总,每个SubTask负责汇总一部分你的数据,最终打印到控制台上,有4个线程并行打印
那么我们
| public class ExactlyOnceIpCount {
public static void main(String[] args) throws Exception { // 设置输入和输出 FlinkKafkaConsumer011<IpAndCount> sourceConsumer = setupSource(); FlinkKafkaProducer011<String> sinkProducer = setupSink(); // 设置运行时环境 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 按照EventTime来统计 env.enableCheckpointing(5000); // 每5秒保存一次CheckPoint // 设置CheckPoint CheckpointConfig config = env.getCheckpointConfig(); config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 设置CheckPoint模式为EXACTLY_ONCE config.enableExternalizedCheckpoints( CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 取消任务时保留CheckPoint config.setPreferCheckpointForRecovery(true); // 启动时从CheckPoint恢复任务 // 设置CheckPoint的StateBackend,在这里CheckPoint保存在本地临时目录中。 // 只适合单节点做实验,在生产环境应该使用分布式文件系统,例如HDFS。 File tmpDirFile = new File(System.getProperty(“java.io.tmpdir”)); env.setStateBackend((StateBackend) new FsStateBackend(tmpDirFile.toURI().toURL().toString())); // 设置故障恢复策略:任务失败的时候自动每隔10秒重启,一共尝试重启3次 env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // number of restart attempts 10000 // delay )); // 定义输入:从Kafka中获取数据 DataStream<IpAndCount> input = env .addSource(sourceConsumer); // 计算:每5秒钟按照ip对count求和 DataStream<IpAndCount> output = input .keyBy(IpAndCount::getIp) // 按照ip地址统计 .window(TumblingEventTimeWindows.of(Time.seconds(5))) // 每5秒钟统计一次 .allowedLateness(Time.seconds(5)) .sum(“count”); // 对count字段求和 // 输出到kafka topic output.map(IpAndCount::toString).addSink(sinkProducer); // execute program env.execute(“Exactly-once IpCount”); } } |
但是对于流计算来说,因为本质上,在集群中流动的数据没有被持久化,所以可能因为节点故障而丢失数据,如何办呢?就是直接重启整个计算任务,并且找到没有计算的数据,重新计算
这就要求在消费完成数据之前,数据也不会消失
而Flink是一个无状态的计算节点,这就需要消息提供方配合处理
而Kafka就提供了这个确认消费的机制,也就是Exactly Once语义,
Flink内部如何记录任务执行的状态呢?
这里用了CheckPoint机制来保证了计算任务的快照,这个快照包含了两个重要数据
1.计算任务的状态,计算任务中,子任务在计算过程中保存的临时数据,就好比上面IP统计了一半的数据
2,数据源的位置,记录已经计算了哪些数据,如果数据源是Kafka的主题,这个位置信息就是Kafka的消费位置
利用CheckPoint,就可以在任务计算失败的时候,从最近的一个CheckPoint恢复任务,具体的做法就是,每个子任务都从CheckPoint中读取并恢复自己的状态,然后开始继续消费数据
从而保证严丝合缝的继续任务
CheckPoint的具体实现,则是如下的流动流程
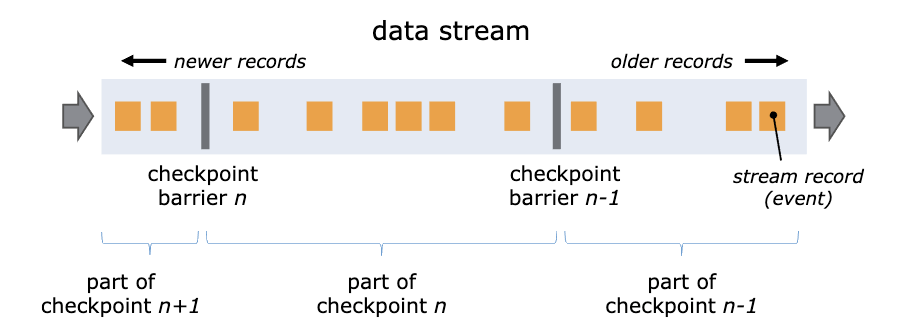
Flink在数据流中插入一个Barrier来确保CheckPoint中的位置和状态完全的对应
对于Barrier 栅栏,则是一个这样的概念,由Flink生成,在数据进入计算集群的时候插入数据流
数据流被Barrier分成多段,Barrier在流经每个计算节点的时候,就会触发这个节点在CheckPoint中保存本节点的状态
当一个Barrier流经所有的计算节点后,一个CheckPoint就保存完成了
这样,每个节点都保存了Barrier流经时候的状态
然后配合Kafka的Exactly Once机制,实现流计算的任务状态保存
Kafka的状态是利用的事务和幂等性来实现的
一个事务内的所有消息,要么全部成功投递,要么不投递
利用这个机制,每次创建一个CheckPoint的时候,就会同时开启一个Kafka的事务,完成CheckPoint的时候提交Kafka的事务,计算任务重启的时候,Flink中计算任务就会恢复到上一个CehckPoint,没有完成的CheckPoint和未提交的事务中的消息就会被丢弃,完成了端到端的Exactly Once
至于如何保证同时完成CheckPoint和提交Kafka事务的一致性,则是利用了二阶段提交来进行处理
利用这个想法,我们改造一下上面的请求
我们将数据来源替换为Kafka的ip_count_source主题,结果保存在ip_count_sink主题中

Flink已经和Kafka做好了集成,提供了Kafka Connector模块,可以作为数据源从Kafka中消费数据,也可以作为Kafak的Producer发送消息
并且实现了Exactly Once的全流程
| public class ExactlyOnceIpCount {
public static void main(String[] args) throws Exception { // 设置输入和输出 FlinkKafkaConsumer011<IpAndCount> sourceConsumer = setupSource(); FlinkKafkaProducer011<String> sinkProducer = setupSink(); // 设置运行时环境 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 按照EventTime来统计 env.enableCheckpointing(5000); // 每5秒保存一次CheckPoint // 设置CheckPoint CheckpointConfig config = env.getCheckpointConfig(); config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 设置CheckPoint模式为EXACTLY_ONCE config.enableExternalizedCheckpoints( CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 取消任务时保留CheckPoint config.setPreferCheckpointForRecovery(true); // 启动时从CheckPoint恢复任务 // 设置CheckPoint的StateBackend,在这里CheckPoint保存在本地临时目录中。 // 只适合单节点做实验,在生产环境应该使用分布式文件系统,例如HDFS。 File tmpDirFile = new File(System.getProperty(“java.io.tmpdir”)); env.setStateBackend((StateBackend) new FsStateBackend(tmpDirFile.toURI().toURL().toString())); // 设置故障恢复策略:任务失败的时候自动每隔10秒重启,一共尝试重启3次 env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // number of restart attempts 10000 // delay )); // 定义输入:从Kafka中获取数据 DataStream<IpAndCount> input = env .addSource(sourceConsumer); // 计算:每5秒钟按照ip对count求和 DataStream<IpAndCount> output = input .keyBy(IpAndCount::getIp) // 按照ip地址统计 .window(TumblingEventTimeWindows.of(Time.seconds(5))) // 每5秒钟统计一次 .allowedLateness(Time.seconds(5)) .sum(“count”); // 对count字段求和 // 输出到kafka topic output.map(IpAndCount::toString).addSink(sinkProducer); // execute program env.execute(“Exactly-once IpCount”); } } |
主要的修改在于,我们设置开启了CheckPoint
设置了CheckPoint的保存地址,一般在HDFS中,不过我们将其保存在本地的临时目录上
还配置了Job为自动重启,当节点发生故障的时候,Flink会自动重启Job然后从最近一次CheckPoint恢复
而且Kafak主题ip_count_sink中读取消息的时候,需要配置为isolation.level=read_committed
Kafka的默认消费级别,是可以消费未提交事务的消息